infraio commented on a change in pull request #1730:
URL: https://github.com/apache/hbase/pull/1730#discussion_r430245575
##########
File path:
hbase-server/src/main/java/org/apache/hadoop/hbase/regionserver/StoreFileWriter.java
##########
@@ -547,6 +553,22 @@ public StoreFileWriter build() throws IOException {
CommonFSUtils.setStoragePolicy(this.fs, dir, policyName);
if (filePath == null) {
+ // The stored file and related blocks will used the directory based
StoragePolicy.
+ // Because HDFS DistributedFileSystem does not support create files
with storage policy
+ // before version 3.3.0 (See HDFS-13209). Use child dir here is to
make stored files
+ // satisfy the specific storage policy when writing. So as to avoid
later data movement.
+ // We don't want to change whole temp dir to 'fileStoragePolicy'.
+ if (fileStoragePolicy != null && !fileStoragePolicy.isEmpty()) {
+ dir = new Path(dir, HConstants.STORAGE_POLICY_PREFIX +
fileStoragePolicy);
+ if (!fs.exists(dir)) {
+ HRegionFileSystem.mkdirs(fs, conf, dir);
+ }
+ CommonFSUtils.setStoragePolicy(this.fs, dir, fileStoragePolicy);
+ if (LOG.isDebugEnabled()) {
+ LOG.debug(
Review comment:
Only log once when region created? If so, can use info log.
##########
File path: dev-support/design-docs/HBASE-24289-Heterogeneous Storage for Date
Tiered Compaction.md
##########
@@ -0,0 +1,122 @@
+<!--
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
+-->
+
+# Heterogeneous Storage for Date Tiered Compaction
+
+## Objective
+
+Support
DateTiredCompaction([HBASE-15181](https://issues.apache.org/jira/browse/HBASE-15181))
+ for cold and hot data separation, support different storage policies for
different time periods
+ of data to get better performance, for example, we can configure the data of
last 1 month in SSD,
+ and 1 month ago data was in HDD.
+
++ Date Tiered Compaction (DTCP) is based on date tiering (date-aware), we hope
to support
+ the separation of cold and hot data, heterogeneous storage. Set different
storage
+ policies (in HDFS) for data in different time windows.
++ DTCP designs different windows, and we can classify the windows according to
+ the timestamps of the windows. For example: HOT window, WARM window, COLD
window.
++ DTCP divides storefiles into different windows, and performs minor
Compaction within
+ a time window. The storefile generated by Compaction will use the storage
strategy of
+ this window. For example, if a window is a HOT window, the storefile
generated by compaction
+ can be stored on the SSD. There are already WAL and the entire CF support
storage policy
+ (HBASE-12848, HBASE-14061), our goal is to achieve cold and hot separation
in one CF or
+ a region, using different storage policies.
+
+## Definition of hot and cold data
+
+Usually the data of the last 3 days can be defined as `HOT data`, hot age = 3
days.
+ If the timestamp of the data is > (timestamp now - hot age), we think the
data is hot data.
+ Warm age, cold age can be defined in the same way. Only one type of data is
allowed.
+ ```
+ if timestamp > (now - hot age) , HOT data
+ else if timestamp > (now - warm age), WARM data
+ else if timestamp > (now - cold age), COLD data
+ else default, COLD data
+```
+
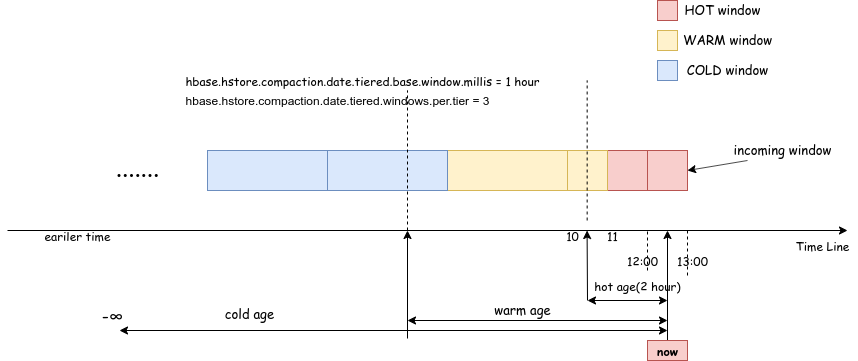
+## Time window
+When given a time now, it is the time when the compaction occurs. Each window
and the size of
+ the window are automatically calculated by DTCP, and the window boundary is
rounded according
+ to the base size.
+Assuming that the base window size is 1 hour, and each tier has 3 windows, the
current time is
+ between 12:00 and 13:00. We have defined three types of winow (`HOT, WARM,
COLD`). The type of
+ winodw is determined by the timestamp at the beginning of the window and the
timestamp now.
+As shown in the figure 1 below, the type of each window can be determined by
the age range
+ (hot / warm / cold) where (now - window.startTimestamp) falls. Cold age can
not need to be set,
+ the default Long.MAX, meaning that the window with a very early time stamp
belongs to the
+ cold window.
+
+
+## Example configuration
+
+| Configuration Key | value | Note |
+|:---|:---:|:---|
+|hbase.hstore.compaction.date.tiered.storage.policy.enable|true|if or not use
storage policy for window. Default is false|
+|hbase.hstore.compaction.date.tiered.hot.window.age.millis|3600000|hot data age
+|hbase.hstore.compaction.date.tiered.hot.window.storage.policy|ALL_SSD|hot
data storage policy, Corresponding HDFS storage policy
+|hbase.hstore.compaction.date.tiered.warm.window.age.millis|20600000||
+|hbase.hstore.compaction.date.tiered.warm.window.storage.policy|ONE_SSD||
+|hbase.hstore.compaction.date.tiered.cold.window.age.millis|Long.MAX||
+|hbase.hstore.compaction.date.tiered.cold.window.storage.policy|HOT||
+
+The original date tiered compaction related configuration has the same meaning
and maintains
Review comment:
What will happen if the CF config storage policy and enable this feature
too?
##########
File path: dev-support/design-docs/HBASE-24289-Heterogeneous Storage for Date
Tiered Compaction.md
##########
@@ -0,0 +1,122 @@
+<!--
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
+-->
+
+# Heterogeneous Storage for Date Tiered Compaction
+
+## Objective
+
+Support
DateTiredCompaction([HBASE-15181](https://issues.apache.org/jira/browse/HBASE-15181))
+ for cold and hot data separation, support different storage policies for
different time periods
+ of data to get better performance, for example, we can configure the data of
last 1 month in SSD,
+ and 1 month ago data was in HDD.
+
++ Date Tiered Compaction (DTCP) is based on date tiering (date-aware), we hope
to support
+ the separation of cold and hot data, heterogeneous storage. Set different
storage
+ policies (in HDFS) for data in different time windows.
++ DTCP designs different windows, and we can classify the windows according to
+ the timestamps of the windows. For example: HOT window, WARM window, COLD
window.
++ DTCP divides storefiles into different windows, and performs minor
Compaction within
+ a time window. The storefile generated by Compaction will use the storage
strategy of
+ this window. For example, if a window is a HOT window, the storefile
generated by compaction
+ can be stored on the SSD. There are already WAL and the entire CF support
storage policy
+ (HBASE-12848, HBASE-14061), our goal is to achieve cold and hot separation
in one CF or
+ a region, using different storage policies.
+
+## Definition of hot and cold data
+
+Usually the data of the last 3 days can be defined as `HOT data`, hot age = 3
days.
+ If the timestamp of the data is > (timestamp now - hot age), we think the
data is hot data.
+ Warm age, cold age can be defined in the same way. Only one type of data is
allowed.
+ ```
+ if timestamp > (now - hot age) , HOT data
+ else if timestamp > (now - warm age), WARM data
+ else if timestamp > (now - cold age), COLD data
+ else default, COLD data
+```
+
+## Time window
+When given a time now, it is the time when the compaction occurs. Each window
and the size of
+ the window are automatically calculated by DTCP, and the window boundary is
rounded according
+ to the base size.
+Assuming that the base window size is 1 hour, and each tier has 3 windows, the
current time is
+ between 12:00 and 13:00. We have defined three types of winow (`HOT, WARM,
COLD`). The type of
+ winodw is determined by the timestamp at the beginning of the window and the
timestamp now.
+As shown in the figure 1 below, the type of each window can be determined by
the age range
+ (hot / warm / cold) where (now - window.startTimestamp) falls. Cold age can
not need to be set,
+ the default Long.MAX, meaning that the window with a very early time stamp
belongs to the
+ cold window.
+
+
+## Example configuration
+
+| Configuration Key | value | Note |
+|:---|:---:|:---|
+|hbase.hstore.compaction.date.tiered.storage.policy.enable|true|if or not use
storage policy for window. Default is false|
+|hbase.hstore.compaction.date.tiered.hot.window.age.millis|3600000|hot data age
+|hbase.hstore.compaction.date.tiered.hot.window.storage.policy|ALL_SSD|hot
data storage policy, Corresponding HDFS storage policy
+|hbase.hstore.compaction.date.tiered.warm.window.age.millis|20600000||
+|hbase.hstore.compaction.date.tiered.warm.window.storage.policy|ONE_SSD||
+|hbase.hstore.compaction.date.tiered.cold.window.age.millis|Long.MAX||
+|hbase.hstore.compaction.date.tiered.cold.window.storage.policy|HOT||
+
+The original date tiered compaction related configuration has the same meaning
and maintains
+ compatibility.
+If `hbase.hstore.compaction.date.tiered.storage.policy.enable = false`. DTCP
still follows the
+ original logic and has not changed.
+
+## Storage strategy
+HDFS provides the following storage policies, you can refer to
+
https://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/ArchivalStorage.html
+
+|Policy ID | Policy Name | Block Placement (3 replicas)|
+|:---|:---|:---|
+|15|Lasy_Persist|RAM_DISK: 1, DISK: 2|
+|12|All_SSD|SSD: 3|
+|10|One_SSD|SSD: 1, DISK: 2|
+|7|Hot (default)|DISK: 3|
+|5|Warm|DISK: 1, ARCHIVE: 2|
+|2|Cold|ARCHIVE: 3|
+
+Date Tiered Compaction (DTCP) supports the output of multiple storefiles. We
hope that these
+ storefiles can be set with different storage policies (in HDFS).
+ Therefore, through DateTieredMultiFileWriter to generate different
StoreFileWriters with
+ storage policy to achieve the purpose.
+
+## Why use different child tmp dir
+Before StoreFileWriter writes a storefile, we can create different dirs in the
tmp directory
+ of the region and set the corresponding storage policy for these dirs. This
way
+ StoreFileWriter can write files to different dirs.
+Since **HDFS** does not support the create file with the storage policy
parameter
+ (maybe I am wrong, I did not find the relevant interface on hadoop 2.6), and
HDFS cannot
+ set a storage policy for a file / dir path that does not yet exist. When the
compaction ends,
+ the storefile path must exist at this time, and I set the storage policy to
Storefile.
+But, in HDFS, when the file is written first, and then the storage policy is
set.
+ The actual storage location of the data does not match the storage policy.
For example,
+ write three copies of a file (1 block) in the HDD, then set storage policy is
ALL_SSD,
+ but the data block will not be moved to the SSD immediately.
+ “HDFS wont move the file content across different block volumes on rename”.
Data movement
+ requires the HDFS mover tool, or use HDFS SPS
+ (for details, see https://issues.apache.org/jira/browse/HDFS-10285), so in
order to
+ avoid moving data blocks at the HDFS level, we can set the file parent
directory to
+ the storage policy we need before writing data. The new file automatically
inherits the
+ storage policy of the parent directory, and is written according to the
correct disk
+ type when writing. So as to avoid later data movement.
Review comment:
Great.
##########
File path:
hbase-server/src/main/java/org/apache/hadoop/hbase/regionserver/DateTieredMultiFileWriter.java
##########
@@ -38,23 +38,34 @@
private final boolean needEmptyFile;
+ private final Map<Long, String> lowerBoundariesPolicies;
+
/**
+ * @param lowerBoundariesPolicies each window to storage policy map.
* @param needEmptyFile whether need to create an empty store file if we
haven't written out
* anything.
*/
- public DateTieredMultiFileWriter(List<Long> lowerBoundaries, boolean
needEmptyFile) {
+ public DateTieredMultiFileWriter(List<Long> lowerBoundaries,
+ Map<Long, String> lowerBoundariesPolicies, boolean needEmptyFile) {
for (Long lowerBoundary : lowerBoundaries) {
lowerBoundary2Writer.put(lowerBoundary, null);
}
this.needEmptyFile = needEmptyFile;
+ this.lowerBoundariesPolicies = lowerBoundariesPolicies;
}
@Override
public void append(Cell cell) throws IOException {
Map.Entry<Long, StoreFileWriter> entry =
lowerBoundary2Writer.floorEntry(cell.getTimestamp());
StoreFileWriter writer = entry.getValue();
if (writer == null) {
- writer = writerFactory.createWriter();
+ String lowerBoundaryStoragePolicy =
lowerBoundariesPolicies.get(entry.getKey());
+ if (lowerBoundaryStoragePolicy != null) {
+ writer =
writerFactory.createWriterWithStoragePolicy(lowerBoundaryStoragePolicy);
+ } else {
+ writer = writerFactory.createWriter();
+ }
+ //writer = writerFactory.createWriter();
Review comment:
Can be removed.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
{kind=link}