zch93 edited a comment on pull request #18687: URL: https://github.com/apache/flink/pull/18687#issuecomment-1036397677
My feeling was that it is not a wrong decision if I start this whole task again from the beginning, so made some initial test running on my local env, with the actual prop file (so which does not include any changes from me). Proposed solution, based on my investigation and my results from the tests: After I did several tests running locally, it seems my first suggestion will not work (so the TimeBasedTriggeringPolicy) due to some file name discrepancy. Local test results with the usage of TimeBasedTriggeringPolicy: 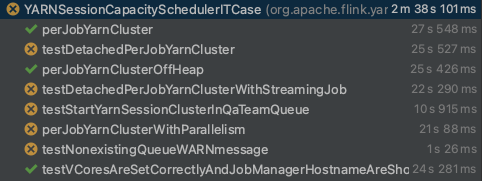 Error message for the test case which is the subject of this pr: `java.lang.AssertionError: Expected string 'Starting TaskManagers' not found in JobManager log: '/Users/zchikan/git_upstream_flink/flink/flink-yarn-tests/../flink-yarn-tests/target/flink-yarn-tests-capacityscheduler/flink-yarn-tests-capacityscheduler-logDir-nm-1_0/application_1644588076877_0002/container_1644588076877_0002_01_000001/jobmanager.log.1-2022-02-11 15:01:57,898'` So as you can see, it just made flaky for me, so definitely we cannot merge as it is. So let’s start from the beginning. The below picture is just a snapshot, but after 10 attempts, the results were the same, so the mentioned test is not flaky for me with the originally used OnStartupTriggeringPolicy, however there were some other tests which failed. Let me add some understanding next to these: 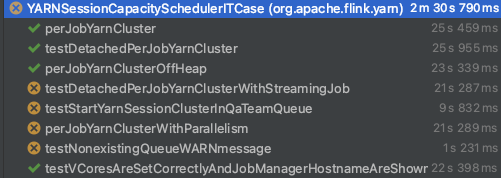 1. Why that test is not flaky for me? This is a conclusion by my investigation and feelings, but since this log4j issue is mostly hardware and filesystem dependent, that can happen I have a slower/faster hardware and/or I have different filesystem related configs. But anyway it was impossible for me to reproduce the flakiness of that test, however as there is a known bug in the log4j community about the OnStartupTriggeringPolicy, I still propose to eliminate the usage of that. 2. Why other tests failed? Based on the error message what I got: ``` `java.lang.AssertionError: Found a file /Users/zchikan/git_upstream_flink/flink/flink-yarn-tests/target/flink-yarn-tests-capacityscheduler/flink-yarn-tests-capacityscheduler-logDir-nm-1_0/application_1644576720361_0001/container_1644576720361_0001_01_000002/taskmanager.log with a prohibited string (one of [Exception, Started [email protected]:8081]). Excerpts: [ 2022-02-11 11:52:22,249 INFO org.apache.flink.runtime.taskexecutor.DefaultJobLeaderService [] - Remove job 035dfa32c1968c6326a629fb2a00f741 from job leader monitoring. 2022-02-11 11:52:22,250 INFO org.apache.flink.runtime.taskexecutor.TaskExecutor [] - Close JobManager connection for job 035dfa32c1968c6326a629fb2a00f741. 2022-02-11 11:53:11,996 INFO org.apache.flink.runtime.taskexecutor.TaskExecutor [] - The heartbeat of ResourceManager with id 2b5f6ba27a24052671cafd4091b8404f timed out. 2022-02-11 11:53:11,996 INFO org.apache.flink.runtime.taskexecutor.TaskExecutor [] - Close ResourceManager connection 2b5f6ba27a24052671cafd4091b8404f. 2022-02-11 11:53:11,997 INFO org.apache.flink.runtime.taskexecutor.TaskExecutor [] - Connecting to ResourceManager akka.tcp://[email protected]:52790/user/rpc/resourcemanager_*(00000000000000000000000000000000). 2022-02-11 11:53:22,016 INFO org.apache.flink.runtime.taskexecutor.TaskExecutor [] - Could not resolve ResourceManager address akka.tcp://[email protected]:52790/user/rpc/resourcemanager_*, retrying in 10000 ms: Could not connect to rpc endpoint under address akka.tcp://[email protected]:52790/user/rpc/resourcemanager_*. 2022-02-11 11:53:32,016 INFO akka.remote.transport.ProtocolStateActor [] - No response from remote for outbound association. Associate timed out after [20000 ms]. 2022-02-11 11:53:32,017 WARN akka.remote.ReliableDeliverySupervisor [] - Association with remote system [akka.tcp://[email protected]:52790] has failed, address is now gated for [50] ms. Reason: [Association failed with [akka.tcp://[email protected]:52790]] Caused by: [No response from remote for outbound association. Associate timed out after [20000 ms].] 2022-02-11 11:53:32,035 INFO org.apache.flink.runtime.taskexecutor.TaskExecutor [] - Could not resolve ResourceManager address akka.tcp://[email protected]:52790/user/rpc/resourcemanager_*, retrying in 10000 ms: Could not connect to rpc endpoint under address akka.tcp://[email protected]:52790/user/rpc/resourcemanager_*. 2022-02-11 11:53:32,068 WARN akka.remote.transport.netty.NettyTransport [] - Remote connection to [null] failed with org.jboss.netty.channel.ConnectTimeoutException: connection timed out: /192.168.0.192:52790 2022-02-11 11:53:32,068 WARN akka.remote.transport.netty.NettyTransport [] - Remote connection to [null] failed with org.jboss.netty.channel.ConnectTimeoutException: connection timed out: /192.168.0.192:52790 ]` ``` After some investigation, it seems like a new kind of bug which is related to AKKA remoting, and as far as I know these kind of errors appear when your HostIP is not matching with the configured seed nodes, so it come from some discrepancy between my local config and akka.remote configuration. Or (and in my case it can be the possible reason) the association with remote system has failed because the executor likely ran out memory. And it is possible in my case, because after some invalidate cache round, and after a while the tests run successfully with my NEW changes which are: - the deletion of OnStartupTriggeringPolicy (and not use TimeBasedTriggeringPolicy) - The addition of CronTriggeringPolicy 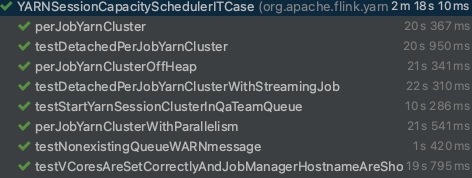 (Short comment: after this only one occurrence, I always received the same test results with and without my changes, so the first 3 and the last one run properly, but the other tests failed) So a solution (if we would like to use any, next to the DefaultRolloverStrategy) can be the usage of the CronTriggeringPolicy. In my last commit, I was delete the TimeBasedTriggeringPolicy and add the CronTriggeringPolicy with a schedule like the triggering should happen in every hours (it can be changed if you would You can see the usual results of local test running, after my changes in the below picture: 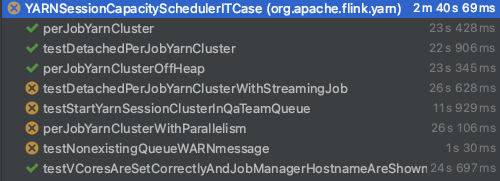 However as I mentioned above, after some “Invalidate cache” and flink rebuild in my IntelliJ, there were a fully successful test (see above) As these results not differ from the original runs (without my changes), I propose you to try out my changes on your own, local machines and if you experience the same like me, then I think this pr all be ready to merge to fix the highlighted problem. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}