flyrain edited a comment on pull request #3287:
URL: https://github.com/apache/iceberg/pull/3287#issuecomment-960433304
Add more benchmarks. There are 3 benchmark suites in total. cc
@RussellSpitzer
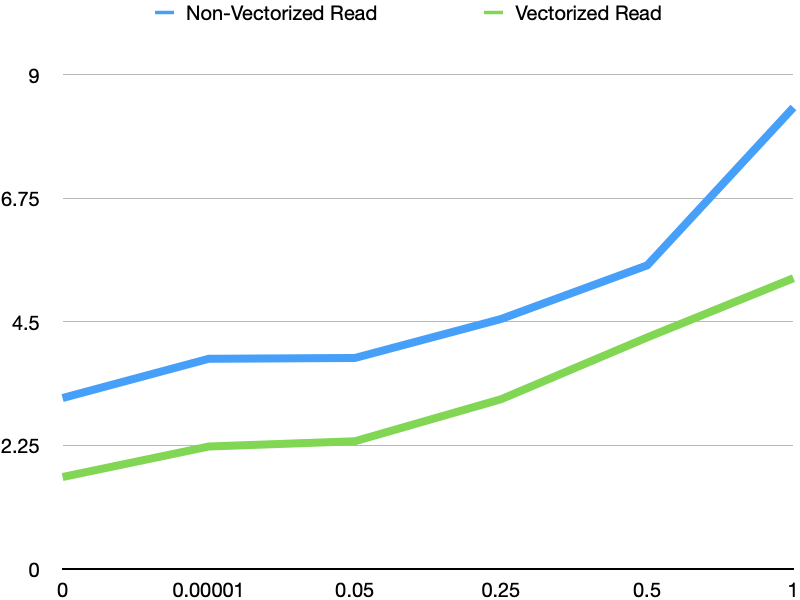
1. Compare vectorized read vs non-vectorized read with multiple number of
delete rows.
1.1 Without any deleted rows
1.2 With only one delete rows
1.3 With 5%, 25%, 50% and 100% deleted rows.
Overall, vectorized read is consistently faster than non-vectorized read,
about 55% faster.
```
Benchmark
(percentageDeleteRow) Mode Cnt Score Error Units
IcebergSourceFlatParquetDataDeleteBenchmark.readIceberg
0 ss 5 3.111 ± 0.227 s/op
IcebergSourceFlatParquetDataDeleteBenchmark.readIceberg
0.000001 ss 5 3.826 ± 0.153 s/op
IcebergSourceFlatParquetDataDeleteBenchmark.readIceberg
0.05 ss 5 3.841 ± 0.196 s/op
IcebergSourceFlatParquetDataDeleteBenchmark.readIceberg
0.25 ss 5 4.552 ± 0.320 s/op
IcebergSourceFlatParquetDataDeleteBenchmark.readIceberg
0.5 ss 5 5.530 ± 0.139 s/op
IcebergSourceFlatParquetDataDeleteBenchmark.readIceberg
1 ss 5 8.407 ± 0.222 s/op
IcebergSourceFlatParquetDataDeleteBenchmark.readIcebergVectorized
0 ss 5 1.671 ± 0.137 s/op
IcebergSourceFlatParquetDataDeleteBenchmark.readIcebergVectorized
0.000001 ss 5 2.227 ± 0.205 s/op
IcebergSourceFlatParquetDataDeleteBenchmark.readIcebergVectorized
0.05 ss 5 2.323 ± 0.155 s/op
IcebergSourceFlatParquetDataDeleteBenchmark.readIcebergVectorized
0.25 ss 5 3.089 ± 0.211 s/op
IcebergSourceFlatParquetDataDeleteBenchmark.readIcebergVectorized
0.5 ss 5 4.216 ± 0.156 s/op
IcebergSourceFlatParquetDataDeleteBenchmark.readIcebergVectorized
1 ss 5 5.295 ± 0.198 s/op
```
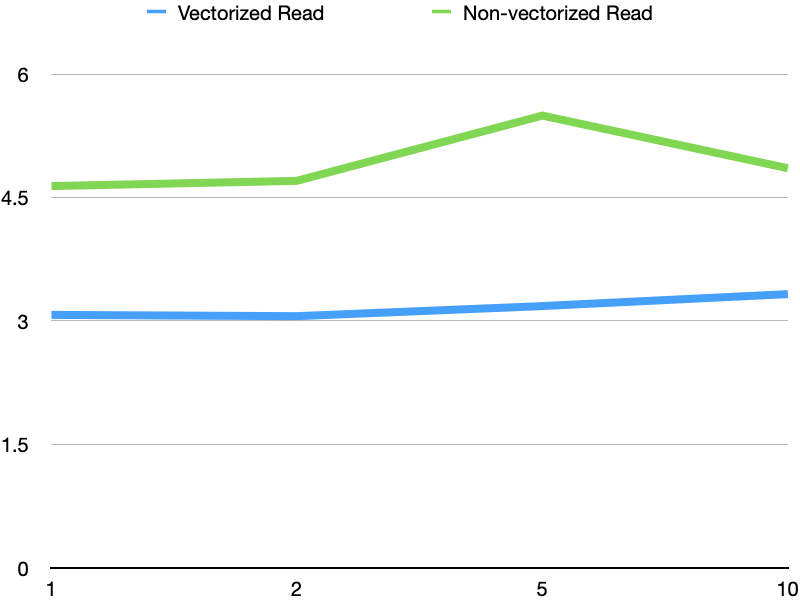
2. Compare vectorized read vs non-vectorized read with multiple delete
files. Here is the result with 25% rows are deleted and distribute these
deletes to 1, 2, 5, 10 delete files. The perf degradation is minor when num of
delete files increase.
```
Benchmark
(numDeleteFile) (percentageDeleteRow) Mode Cnt Score Error Units
IcebergSourceFlatParquetDataDeleteBenchmark.readIceberg
1 0.25 ss 5 4.639 ± 0.153 s/op
IcebergSourceFlatParquetDataDeleteBenchmark.readIceberg
2 0.25 ss 5 4.703 ± 0.319 s/op
IcebergSourceFlatParquetDataDeleteBenchmark.readIceberg
5 0.25 ss 5 5.496 ± 2.550 s/op
IcebergSourceFlatParquetDataDeleteBenchmark.readIceberg
10 0.25 ss 5 4.856 ± 0.605 s/op
IcebergSourceFlatParquetDataDeleteBenchmark.readIcebergVectorized
1 0.25 ss 5 3.074 ± 0.200 s/op
IcebergSourceFlatParquetDataDeleteBenchmark.readIcebergVectorized
2 0.25 ss 5 3.058 ± 0.176 s/op
IcebergSourceFlatParquetDataDeleteBenchmark.readIcebergVectorized
5 0.25 ss 5 3.181 ± 0.994 s/op
IcebergSourceFlatParquetDataDeleteBenchmark.readIcebergVectorized
10 0.25 ss 5 3.326 ± 0.692 s/op
```
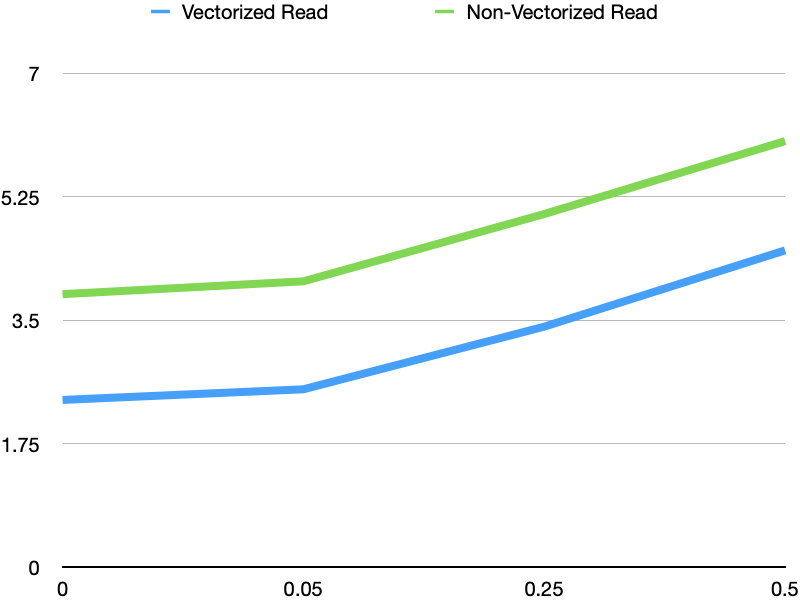
3. Compare vectorized read vs non-vectorized read with unrelated deleted
rows for the data files. Here is the result that 5% rows are deleted with
additional 0, 5%, 25%, 50% unrelated delete rows, all deletes are written into
one delete file. With more unrelated deleted rows, the performance degradation
is considerable. This may due to inefficiency of class `CharSeqComparator`. I
will try to open another PR for this.
```
Benchmark
(percentageNoise) Mode Cnt Score Error Units
IcebergSourceParquetDeleteMixedPosDeletesBenchmark.readIceberg
0 ss 5 3.872 ± 0.121 s/op
IcebergSourceParquetDeleteMixedPosDeletesBenchmark.readIceberg
0.05 ss 5 4.054 ± 0.176 s/op
IcebergSourceParquetDeleteMixedPosDeletesBenchmark.readIceberg
0.25 ss 5 5.008 ± 0.655 s/op
IcebergSourceParquetDeleteMixedPosDeletesBenchmark.readIceberg
0.5 ss 5 6.042 ± 0.338 s/op
IcebergSourceParquetDeleteMixedPosDeletesBenchmark.readIcebergVectorized
0 ss 5 2.372 ± 0.161 s/op
IcebergSourceParquetDeleteMixedPosDeletesBenchmark.readIcebergVectorized
0.05 ss 5 2.523 ± 0.179 s/op
IcebergSourceParquetDeleteMixedPosDeletesBenchmark.readIcebergVectorized
0.25 ss 5 3.411 ± 0.147 s/op
IcebergSourceParquetDeleteMixedPosDeletesBenchmark.readIcebergVectorized
0.5 ss 5 4.493 ± 0.190 s/op
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}
{kind=link}