Github user HiuKwok commented on the issue:
https://github.com/apache/commons-lang/pull/340
To whom who interested in this issue, here is some founding that I
discovered throughout this month of issue solving.
Problem:
- The exception would happened when any String object passed in with
unicode character. In order to achieve ignore case replacement, the internal
logic would first transform both `text` and `SearchString` to lowerCase( ) for
comparaition.
- However if anyone passion enough to digger deeper into the src logic of
`.toLowerCase( )`. Certain unicode character would be denormalized. In this way
the result String length would tend to longer than original length(). Example
like:
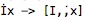
So making use of the transformed String, Out bound exception would happen
when trying to access the index that doesn't access at all (3 in this case vs 2
in length before lowerCase).
Flow:
- So the first thought into my mind is, why dun just normalize both `text`
and `searchString` before performing ignore case comparation? In this way the
String length would always stay consistence no matter `toLowerCase( )` or
`toUpperCase( )` 3 -> 3. However the another problem would emerged, as you may
noticed, while the String mentioned above denormalize, it would turn into a
UpperCase I and a dot sign.
- But what happen if the search pattern emerge into searchText in decompose
form. In this case let say I am trying to match a upper [I]. Then mismatch
would happen and this is certain not the desire behavior of this method I
believe.
BTW I Drafted a simple main method to demonstrate how mismatch would happen
in here.
https://github.com/HiuKwok/commons-lang/blob/master/src/main/java/com/hiukwok/test.java#L10-L20
---
{kind=link}