aimenglin commented on issue #2685:
URL: https://github.com/apache/iceberg/issues/2685#issuecomment-858180173
1. Created a Iceberg Table using Hadoop Table on Spark:
// Create a Iceberg Table
```
spark-shell --conf
spark.sql.warehouse.dir=gs://shenme_dataproc_1/spark-warehouse --jars
/usr/lib/iceberg/jars/iceberg-spark-runtime.jar
import org.apache.hadoop.conf.Configuration
import org.apache.iceberg.hadoop.HadoopTables
import org.apache.iceberg.Table
import org.apache.iceberg.Schema
import org.apache.iceberg.types.Types._
import org.apache.iceberg.PartitionSpec
import org.apache.iceberg.spark.SparkSchemaUtil
import org.apache.spark.sql._
```
// Insert a 4 rows
```
scala> val conf = new Configuration();
conf: org.apache.hadoop.conf.Configuration = Configuration:
core-default.xml, core-site.xml, mapred-default.xml, mapred-site.xml,
yarn-default.xml, yarn-site.xm
l, hdfs-default.xml, hdfs-site.xml, resource-types.xml
scala> val tables = new HadoopTables(conf);
tables: org.apache.iceberg.hadoop.HadoopTables =
org.apache.iceberg.hadoop.HadoopTables@6fac8b24
scala> val df1 = Seq((1,"Vincent","Computer Science"),(2,"Dan",
"Economics"),(3,"Bob", "Politics"),(4,"Cindy", "UX
Design")).toDF("id","name","major");
df1: org.apache.spark.sql.DataFrame = [id: int, name: string ... 1 more
field]
scala> val df1_schema = SparkSchemaUtil.convert(df1.schema);
df1_schema: org.apache.iceberg.Schema =
table {
0: id: required int
1: name: optional string
2: major: optional string
}
scala> val partition_spec =
PartitionSpec.builderFor(df1_schema).identity("major").build;
partition_spec: org.apache.iceberg.PartitionSpec =
[
1000: major: identity(2)
]
scala> val table_location =
"gs://gcs-bucket-shenme-test-service-7f1dbd01-5cc9-4393-a54a-e9c2b9c9/hive-warehouse/test1";
table_location: String =
gs://gcs-bucket-shenme-test-service-7f1dbd01-5cc9-4393-a54a-e9c2b9c9/hive-warehouse/test1
scala> val hadooptable = tables.create(df1_schema, partition_spec,
table_location);
hadooptable: org.apache.iceberg.Table =
gs://gcs-bucket-shenme-test-service-7f1dbd01-5cc9-4393-a54a-e9c2b9c9/hive-warehouse/test1
scala> df1.write.format("iceberg").mode("overwrite").save(table_location);
```
// Query 4 rows on Spark
```
scala> val read_df1=spark.read.format("iceberg").load(table_location);
read_df1: org.apache.spark.sql.DataFrame = [id: int, name: string ... 1 more
field]
scala> read_df1.show;
+---+-------+----------------+
| id| name| major|
+---+-------+----------------+
| 1|Vincent|Computer Science|
| 2| Dan| Economics|
| 3| Bob| Politics|
| 4| Cindy| UX Design|
+---+-------+----------------+
```
// Add another column
```
scala> val table = tables.load(table_location);
table: org.apache.iceberg.Table =
gs://gcs-bucket-shenme-test-service-7f1dbd01-5cc9-4393-a54a-e9c2b9c9/hive-warehouse/test1
scala> table.updateSchema.addColumn("grade", StringType.get()).commit();
scala> table.schema.toString;
res8: String =
table {
1: id: required int
2: name: optional string
3: major: optional string
4: grade: optional string
}
```
// Add another 2 rows
```
scala> val df2=Seq((5,"Amy","UX
Design","Sophomore")).toDF("id","name","major","grade");
df2: org.apache.spark.sql.DataFrame = [id: int, name: string ... 2 more
fields]
scala> df2.write.format("iceberg").mode("append").save(table_location);
scala> val
df3=Seq((6,"Rachael","Economics","Freshman")).toDF("id","name","major","grade");
df3: org.apache.spark.sql.DataFrame = [id: int, name: string ... 2 more
fields]
scala> df3.write.format("iceberg").mode("append").save(table_location);
scala> val read_df2=spark.read.format("iceberg").load(table_location);
read_df2: org.apache.spark.sql.DataFrame = [id: int, name: string ... 2 more
fields]
scala> spark.read.format("iceberg").load(table_location).show(truncate =
false)
+---+-------+----------------+---------+
|id |name |major |grade |
+---+-------+----------------+---------+
|6 |Rachael|Economics |Freshman |
|1 |Vincent|Computer Science|null |
|2 |Dan |Economics |null |
|3 |Bob |Politics |null |
|4 |Cindy |UX Design |null |
|5 |Amy |UX Design |Sophomore|
+---+-------+----------------+---------+
```
// We have the data and the right set of metadata generated including
snapshots, manifests in the bucket.
2.Created an external table on Hive
```
hive
Hive Session ID = 521d08fa-9fda-4ca3-8bab-3d0b60ddc6de
Logging initialized using configuration in
file:/etc/hive/conf.dist/hive-log4j2.properties Async: true
Hive Session ID = 4f8d6c05-19a2-4e1e-8672-52b79d1fd566
hive> add jar /home/shenme_google_com/iceberg-hive-runtime.jar;
Added [/home/shenme_google_com/iceberg-hive-runtime.jar] to class path
Added resources: [/home/shenme_google_com/iceberg-hive-runtime.jar]
hive> set iceberg.engine.hive.enabled=true;
hive> set hive.vectorized.execution.enabled=false;
hive> CREATE EXTERNAL TABLE hadoop_table_1
> STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
> LOCATION
'gs://gcs-bucket-shenme-test-service-7f1dbd01-5cc9-4393-a54a-e9c2b9c9/hive-warehouse/test1/'
> TBLPROPERTIES
('iceberg.catalog'='gs://gcs-bucket-shenme-test-service-7f1dbd01-5cc9-4393-a54a-e9c2b9c9/hive-warehouse/test1');
OK
Time taken: 3.698 seconds
```
3. Read is fine, and then I insert a new row:
```
// Read via Hive
hive> describe formatted hadoop_table_1;
OK
# col_name data_type comment
id int from deserializer
name string from deserializer
major string from deserializer
grade string from deserializer
# Detailed Table Information
Database: default
OwnerType: USER
Owner: shenme_google_com
CreateTime: Wed Jun 09 23:21:26 UTC 2021
LastAccessTime: UNKNOWN
Retention: 0
Location:
gs://gcs-bucket-shenme-test-service-7f1dbd01-5cc9-4393-a54a-e9c2b9c9/hive-warehouse/test1
Table Type: EXTERNAL_TABLE
Table Parameters:
EXTERNAL TRUE
bucketing_version 2
iceberg.catalog
gs://gcs-bucket-shenme-test-service-7f1dbd01-5cc9-4393-a54a-e9c2b9c9/hive-warehouse/test1
numFiles 18
storage_handler
org.apache.iceberg.mr.hive.HiveIcebergStorageHandler
table_type ICEBERG
totalSize 48550
transient_lastDdlTime 1623280886
# Storage Information
SerDe Library: org.apache.iceberg.mr.hive.HiveIcebergSerDe
InputFormat: org.apache.iceberg.mr.hive.HiveIcebergInputFormat
OutputFormat: org.apache.iceberg.mr.hive.HiveIcebergOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
serialization.format 1
Time taken: 0.609 seconds, Fetched: 35 row(s)
hive> select * from hadoop_table_1;
Query ID =
shenme_google_com_20210609232347_cc7ce64b-6b80-4169-b1d5-caf42a300e96
Total jobs = 1
Launching Job 1 out of 1
Status: Running (Executing on YARN cluster with App id
application_1622522135523_0073)
----------------------------------------------------------------------------------------------
VERTICES MODE STATUS TOTAL COMPLETED RUNNING PENDING
FAILED KILLED
----------------------------------------------------------------------------------------------
Map 1 .......... container SUCCEEDED 1 1 0 0
0 0
----------------------------------------------------------------------------------------------
VERTICES: 01/01 [==========================>>] 100% ELAPSED TIME: 8.67 s
----------------------------------------------------------------------------------------------
OK
6 Rachael Economics Freshman
1 Vincent Computer Science NULL
2 Dan Economics NULL
3 Bob Politics NULL
4 Cindy UX Design NULL
5 Amy UX Design Sophomore
Time taken: 13.469 seconds, Fetched: 6 row(s)
```
// Insert a row
```
hive> INSERT INTO TABLE hadoop_table_1
> VALUES (7, "John", "Basketball", "Senior");
Query ID =
shenme_google_com_20210609232537_9d2ce449-4ebc-403b-8f74-8b08ba9f62d1
Total jobs = 1
Launching Job 1 out of 1
Status: Running (Executing on YARN cluster with App id
application_1622522135523_0073)
----------------------------------------------------------------------------------------------
VERTICES MODE STATUS TOTAL COMPLETED RUNNING PENDING
FAILED KILLED
----------------------------------------------------------------------------------------------
Map 1 .......... container SUCCEEDED 1 1 0 0
0 0
----------------------------------------------------------------------------------------------
VERTICES: 01/01 [==========================>>] 100% ELAPSED TIME: 6.71 s
----------------------------------------------------------------------------------------------
OK
Time taken: 10.374 seconds
```
// Read and check whether the data was written into the table
```
hive> select * from hadoop_table_1;
Query ID =
shenme_google_com_20210609232620_021c6e8a-cf7a-43d8-9ee9-44913a900e67
Total jobs = 1
Launching Job 1 out of 1
Status: Running (Executing on YARN cluster with App id
application_1622522135523_0073)
----------------------------------------------------------------------------------------------
VERTICES MODE STATUS TOTAL COMPLETED RUNNING PENDING
FAILED KILLED
----------------------------------------------------------------------------------------------
Map 1 .......... container SUCCEEDED 1 1 0 0
0 0
----------------------------------------------------------------------------------------------
VERTICES: 01/01 [==========================>>] 100% ELAPSED TIME: 7.24 s
----------------------------------------------------------------------------------------------
OK
6 Rachael Economics Freshman
1 Vincent Computer Science NULL
2 Dan Economics NULL
3 Bob Politics NULL
4 Cindy UX Design NULL
5 Amy UX Design Sophomore
Time taken: 9.196 seconds, Fetched: 6 row(s)
```
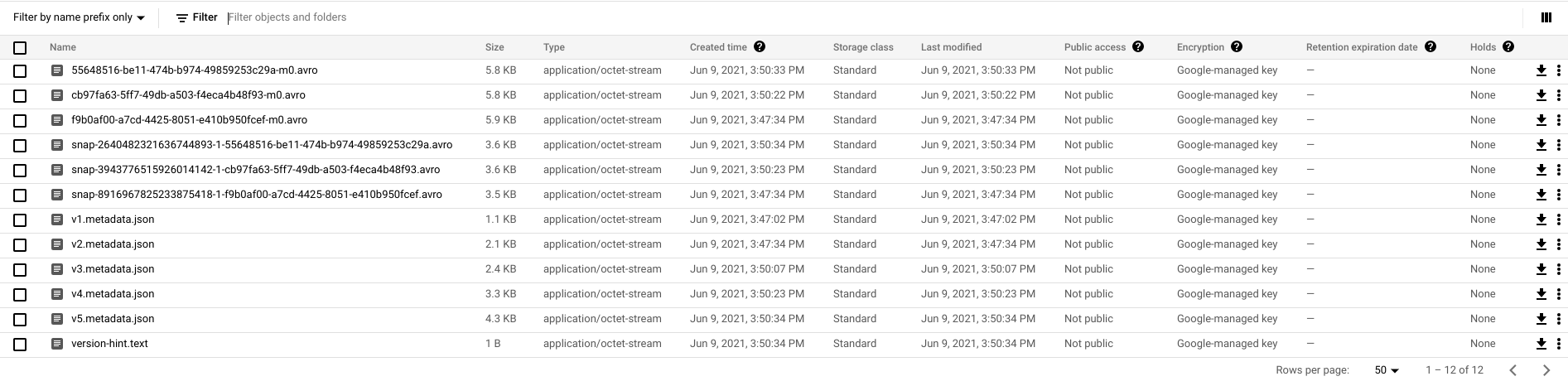
4. GS bucket screenshot, we got data generated, but no metadata. So after
select, the newly inserted row was not in the result.

Question:
I'm curious whether it's possible to read the newly inserted data via Hive.
Thanks in advance!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
[email protected]
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}