coolderli opened a new issue #2632: URL: https://github.com/apache/iceberg/issues/2632
I was trying to write binlog to an iceberg table with Flink SQL. This is my iceberg table with a primary key `id`. spark-sql> desc extended goods_info_backend_v2; **id bigint 主键** gid bigint 商品ID pid bigint 商品型号ID cid1 int 旧一级分类 cid2 int 旧二级分类 cid3 int 旧三级分类 cid4 int 旧四级分类 ... Table Properties [current-snapshot-id=4044922955807923122,**equality.field.columns=id,format=iceberg/parquet,format.version=2**,read.parquet.vectorization.enabled=true,read.split.target-size=1073741824,write.distribution-mode=hash,write.spark.fanout.enabled=true] When I select `count(id)`, I got duplicated data. 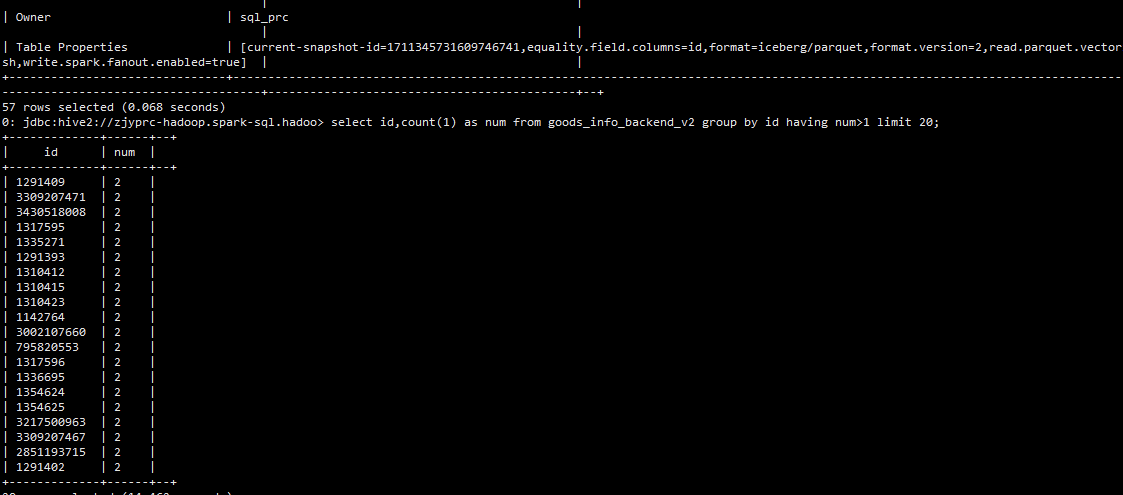 So I check the snapshots and chose an `id=1349343` to found which snapshots that data was appended. 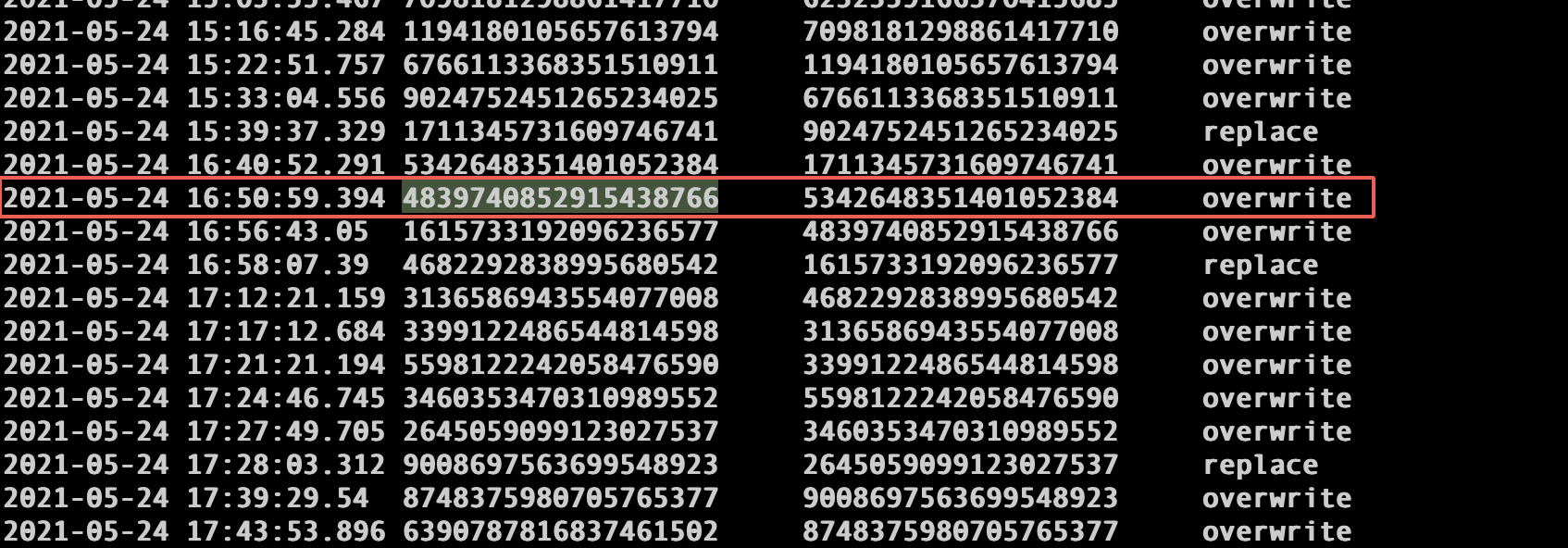 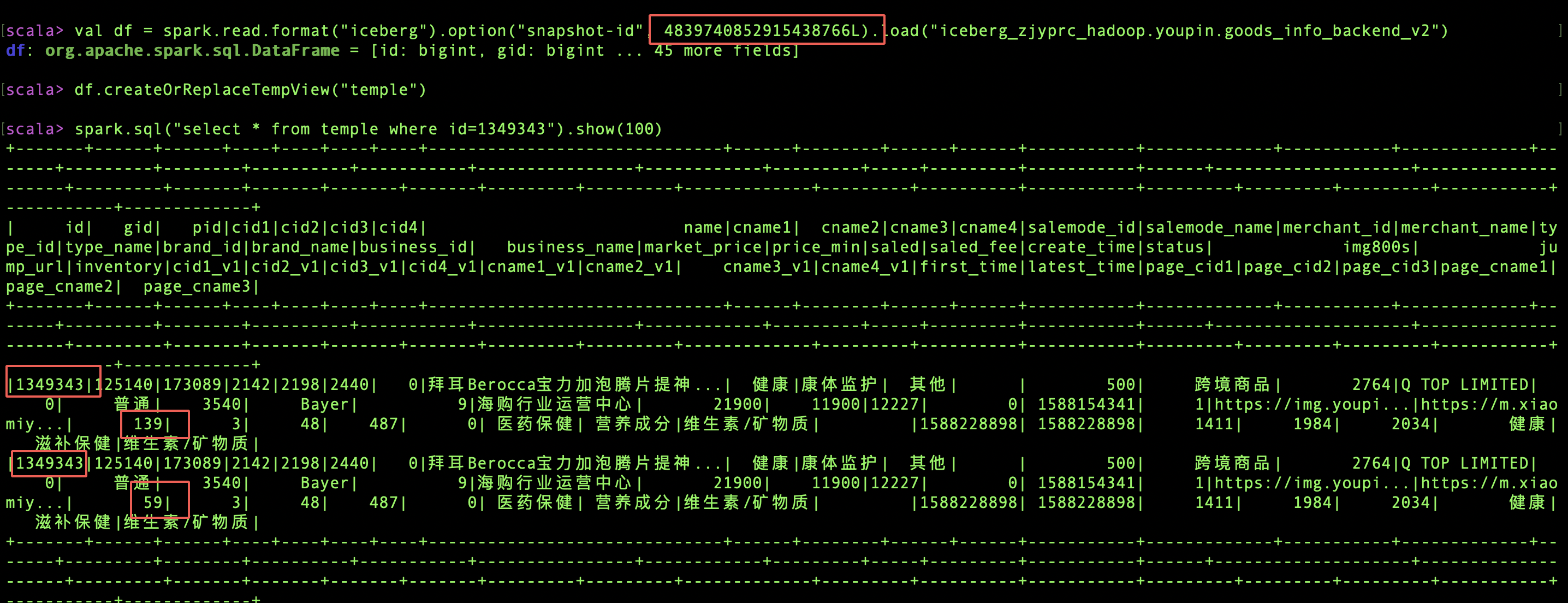 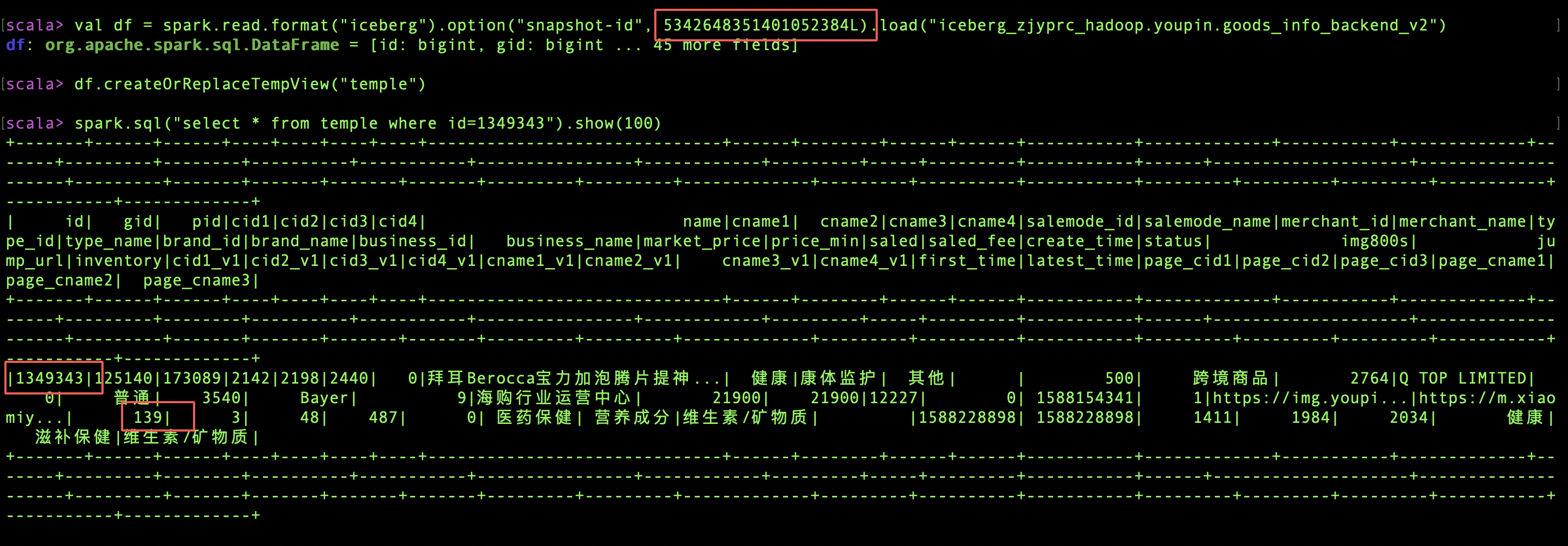 And I found the duplicated data `id=1349343` was appended in snapshotId= 4839740852915438766. In this snapshot, we got 48 added data files and 93 added-delete files. ``` spark-sql> select * from iceberg_zjyprc_hadoop.xxx.xxx.snapshots where snapshot_id=4839740852915438766; 2021-05-24 16:50:59.394 4839740852915438766 5342648351401052384 overwrite hdfs://zjyprc-hadoop/user/h_data_platform/datalake/youpin.db/goods_info_backend_v2/metadata/snap-4839740852915438766-1-1f06a123-f35f-4ed4-9cfe-65324b98549d.avro {"added-data-files":"48","added-delete-files":"93","added-equality-deletes":"20506","added-files-size":"4654283","added-position-deletes":"2060","added-records":"10253","changed-partition-count":"16","flink.job-id":"c872284a1caca024b7cb26870e5c8e51","flink.max-committed-checkpoint-id":"234","total-data-files":"80","total-delete-files":"115","total-equality-deletes":"21108","total-files-size":"27224132","total-position-deletes":"2066","total-records":"252220"} Time taken: 0.27 seconds, Fetched 1 row(s) ``` So I download these data files and delete files, and grep `1349343`, and got the answer: Two filed were found in two data files and four fields were found in two delete files. The snapshot and manifest files could be found in accessories (base) ➜ data grep -r 1349343 ./* ./00885:value 217: R:0 D:0 V:1349343 ./00931:value 190: R:0 D:0 V:1349343 (base) ➜ delete grep -r 1349343 ./* ./00886:value 433: R:0 D:0 V:1349343 ./00886:value 434: R:0 D:0 V:1349343 ./00932:value 379: R:0 D:0 V:1349343 ./00932:value 380: R:0 D:0 V:1349343 And I think 00885 and 00931 were added in the same commit, but why there are no position-delete files. At the same time, I found 1349343 was in bucket-5, so I check the snapshot files to try to found the position files in bucket-5, but failed to found the related rows. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected] --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}