[
https://issues.apache.org/jira/browse/FLINK-7465?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16143342#comment-16143342
]
sunjincheng commented on FLINK-7465:
------------------------------------
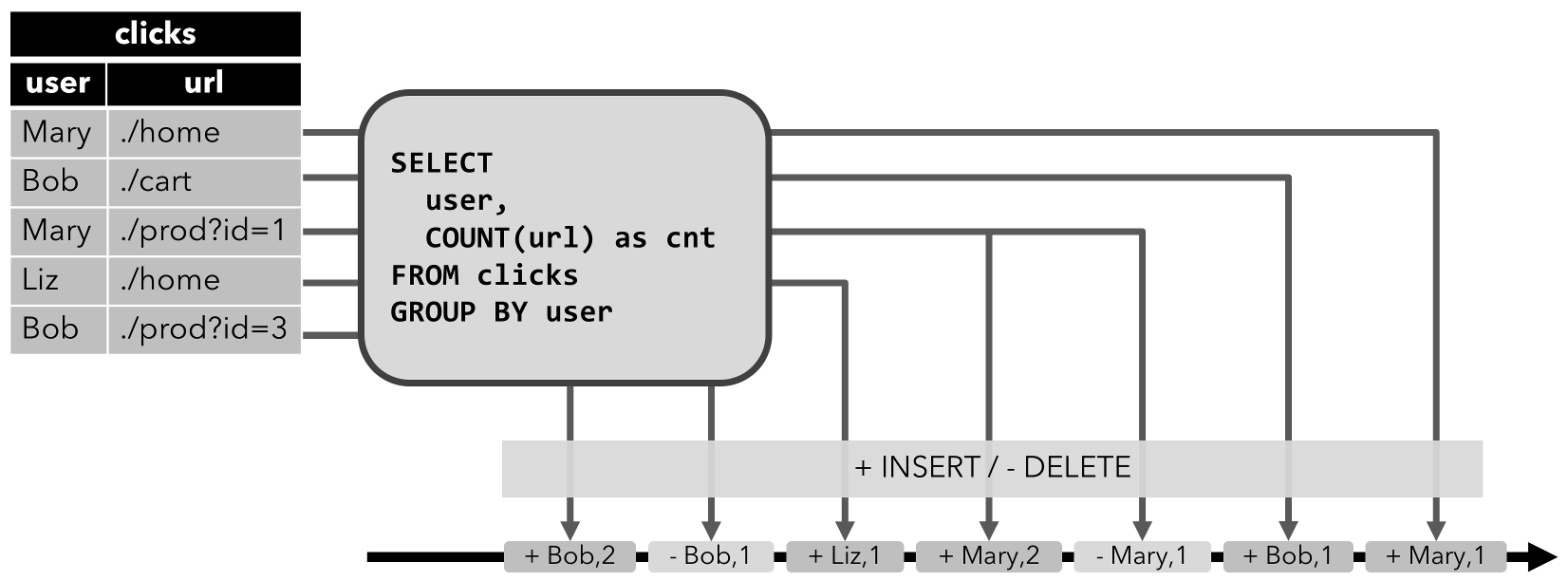
Hi [~jparkie]When we deal with a [Dynamic
table|http://flink.apache.org/news/2017/04/04/dynamic-tables.html] retract
record will generate when record is updated. [Retract
stream|https://ci.apache.org/projects/flink/flink-docs-release-1.4/dev/table/streaming.html]
contains retract record. i.e.: A retract stream is a stream with two types of
messages, add messages and retract messages. A dynamic table is converted into
an retract stream by encoding an INSERT change as add message, a DELETE change
as retract message, and an UPDATE change as a retract message for the updated
(previous) row and an add message for the updating (new) row. The following
figure visualizes the conversion of a dynamic table into a retract stream.
!https://ci.apache.org/projects/flink/flink-docs-release-1.4/fig/table-streaming/undo-redo-mode.png!
So, the core issue of traditional {{HyperLogLog}} is not to support delete. To
be honest HyperLogLog is (approximately) count the number of distinct
values,maybe we can ignore the retract recode.
> Add build-in BloomFilterCount on TableAPI&SQL
> ---------------------------------------------
>
> Key: FLINK-7465
> URL: https://issues.apache.org/jira/browse/FLINK-7465
> Project: Flink
> Issue Type: Sub-task
> Components: Table API & SQL
> Reporter: sunjincheng
> Assignee: sunjincheng
> Attachments: bloomfilter.png
>
>
> In this JIRA. use BloomFilter to implement counting functions.
> BloomFilter Algorithm description:
> An empty Bloom filter is a bit array of m bits, all set to 0. There must also
> be k different hash functions defined, each of which maps or hashes some set
> element to one of the m array positions, generating a uniform random
> distribution. Typically, k is a constant, much smaller than m, which is
> proportional to the number of elements to be added; the precise choice of k
> and the constant of proportionality of m are determined by the intended false
> positive rate of the filter.
> To add an element, feed it to each of the k hash functions to get k array
> positions. Set the bits at all these positions to 1.
> To query for an element (test whether it is in the set), feed it to each of
> the k hash functions to get k array positions. If any of the bits at these
> positions is 0, the element is definitely not in the set – if it were, then
> all the bits would have been set to 1 when it was inserted. If all are 1,
> then either the element is in the set, or the bits have by chance been set to
> 1 during the insertion of other elements, resulting in a false positive.
> An example of a Bloom filter, representing the set {x, y, z}. The colored
> arrows show the positions in the bit array that each set element is mapped
> to. The element w is not in the set {x, y, z}, because it hashes to one
> bit-array position containing 0. For this figure, m = 18 and k = 3. The
> sketch as follows:
> !bloomfilter.png!
> Reference:
> 1. https://en.wikipedia.org/wiki/Bloom_filter
> 2.
> https://github.com/apache/hive/blob/master/storage-api/src/java/org/apache/hive/common/util/BloomFilter.java
> Hi [~fhueske] [~twalthr] I appreciated if you can give me some advice. :-)
--
This message was sent by Atlassian JIRA
(v6.4.14#64029)
{kind=link}