Ranjith-AR removed a comment on issue #1894: URL: https://github.com/apache/iceberg/issues/1894#issuecomment-1050738332
I tried replicating the dual partition example provided in the docs https://iceberg.apache.org/docs/latest/spark-writes/ 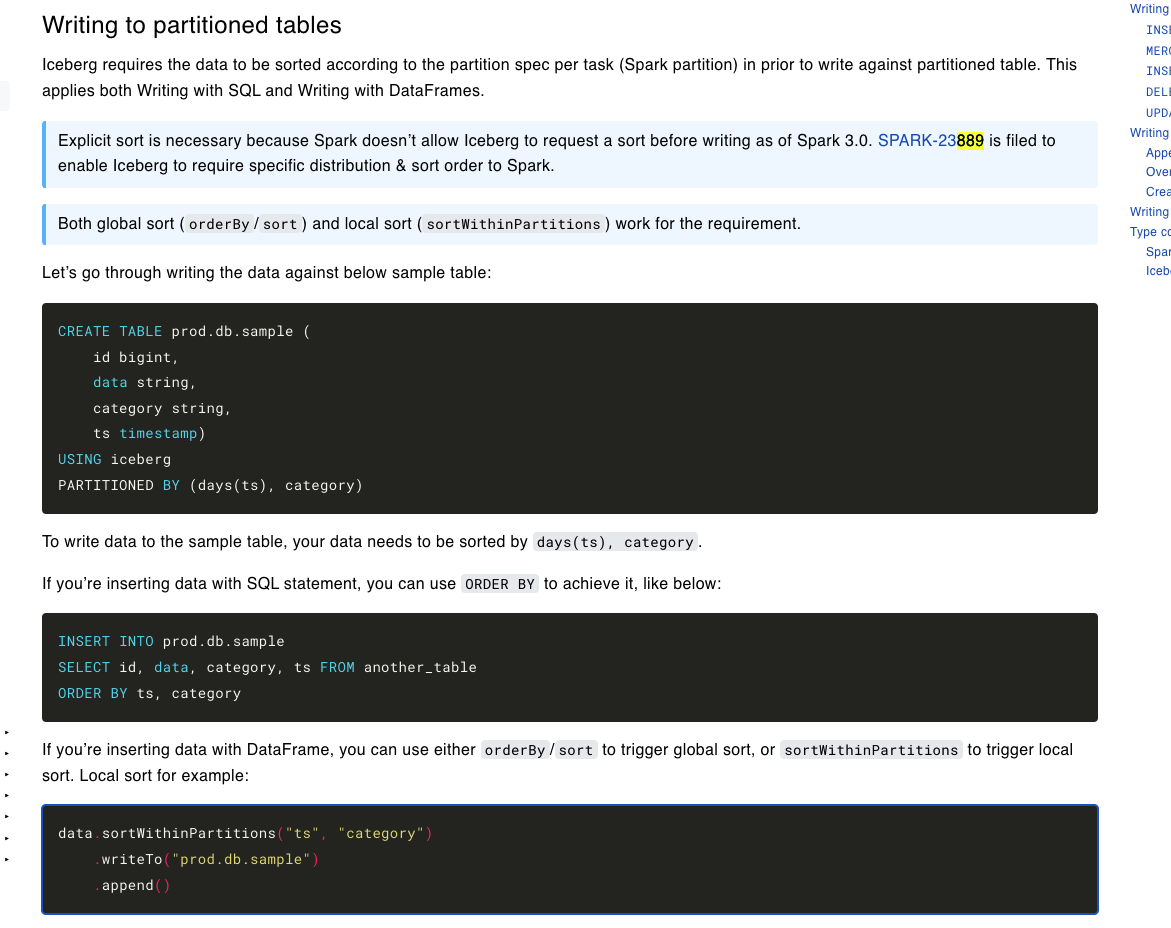 Created the below table: ------- "CREATE TABLE nyc.green_taxis_by_days_vendorid ( VendorID string, lpep_pickup_datetime timestamp, lpep_dropoff_datetime string, store_and_fwd_flag string,RatecodeID string,PULocationID string,DOLocationID string, passenger_count string,trip_distance string,fare_amount string,extra string,mta_tax string, tip_amount string,tolls_amount string,ehail_fee string,improvement_surcharge string, total_amount string, payment_type string,trip_type string, congestion_surcharge string) USING iceberg PARTITIONED BY ( ***days(lpep_pickup_datetime),VendorID*** )" ----- Trying to write into the table via both dataframe api and pyspark sql...and get the same error (i.e. file already closed) df_green_stage1.sortWithinPartitions(("lpep_pickup_datetime"),"VendorID") \ .writeTo("nyc.green_taxis_by_days_vendorid") \ .append() ----- %%sql INSERT INTO nyc.green_taxis_by_days_vendorid ( SELECT VendorID,lpep_pickup_datetime,lpep_dropoff_datetime,store_and_fwd_flag,RatecodeID,PULocationID,DOLocationID,passenger_count,trip_distance,fare_amount, extra,mta_tax,tip_amount,tolls_amount,ehail_fee, improvement_surcharge,total_amount,payment_type,trip_type,congestion_surcharge FROM nyc.green_taxis_by_days_vendorid_withdate ORDER BY lpep_pickup_datetime,VendorID ) ------ However, I run into the below error The partitions are defined as days(timestamp) and secondary as vendor id. since the dataframe is sorted by "timestamp, vendor id" and not as "days(timestamp), vendor id" as defined in the iceberg table , we get the file already closed error. 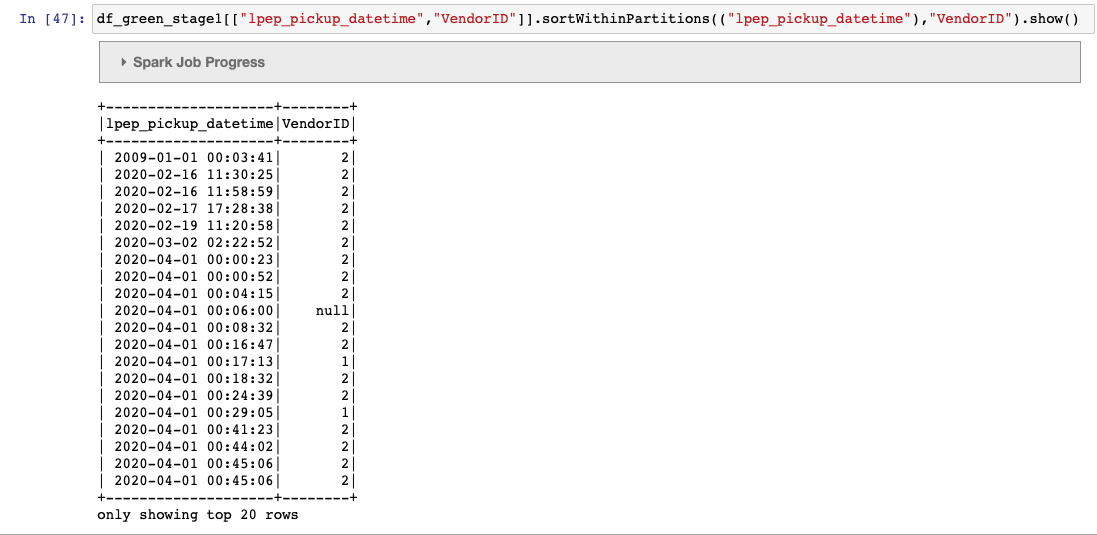 Is this a bug ? any work arounds (other than adding an additional date column and using that in the sort) ? -------- An error was encountered: An error occurred while calling o294.append. : org.apache.spark.SparkException: Writing job aborted. at org.apache.spark.sql.execution.datasources.v2.V2TableWriteExec.writeWithV2(WriteToDataSourceV2Exec.scala:388) at org.apache.spark.sql.execution.datasources.v2.V2TableWriteExec.writeWithV2$(WriteToDataSourceV2Exec.scala:336) at org.apache.spark.sql.execution.datasources.v2.AppendDataExec.writeWithV2(WriteToDataSourceV2Exec.scala:218) at org.apache.spark.sql.execution.datasources.v2.AppendDataExec.run(WriteToDataSourceV2Exec.scala:225) at org.apache.spark.sql.execution.datasources.v2.V2CommandExec.result$lzycompute(V2CommandExec.scala:40) at org.apache.spark.sql.execution.datasources.v2.V2CommandExec.result(V2CommandExec.scala:40) at org.apache.spark.sql.execution.datasources.v2.V2CommandExec.doExecute(V2CommandExec.scala:55) at org.apache.spark.sql.execution.SparkPlan.$anonfun$execute$1(SparkPlan.scala:194) at org.apache.spark.sql.execution.SparkPlan.$anonfun$executeQuery$1(SparkPlan.scala:232) at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151) at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:229) at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:190) at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:134) at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:133) at org.apache.spark.sql.DataFrameWriterV2.$anonfun$runCommand$1(DataFrameWriterV2.scala:196) at org.apache.spark.sql.catalyst.QueryPlanningTracker$.withTracker(QueryPlanningTracker.scala:107) at org.apache.spark.sql.execution.SQLExecution$.withTracker(SQLExecution.scala:232) at org.apache.spark.sql.execution.SQLExecution$.executeQuery$1(SQLExecution.scala:110) at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$6(SQLExecution.scala:135) at org.apache.spark.sql.catalyst.QueryPlanningTracker$.withTracker(QueryPlanningTracker.scala:107) at org.apache.spark.sql.execution.SQLExecution$.withTracker(SQLExecution.scala:232) at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$5(SQLExecution.scala:135) at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:253) at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.scala:134) at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:775) at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:68) at org.apache.spark.sql.DataFrameWriterV2.runCommand(DataFrameWriterV2.scala:196) at org.apache.spark.sql.DataFrameWriterV2.append(DataFrameWriterV2.scala:149) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244) at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357) at py4j.Gateway.invoke(Gateway.java:282) at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132) at py4j.commands.CallCommand.execute(CallCommand.java:79) at py4j.GatewayConnection.run(GatewayConnection.java:238) at java.lang.Thread.run(Thread.java:750) Caused by: org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 32.0 failed 4 times, most recent failure: Lost task 0.3 in stage 32.0 (TID 103) (ip-172-31-21-243.ec2.internal executor 18): java.lang.IllegalStateException: Incoming records violate the writer assumption that records are clustered by spec and by partition within each spec. Either cluster the incoming records or switch to fanout writers. Encountered records that belong to already closed files: partition 'lpep_pickup_datetime_day=2020-04-01/VendorID=2' in spec [ 1000: lpep_pickup_datetime_day: day(2) 1001: VendorID: identity(1) ] at org.apache.iceberg.io.ClusteredWriter.write(ClusteredWriter.java:95) at org.apache.iceberg.io.ClusteredDataWriter.write(ClusteredDataWriter.java:34) at org.apache.iceberg.spark.source.SparkWrite$PartitionedDataWriter.write(SparkWrite.java:629) at org.apache.iceberg.spark.source.SparkWrite$PartitionedDataWriter.write(SparkWrite.java:604) at org.apache.spark.sql.execution.datasources.v2.DataWritingSparkTask$.$anonfun$run$1(WriteToDataSourceV2Exec.scala:416) at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:1473) at org.apache.spark.sql.execution.datasources.v2.DataWritingSparkTask$.run(WriteToDataSourceV2Exec.scala:452) at org.apache.spark.sql.execution.datasources.v2.V2TableWriteExec.$anonfun$writeWithV2$2(WriteToDataSourceV2Exec.scala:360) at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90) at org.apache.spark.scheduler.Task.run(Task.scala:131) at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:497) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1439) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:500) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:750) Driver stacktrace: at org.apache.spark.scheduler.DAGScheduler.failJobAndIndependentStages(DAGScheduler.scala:2470) at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2(DAGScheduler.scala:2419) at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2$adapted(DAGScheduler.scala:2418) at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62) at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55) at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49) at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:2418) at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1(DAGScheduler.scala:1125) at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1$adapted(DAGScheduler.scala:1125) at scala.Option.foreach(Option.scala:407) at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:1125) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2684) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2626) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2615) at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49) at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:914) at org.apache.spark.SparkContext.runJob(SparkContext.scala:2241) at org.apache.spark.sql.execution.datasources.v2.V2TableWriteExec.writeWithV2(WriteToDataSourceV2Exec.scala:357) ... 38 more Caused by: java.lang.IllegalStateException: Incoming records violate the writer assumption that records are clustered by spec and by partition within each spec. Either cluster the incoming records or switch to fanout writers. Encountered records that belong to already closed files: partition 'lpep_pickup_datetime_day=2020-04-01/VendorID=2' in spec [ 1000: lpep_pickup_datetime_day: day(2) 1001: VendorID: identity(1) ] at org.apache.iceberg.io.ClusteredWriter.write(ClusteredWriter.java:95) at org.apache.iceberg.io.ClusteredDataWriter.write(ClusteredDataWriter.java:34) at org.apache.iceberg.spark.source.SparkWrite$PartitionedDataWriter.write(SparkWrite.java:629) at org.apache.iceberg.spark.source.SparkWrite$PartitionedDataWriter.write(SparkWrite.java:604) at org.apache.spark.sql.execution.datasources.v2.DataWritingSparkTask$.$anonfun$run$1(WriteToDataSourceV2Exec.scala:416) at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:1473) at org.apache.spark.sql.execution.datasources.v2.DataWritingSparkTask$.run(WriteToDataSourceV2Exec.scala:452) at org.apache.spark.sql.execution.datasources.v2.V2TableWriteExec.$anonfun$writeWithV2$2(WriteToDataSourceV2Exec.scala:360) at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90) at org.apache.spark.scheduler.Task.run(Task.scala:131) at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:497) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1439) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:500) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ... 1 more Traceback (most recent call last): File "/usr/lib/spark/python/lib/pyspark.zip/pyspark/sql/readwriter.py", line 1564, in append self._jwriter.append() File "/usr/lib/spark/python/lib/py4j-0.10.9-src.zip/py4j/java_gateway.py", line 1305, in __call__ answer, self.gateway_client, self.target_id, self.name) File "/usr/lib/spark/python/lib/pyspark.zip/pyspark/sql/utils.py", line 111, in deco return f(*a, **kw) File "/usr/lib/spark/python/lib/py4j-0.10.9-src.zip/py4j/protocol.py", line 328, in get_return_value format(target_id, ".", name), value) py4j.protocol.Py4JJavaError: An error occurred while calling o294.append. : org.apache.spark.SparkException: Writing job aborted. at org.apache.spark.sql.execution.datasources.v2.V2TableWriteExec.writeWithV2(WriteToDataSourceV2Exec.scala:388) at org.apache.spark.sql.execution.datasources.v2.V2TableWriteExec.writeWithV2$(WriteToDataSourceV2Exec.scala:336) at org.apache.spark.sql.execution.datasources.v2.AppendDataExec.writeWithV2(WriteToDataSourceV2Exec.scala:218) at org.apache.spark.sql.execution.datasources.v2.AppendDataExec.run(WriteToDataSourceV2Exec.scala:225) at org.apache.spark.sql.execution.datasources.v2.V2CommandExec.result$lzycompute(V2CommandExec.scala:40) at org.apache.spark.sql.execution.datasources.v2.V2CommandExec.result(V2CommandExec.scala:40) at org.apache.spark.sql.execution.datasources.v2.V2CommandExec.doExecute(V2CommandExec.scala:55) at org.apache.spark.sql.execution.SparkPlan.$anonfun$execute$1(SparkPlan.scala:194) at org.apache.spark.sql.execution.SparkPlan.$anonfun$executeQuery$1(SparkPlan.scala:232) at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151) at org.apache.spark.sql.execution.SparkPlan.executeQuery(SparkPlan.scala:229) at org.apache.spark.sql.execution.SparkPlan.execute(SparkPlan.scala:190) at org.apache.spark.sql.execution.QueryExecution.toRdd$lzycompute(QueryExecution.scala:134) at org.apache.spark.sql.execution.QueryExecution.toRdd(QueryExecution.scala:133) at org.apache.spark.sql.DataFrameWriterV2.$anonfun$runCommand$1(DataFrameWriterV2.scala:196) at org.apache.spark.sql.catalyst.QueryPlanningTracker$.withTracker(QueryPlanningTracker.scala:107) at org.apache.spark.sql.execution.SQLExecution$.withTracker(SQLExecution.scala:232) at org.apache.spark.sql.execution.SQLExecution$.executeQuery$1(SQLExecution.scala:110) at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$6(SQLExecution.scala:135) at org.apache.spark.sql.catalyst.QueryPlanningTracker$.withTracker(QueryPlanningTracker.scala:107) at org.apache.spark.sql.execution.SQLExecution$.withTracker(SQLExecution.scala:232) at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$5(SQLExecution.scala:135) at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:253) at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.scala:134) at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:775) at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:68) at org.apache.spark.sql.DataFrameWriterV2.runCommand(DataFrameWriterV2.scala:196) at org.apache.spark.sql.DataFrameWriterV2.append(DataFrameWriterV2.scala:149) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244) at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357) at py4j.Gateway.invoke(Gateway.java:282) at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132) at py4j.commands.CallCommand.execute(CallCommand.java:79) at py4j.GatewayConnection.run(GatewayConnection.java:238) at java.lang.Thread.run(Thread.java:750) Caused by: org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 32.0 failed 4 times, most recent failure: Lost task 0.3 in stage 32.0 (TID 103) (ip-172-31-21-243.ec2.internal executor 18): java.lang.IllegalStateException: Incoming records violate the writer assumption that records are clustered by spec and by partition within each spec. Either cluster the incoming records or switch to fanout writers. Encountered records that belong to already closed files: partition 'lpep_pickup_datetime_day=2020-04-01/VendorID=2' in spec [ 1000: lpep_pickup_datetime_day: day(2) 1001: VendorID: identity(1) ] at org.apache.iceberg.io.ClusteredWriter.write(ClusteredWriter.java:95) at org.apache.iceberg.io.ClusteredDataWriter.write(ClusteredDataWriter.java:34) at org.apache.iceberg.spark.source.SparkWrite$PartitionedDataWriter.write(SparkWrite.java:629) at org.apache.iceberg.spark.source.SparkWrite$PartitionedDataWriter.write(SparkWrite.java:604) at org.apache.spark.sql.execution.datasources.v2.DataWritingSparkTask$.$anonfun$run$1(WriteToDataSourceV2Exec.scala:416) at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:1473) at org.apache.spark.sql.execution.datasources.v2.DataWritingSparkTask$.run(WriteToDataSourceV2Exec.scala:452) at org.apache.spark.sql.execution.datasources.v2.V2TableWriteExec.$anonfun$writeWithV2$2(WriteToDataSourceV2Exec.scala:360) at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90) at org.apache.spark.scheduler.Task.run(Task.scala:131) at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:497) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1439) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:500) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:750) Driver stacktrace: at org.apache.spark.scheduler.DAGScheduler.failJobAndIndependentStages(DAGScheduler.scala:2470) at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2(DAGScheduler.scala:2419) at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2$adapted(DAGScheduler.scala:2418) at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62) at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55) at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49) at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:2418) at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1(DAGScheduler.scala:1125) at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1$adapted(DAGScheduler.scala:1125) at scala.Option.foreach(Option.scala:407) at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:1125) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2684) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2626) at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2615) at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49) at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:914) at org.apache.spark.SparkContext.runJob(SparkContext.scala:2241) at org.apache.spark.sql.execution.datasources.v2.V2TableWriteExec.writeWithV2(WriteToDataSourceV2Exec.scala:357) ... 38 more Caused by: java.lang.IllegalStateException: Incoming records violate the writer assumption that records are clustered by spec and by partition within each spec. Either cluster the incoming records or switch to fanout writers. Encountered records that belong to already closed files: partition 'lpep_pickup_datetime_day=2020-04-01/VendorID=2' in spec [ 1000: lpep_pickup_datetime_day: day(2) 1001: VendorID: identity(1) ] at org.apache.iceberg.io.ClusteredWriter.write(ClusteredWriter.java:95) at org.apache.iceberg.io.ClusteredDataWriter.write(ClusteredDataWriter.java:34) at org.apache.iceberg.spark.source.SparkWrite$PartitionedDataWriter.write(SparkWrite.java:629) at org.apache.iceberg.spark.source.SparkWrite$PartitionedDataWriter.write(SparkWrite.java:604) at org.apache.spark.sql.execution.datasources.v2.DataWritingSparkTask$.$anonfun$run$1(WriteToDataSourceV2Exec.scala:416) at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:1473) at org.apache.spark.sql.execution.datasources.v2.DataWritingSparkTask$.run(WriteToDataSourceV2Exec.scala:452) at org.apache.spark.sql.execution.datasources.v2.V2TableWriteExec.$anonfun$writeWithV2$2(WriteToDataSourceV2Exec.scala:360) at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90) at org.apache.spark.scheduler.Task.run(Task.scala:131) at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:497) at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1439) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:500) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ... 1 more ------- -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected] --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}