[
https://issues.apache.org/jira/browse/LANG-1406?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16578129#comment-16578129
]
ASF GitHub Bot commented on LANG-1406:
--------------------------------------
Github user HiuKwok commented on a diff in the pull request:
https://github.com/apache/commons-lang/pull/340#discussion_r209574053
--- Diff: src/main/java/org/apache/commons/lang3/StringUtils.java ---
@@ -5596,8 +5596,8 @@ private static String replace(final String text,
String searchString, final Stri
}
String searchText = text;
if (ignoreCase) {
- searchText = text.toLowerCase();
- searchString = searchString.toLowerCase();
+ searchText = text.toUpperCase();
+ searchString = searchString.toUpperCase();
--- End diff --
Hi @kinow, yes you are right after I did try to come up with a draft java
main to generate all || most unicode in string and compare it's length between
original, toLowerCase() and to UpperCase().
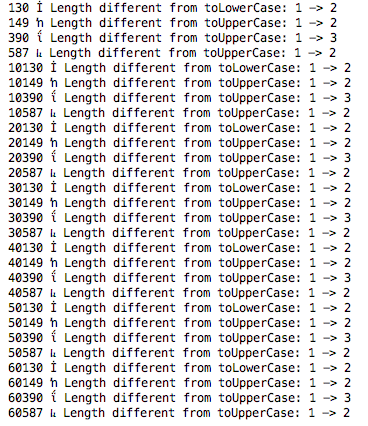
It's seem like no matter which one we pick (toLowerCase || toUpperCase), it
would still tend to come up with a incorrect length.
Just a quick question what you mean by remove the ```length( )``` mean?
Would you mind to specify more on that?
Thanks,
> StringIndexOutOfBoundsException in StringUtils.replaceIgnoreCase
> ----------------------------------------------------------------
>
> Key: LANG-1406
> URL: https://issues.apache.org/jira/browse/LANG-1406
> Project: Commons Lang
> Issue Type: Bug
> Components: lang.*
> Reporter: Michael Ryan
> Priority: Major
>
> STEPS TO REPRODUCE:
> {code}
> StringUtils.replaceIgnoreCase("\u0130x", "x", "")
> {code}
> EXPECTED: "\u0130" is returned.
> ACTUAL: StringIndexOutOfBoundsException
> This happens because the replace method is assuming that text.length() ==
> text.toLowerCase().length(), which is not true for certain characters.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
{kind=link}