eric666666 commented on issue #4471: URL: https://github.com/apache/iceberg/issues/4471#issuecomment-1086568496
When we use upon spark sql statements ,we found that Spark job will block on the last task of stage. 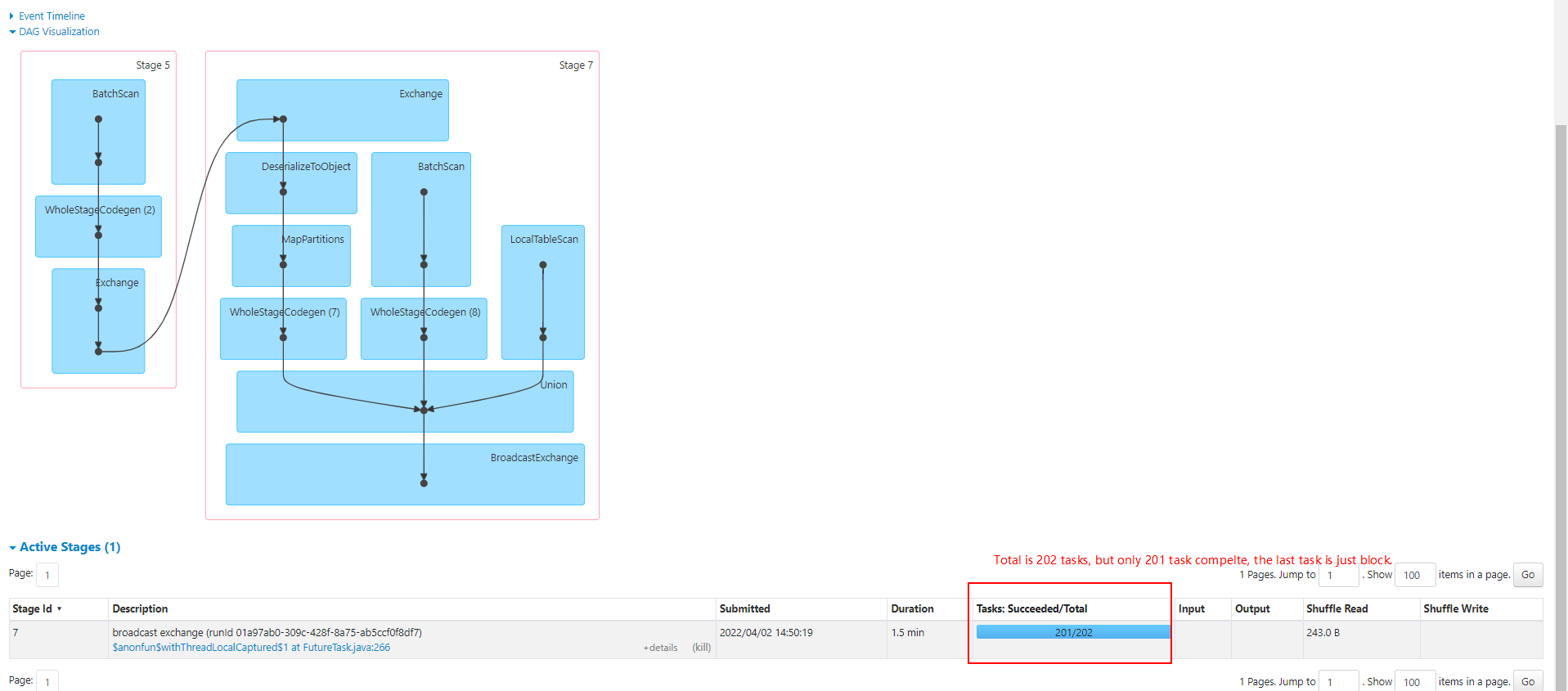 We printed full thread information about locks. `"main" #1 prio=5 os_prio=0 tid=0x0000000002f79800 nid=0x1bd4 waiting on condition [0x0000000002f1c000] java.lang.Thread.State: WAITING (parking) at sun.misc.Unsafe.park(Native Method) - parking to wait for <0x00000004c7b1bf38> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject) at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175) at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039) at java.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:442) at org.apache.spark.sql.execution.adaptive.AdaptiveSparkPlanExec.$anonfun$getFinalPhysicalPlan$1(AdaptiveSparkPlanExec.scala:273) at org.apache.spark.sql.execution.adaptive.AdaptiveSparkPlanExec$$Lambda$2268/608590206.apply(Unknown Source) at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:775) at org.apache.spark.sql.execution.adaptive.AdaptiveSparkPlanExec.getFinalPhysicalPlan(AdaptiveSparkPlanExec.scala:226) - locked <0x00000004c7fa0240> (a java.lang.Object) at org.apache.spark.sql.execution.adaptive.AdaptiveSparkPlanExec.withFinalPlanUpdate(AdaptiveSparkPlanExec.scala:365) at org.apache.spark.sql.execution.adaptive.AdaptiveSparkPlanExec.executeCollect(AdaptiveSparkPlanExec.scala:338) at org.apache.spark.sql.Dataset.collectFromPlan(Dataset.scala:3715) at org.apache.spark.sql.Dataset.$anonfun$collectAsList$1(Dataset.scala:2983) at org.apache.spark.sql.Dataset$$Lambda$1843/857865061.apply(Unknown Source) at org.apache.spark.sql.Dataset.$anonfun$withAction$1(Dataset.scala:3706) at org.apache.spark.sql.Dataset$$Lambda$1844/1920110923.apply(Unknown Source) at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$5(SQLExecution.scala:103) at org.apache.spark.sql.execution.SQLExecution$$$Lambda$1289/993347235.apply(Unknown Source) at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:163) at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.scala:90) at org.apache.spark.sql.execution.SQLExecution$$$Lambda$1282/2074109190.apply(Unknown Source) at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:775) at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:64) at org.apache.spark.sql.Dataset.withAction(Dataset.scala:3704) at org.apache.spark.sql.Dataset.collectAsList(Dataset.scala:2982) at org.apache.iceberg.spark.actions.BaseExpireSnapshotsSparkAction.doExecute(BaseExpireSnapshotsSparkAction.java:219) at org.apache.iceberg.spark.actions.BaseExpireSnapshotsSparkAction$$Lambda$1503/1268892066.get(Unknown Source) at org.apache.iceberg.spark.actions.BaseSparkAction.withJobGroupInfo(BaseSparkAction.java:98) at org.apache.iceberg.spark.actions.BaseExpireSnapshotsSparkAction.execute(BaseExpireSnapshotsSparkAction.java:188) at org.apache.iceberg.spark.actions.BaseExpireSnapshotsSparkAction.execute(BaseExpireSnapshotsSparkAction.java:68) at org.apache.iceberg.spark.procedures.ExpireSnapshotsProcedure.lambda$call$0(ExpireSnapshotsProcedure.java:110) at org.apache.iceberg.spark.procedures.ExpireSnapshotsProcedure$$Lambda$1488/961628534.apply(Unknown Source) at org.apache.iceberg.spark.procedures.BaseProcedure.execute(BaseProcedure.java:85) at org.apache.iceberg.spark.procedures.BaseProcedure.modifyIcebergTable(BaseProcedure.java:74) at org.apache.iceberg.spark.procedures.ExpireSnapshotsProcedure.call(ExpireSnapshotsProcedure.java:95) at org.apache.spark.sql.execution.datasources.v2.CallExec.run(CallExec.scala:33) at org.apache.spark.sql.execution.datasources.v2.V2CommandExec.result$lzycompute(V2CommandExec.scala:43) - locked <0x00000004c48c0cc0> (a org.apache.spark.sql.execution.datasources.v2.CallExec) at org.apache.spark.sql.execution.datasources.v2.V2CommandExec.result(V2CommandExec.scala:43) at org.apache.spark.sql.execution.datasources.v2.V2CommandExec.executeCollect(V2CommandExec.scala:49) at org.apache.spark.sql.execution.QueryExecution$$anonfun$eagerlyExecuteCommands$1.$anonfun$applyOrElse$1(QueryExecution.scala:110) at org.apache.spark.sql.execution.QueryExecution$$anonfun$eagerlyExecuteCommands$1$$Lambda$1281/1519216494.apply(Unknown Source) at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$5(SQLExecution.scala:103) at org.apache.spark.sql.execution.SQLExecution$$$Lambda$1289/993347235.apply(Unknown Source) at org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:163) at org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.scala:90) at org.apache.spark.sql.execution.SQLExecution$$$Lambda$1282/2074109190.apply(Unknown Source) at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:775) at org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:64) at org.apache.spark.sql.execution.QueryExecution$$anonfun$eagerlyExecuteCommands$1.applyOrElse(QueryExecution.scala:110) at org.apache.spark.sql.execution.QueryExecution$$anonfun$eagerlyExecuteCommands$1.applyOrElse(QueryExecution.scala:106) at org.apache.spark.sql.catalyst.trees.TreeNode.$anonfun$transformDownWithPruning$1(TreeNode.scala:481) at org.apache.spark.sql.catalyst.trees.TreeNode$$Lambda$1002/771715205.apply(Unknown Source) at org.apache.spark.sql.catalyst.trees.CurrentOrigin$.withOrigin(TreeNode.scala:82) at org.apache.spark.sql.catalyst.trees.TreeNode.transformDownWithPruning(TreeNode.scala:481) at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.org$apache$spark$sql$catalyst$plans$logical$AnalysisHelper$$super$transformDownWithPruning(LogicalPlan .scala:30) at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning(AnalysisHelper.scala:267) at org.apache.spark.sql.catalyst.plans.logical.AnalysisHelper.transformDownWithPruning$(AnalysisHelper.scala:263) at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:30) at org.apache.spark.sql.catalyst.plans.logical.LogicalPlan.transformDownWithPruning(LogicalPlan.scala:30) at org.apache.spark.sql.catalyst.trees.TreeNode.transformDown(TreeNode.scala:457) at org.apache.spark.sql.execution.QueryExecution.eagerlyExecuteCommands(QueryExecution.scala:106) at org.apache.spark.sql.execution.QueryExecution.commandExecuted$lzycompute(QueryExecution.scala:93) - locked <0x00000004c4646e88> (a org.apache.spark.sql.execution.QueryExecution) at org.apache.spark.sql.execution.QueryExecution.commandExecuted(QueryExecution.scala:91) at org.apache.spark.sql.Dataset.<init>(Dataset.scala:219) at org.apache.spark.sql.Dataset$.$anonfun$ofRows$2(Dataset.scala:99) at org.apache.spark.sql.Dataset$$$Lambda$828/2128310218.apply(Unknown Source) at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:775) at org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:96) at org.apache.spark.sql.SparkSession.$anonfun$sql$1(SparkSession.scala:618) at org.apache.spark.sql.SparkSession$$Lambda$716/1165568071.apply(Unknown Source) at org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:775) at org.apache.spark.sql.SparkSession.sql(SparkSession.scala:613) at com.eric.icebergspark.CallCommand.ExpireSnapshot$.$anonfun$main$1(ExpireSnapshot.scala:71) at com.eric.icebergspark.CallCommand.ExpireSnapshot$.$anonfun$main$1$adapted(ExpireSnapshot.scala:72) at com.eric.icebergspark.CallCommand.ExpireSnapshot$$$Lambda$715/903064416.apply(Unknown Source) at scala.collection.IndexedSeqOptimized.foreach(IndexedSeqOptimized.scala:36) at scala.collection.IndexedSeqOptimized.foreach$(IndexedSeqOptimized.scala:33) at scala.collection.mutable.ArrayOps$ofRef.foreach(ArrayOps.scala:198) at com.eric.icebergspark.call.ExpireSnapshot$.main(ExpireSnapshot.scala:72) at com.eric.icebergspark.call.ExpireSnapshot.main(ExpireSnapshot.scala) ` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected] --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]
{kind=link}