dannycranmer commented on pull request #18733: URL: https://github.com/apache/flink/pull/18733#issuecomment-1040593983
I have been taking a deeper dive into this issue and am no longer inclined to make this change. I have verified that when running on a cluster, each job creates it's own `aws-java-sdk-NettyEventLoop` threads, and jobs do not interfere with each other. Running test cluster with 1 TM 1 CPU and 2 slots, posting 2 identical jobs. First job produces 2 threads: ``` "aws-java-sdk-NettyEventLoop-0-0" daemon prio=5 Id=76 RUNNABLE "aws-java-sdk-NettyEventLoop-0-1" daemon prio=5 Id=77 RUNNABLE ``` Second job produces 2 threads: ``` "aws-java-sdk-NettyEventLoop-0-0" daemon prio=5 Id=95 RUNNABLE "aws-java-sdk-NettyEventLoop-0-1" daemon prio=5 Id=96 RUNNABLE ``` Third job produces more threads etc. Killing jobs does not impact the other running jobs. You will notice the thread names are the same. This is because they are isolated in different job classloaders and cannot see each other to [increment the pool number](https://github.com/aws/aws-sdk-java-v2/blob/master/utils/src/main/java/software/amazon/awssdk/utils/ThreadFactoryBuilder.java#L75). I have also managed to consistently reproduce this issue locally, and backup @dmvk findings. To reproduce this I made the following changes ([My test code](https://github.com/dannycranmer/flink/commit/6e42d2a052ca1ef2d13679159de9f9ad617121ac)): - Switch the Flink job submission to `executeAsync()` - Move the test client initialisation to after job submission The problem in the flaky tests is that the `FlinkUserClassLoader` has the `Launcher$AppClassLoader` as it's parent classloader. This is the same classloader used by the test code. This means that both test code and Flink job can "see" the same ELG. As @dmvk pointed out, the Netty thread inherits current thread context classloader. The issue seems be be a race condition, since these clients are async, I guess that whoever makes the request first creates the Netty thread (not yet confirmed). The test blocks for Flink job to finish, which destroys the `FlinkUserClassLoader` and results in the classloader leak on the Netty threads. 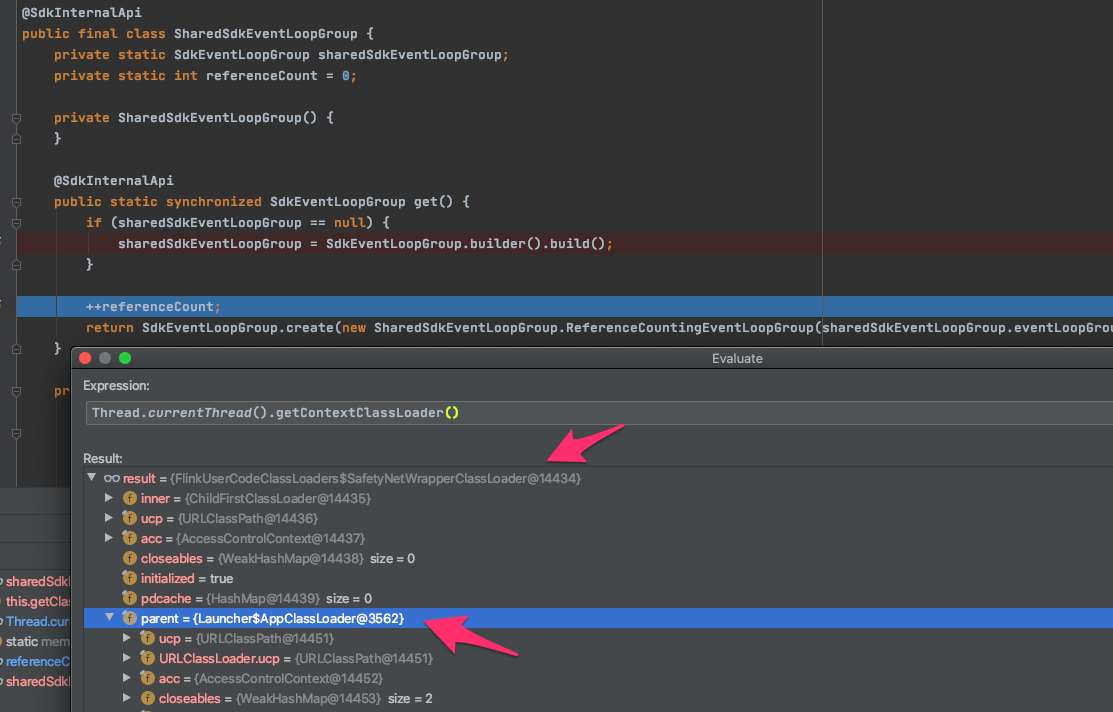 Based on this, I am not inclined to create a new ELG per sub task, since this will potentially create a large resource overhead. This would also impact our current Kinesis EFO source, since it already uses the AWS SDK v2 async clients. Instead I would prefer to fix it in the test, either by setting a separate ELG on the test clients, or migrating to synchronous clients. I prefer the latter, since there is no need to spin up a thread pool for these tests! The tradeoff would be that this issue could still surface for people running embedded Flink mini clusters. However, given the compromise I am willing to accept this. @dmvk please give me your thoughts. Also, happy to discuss if easier. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}