southernriver opened a new pull request #2803:
URL: https://github.com/apache/iceberg/pull/2803
For Spark2/Spark3, It always takes about 30 minutes to enter the Job
Submitted state for over 100000 files, the more files, the longer waiting time
for driver to scan. This piece of current code takes into account the locality
strategy of the data, and will call getBlockLocations sequentially in a single
thread.
Here is the thread log :
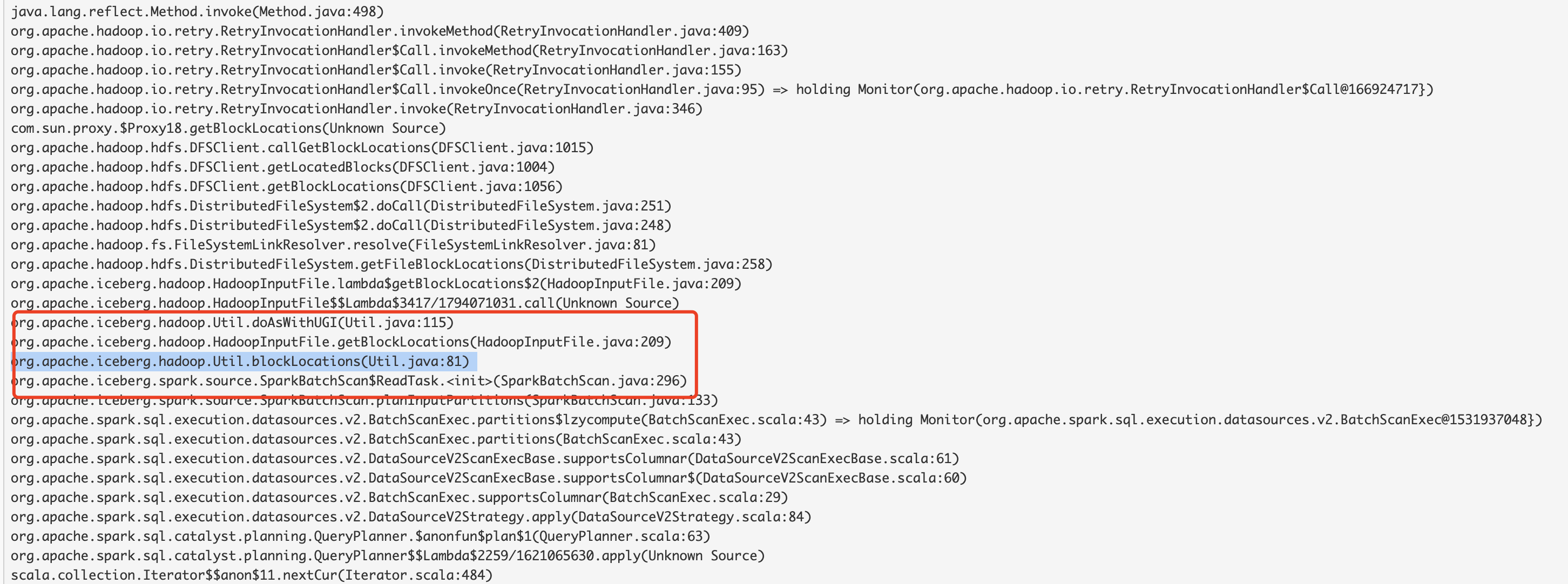
We can use multithreading to solve this problem.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}