StephanEwen opened a new pull request #15601:
URL: https://github.com/apache/flink/pull/15601
## This is based on #15557
Only the commits starting from "[FLINK-18071][coordination] (part 2)
OperatorCoordinatorHolder does not implement OperatorCoordinator interface any
more" are new.
## What is the purpose of the change
This is the second PR on the way to fixing [FLINK-21996]. The overall steps
of the fix are:
1. Add a test and did preliminary refactoring (#15557)
2. Fix [FLINK-18071] to make sure target tasks for OperatorEvents are
well-defined (this PR!)
Follow-up PRs:
3. Timeouts on *Acks* for sending `OperatorEvents` trigger a failover for
the receiving subtask. That way the task and the coordinator go to the previous
checkpoint for that subtask (with the event back on the Coordinator).
4. Delay operator coordinator checkpoint completion until all pending
event acks are received or failed. That avoids cases where we completed a
checkpoint despite the fact that an event sent before the checkpoint was lost,
but we haven't detected that, yet. This is necessary on the RPC events (as
opposed to network stack data streams), because the RPC service does not notify
the connection as broken when individual events are lost (unlike the network
stack, where a stream rupture necessarily triggers a failure for the receiving
task).
## The Problem addressed by this PR
The addressed problem is that an `OperatorEvent` send from a coordinator
does not have a well specified target task.
When the event gets sent, it is sent to the task execution that happens to
be running at that time. In some cases (stall in the thread that runs the
coordinator), that might already be the next execution attempt.
The figure below shows that even when the coordinator and scheduler each
handle their actions strictly in order, there is no guarantee what the target
for event sending is.
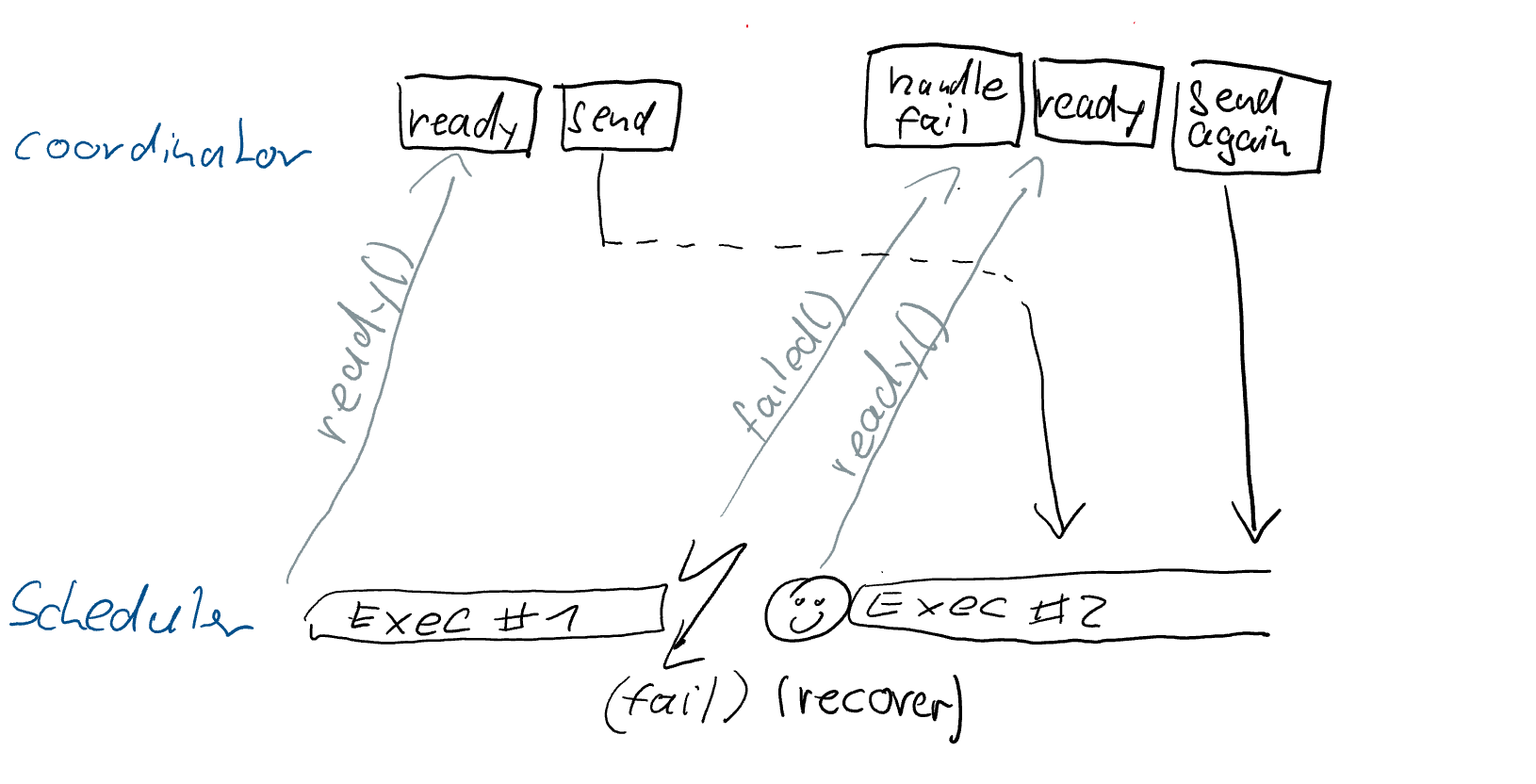
This is relevant to the [FLINK-21996] problem, because to implement step (3)
outlined above correctly, we need to know which task the event was supposed to
go to.
If we have an Ack failure (failed `CompletableFuture<Acknowledge>`) and the
scheduler still thinks the target task is running, then we trigger the failure
of that specific target task. Then it was either failed already and we were
merely waiting for the hearbeat timeout, or we have indeed a lost RPC and need
this failover to be certain to be consistent again.
Without the precise information which task execution attempt the event
should even go to, we would fail the latest running execution attempt, which
will in many cases be the wrong task: the recovered task execution attempt.
This may even cause cascading failovery:
- send event to task-attempt-1
- task-attempt-1 fails, task-attempt-2 gets deployed
- coordinator may react to failure and message new task attempt
- timeout on the future of the first event sending, trigger failover of
latest task attempt (task-attempt-2)
- latest message from coordinator may again time out
- etc.
## Changes
The main change in this PR is that an `OperatorEvent` isn't just emitted via
the context to just the task that happens to be running, but sent to a specific
context that is scoped to the execution attempt of the task that was last
reported to be ready. It is quasi as if adding the `ExecutionAttemptID` to the
Operator Event message.
If the OperatorCoordinator hasn't yet processed the failure/recovery
notification, then the sent event is still targeted to the old execution
attempt, even if the scheduler is already miles ahead.
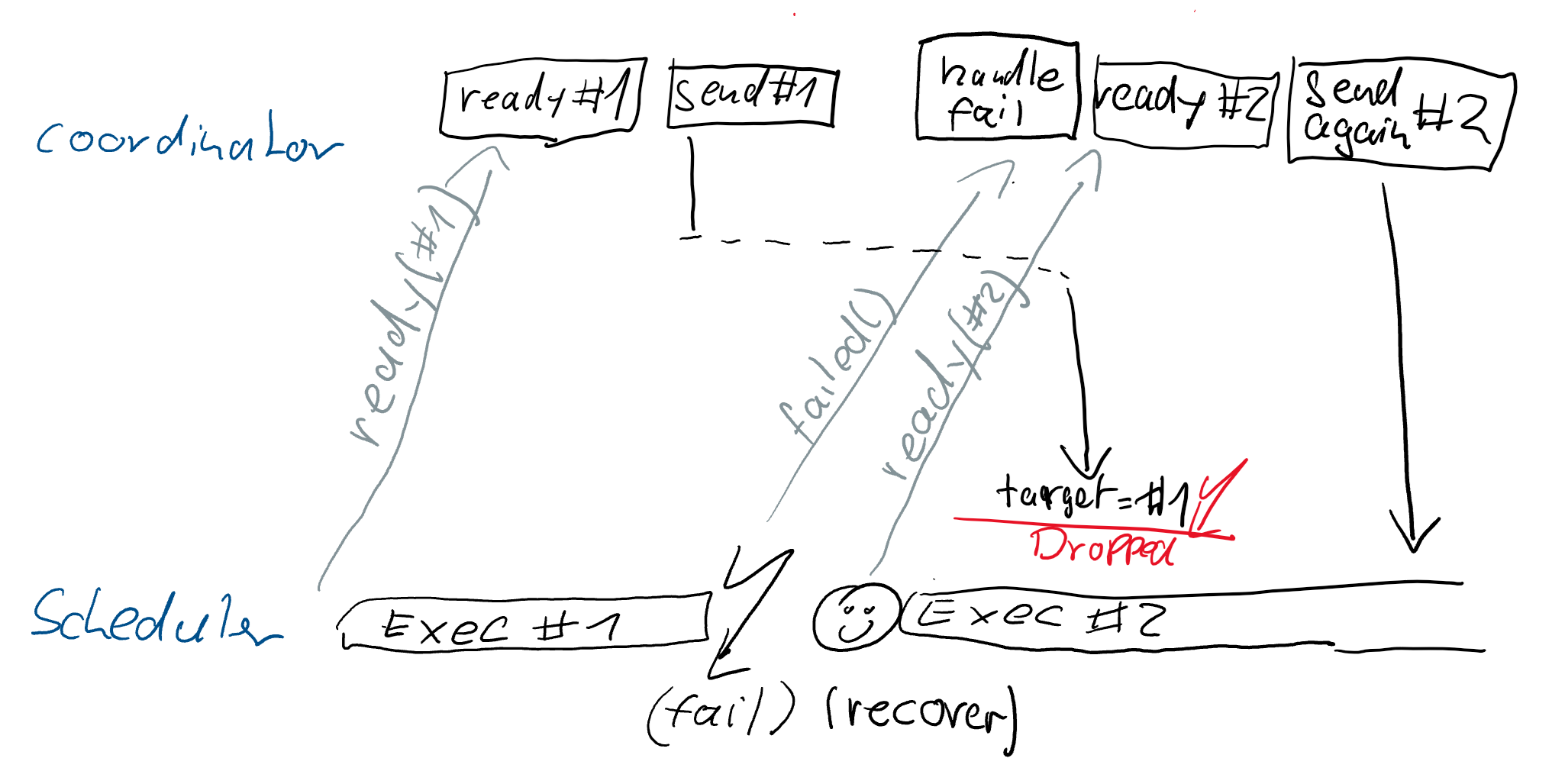
Concrete in the implementation, this means the following:
- For the public FLIP-27 source API, nothing changes, everything is hidden
by internal bookkeeping.
- For the `OperatorCoordinator` API, events are no longer sent through the
single `Context`, but through the `SubtaskGateway` that is scoped to a specific
execution attempt.
- The `OperatorCoordinator` gets the `SubtaskGateway` through a
notification `subtaskReady(int subtask, SubtaskGateway)`. The gateway remains
valid to use, but events sent to the target are dropped when the target isn't
running any more.
- Upon a failure notification for a subtask, the `OperatorCoordinator`
typically regards events since the last completed checkpoint as lost. It waits
until `subtaskReady(...)` to attempt sending to the recovered task (using the
new gateway).
## Verifying this change
This PR enhances the `CoordinatorEventsExactlyOnceITCase` to reliably
provoke the critical issue commit *(part 6)*. Running without the fix *(part
7)* fails the test every time.
With the solution in this change *(part 7)*, I managed to run the test now
successfully 1000x in a loop.
## Does this pull request potentially affect one of the following parts:
- Dependencies (does it add or upgrade a dependency): **no**
- The public API, i.e., is any changed class annotated with
`@Public(Evolving)`: **no**
- The serializers: **no**
- The runtime per-record code paths (performance sensitive): **no**
- Anything that affects deployment or recovery: JobManager (and its
components), Checkpointing, Kubernetes/Yarn/Mesos, ZooKeeper: **no**
- The S3 file system connector: **no**
## Documentation
- Does this pull request introduce a new feature? **no**
- If yes, how is the feature documented? **not applicable**
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
[email protected]
{kind=link}
{kind=link}