kevinjmh commented on a change in pull request #3780:
URL: https://github.com/apache/carbondata/pull/3780#discussion_r432950129
##########
File path: integration/spark/src/main/scala/org/apache/spark/sql/CarbonEnv.scala
##########
@@ -328,7 +328,7 @@ object CarbonEnv {
if ((!EnvHelper.isLegacy(sparkSession)) &&
(dbName.equals("default") || databaseLocation.endsWith(".db"))) {
val carbonStorePath = CarbonProperties.getStorePath()
- val hiveStorePath = sparkSession.conf.get("spark.sql.warehouse.dir",
carbonStorePath)
+ val hiveStorePath = sparkSession.conf.get("spark.sql.warehouse.dir")
// if carbon.store does not point to spark.sql.warehouse.dir then follow
the old table path
// format
if (carbonStorePath != null && !hiveStorePath.equals(carbonStorePath)) {
Review comment:
the problem of that PR need checking of the cluster setting. I haven't
met the case local path is added hdfs prefix unconsciously.
In my case, a vanilla apache version of spark on yarn, the default warehouse
location is under the local working directory where the thrift server launch.
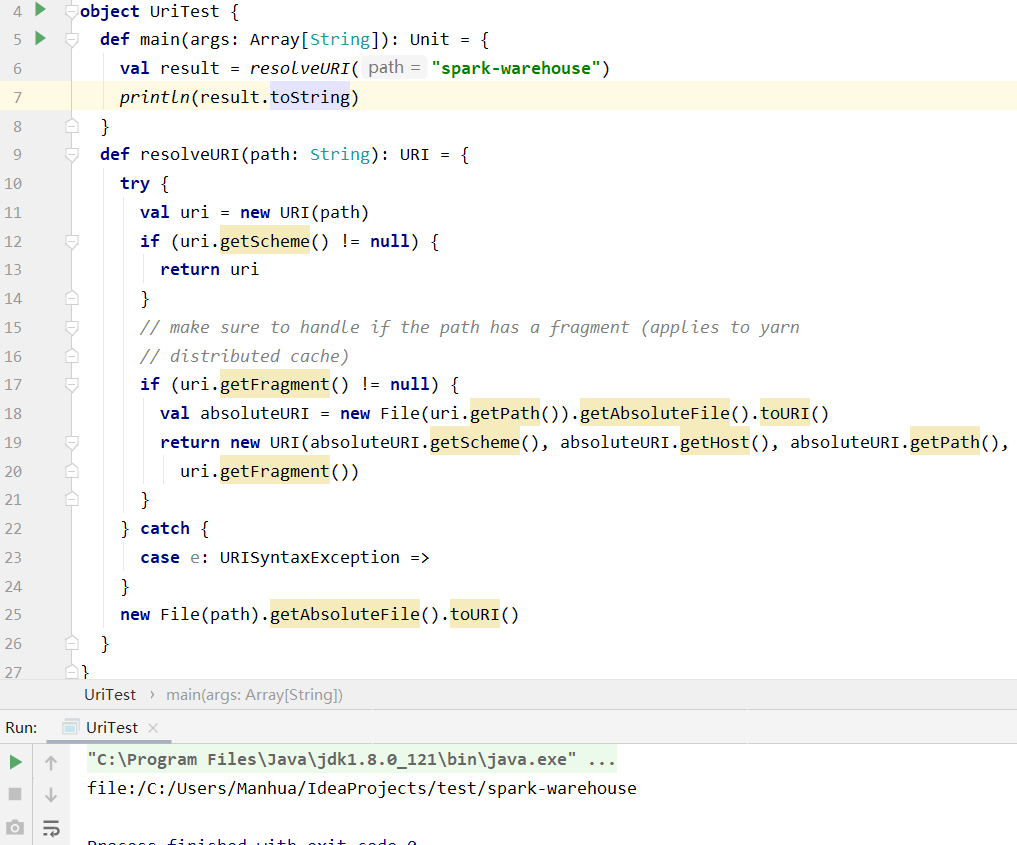
If you check spark code, the default value of `spark.sql.warehouse.dir`
barely comes from Java URI implementation.
https://github.com/apache/spark/blob/6c792a79c10e7b01bd040ef14c848a2a2378e28c/sql/catalyst/src/main/scala/org/apache/spark/sql/internal/StaticSQLConf.scala#L33-L37
https://github.com/apache/spark/blob/47dc332258bec20c460f666de50d9a8c5c0fbc0a/core/src/main/scala/org/apache/spark/util/Utils.scala#L1976
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
{kind=link}