ndimiduk commented on PR #4601: URL: https://github.com/apache/hbase/pull/4601#issuecomment-1195598276
Okay, after too long of a delay, I have collected some data in which I have some amount confidence. The raw data and summaries are in this [Google Sheet](https://docs.google.com/spreadsheets/d/1O6iJQXh3a5y_VN9ChsGICbyoZhsTDNazraqci7GDhuw/edit?usp=sharing) for your examination. The charts are pasted here for your reference. 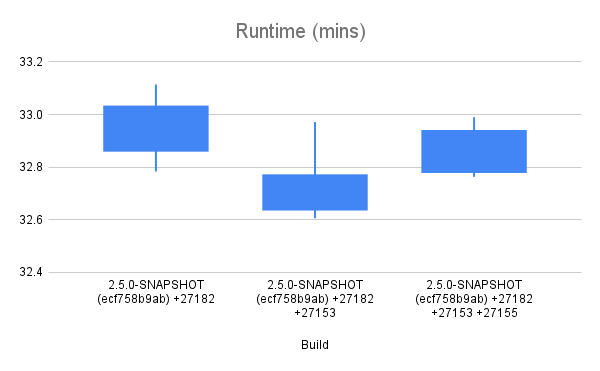 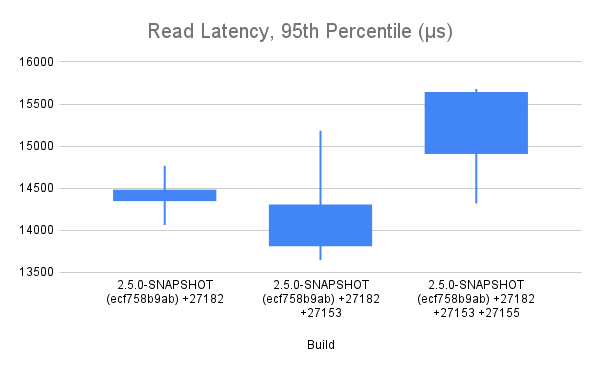 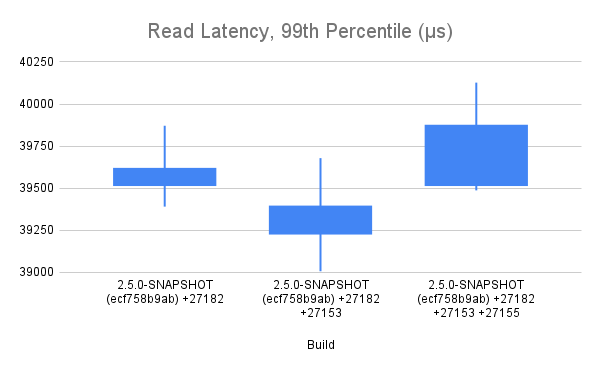 ## Test Methodology I tested three different builds: a baseline (ecf758b9ab), that baseline (ecf758b9ab) + HBASE-27153, and that baseline (ecf758b9ab) + HBASE-27153 + HBASE-27155. In all cases, the test is run with tracing disabled -- all that's measured here is the impact of the code changes made to facilitate manual instrumentation by each patch. The test run was a YCSB workload that I happened to have handy, with 20% writes and 80% random reads. The test runs for a little over 30 minutes. The data collected is the total test runtime, and the read latencies reported by YCSB at p95 and p99. The test methodology was to first prepare a dataset by populating a pre-split table using the YCSB load feature, flush and major compact the table, snapshot the table. Each test iteration involved dropping the table, cloning the snapshot back into place, and then applying the test workload. I kept an eye on cluster metrics as things ran. Client and server generally agree on number of requests served/sec. Each test, it took about 20 minutes for the block cache hit rate to climb from a starting point of 50% to the steady state of around 70%. I made an effort to exclude as much as possible the impact of compactions on the test results -- ASYNC_WAL was used, and dropping the table after each test run dropped the pending compaction work that accumulated via the write portion of the workload. ## My Interpretation of results The changes introduced with HBASE-27153 appear to have an overall positive impact on read throughput and latency, although in latency in particular, there is a disturbingly large amount of internal variance. HBASE-27155 appears to undo all of that improvement and then do additional harm. It is my opinion that the regression of 2ms at p95 and 1ms at p99 is too expensive to accept for the inclusion of HBASE-27155. ## Next Steps We can conclude analysis here and decide to commit one or both patches. Or, we can attempt further analysis. The next analysis step I would suggest is collection and comparison of flame graphs at several points during the test period. Please advise. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}
{kind=link}