hililiwei opened a new pull request, #4904: URL: https://github.com/apache/iceberg/pull/4904
## What is the purpose of the change The following is the background and basis for this PR: - [FLIP-143: Unified Sink API](https://cwiki.apache.org/confluence/display/FLINK/FLIP-143%3A+Unified+Sink+API) - [FLIP-191: Extend unified Sink interface to support small file compaction](https://cwiki.apache.org/confluence/display/FLINK/FLIP-191%3A+Extend+unified+Sink+interface+to+support+small+file+compaction) 1. FLIP-143: Unified Sink API The Unified Sink API was introduced by FLink in version 1.12, and its motivation is mainly as follows: > As discussed in FLIP-131, Flink will deprecate the DataSet API in favor of DataStream API and Table API. Users should be able to use DataStream API to write jobs that support both bounded and unbounded execution modes. However Flink does not provide a sink API to guarantee the exactly once semantics in both bounded and unbounded scenarios, which blocks the unification. > > So we want to introduce a new unified sink API which could let the user develop sink once and run it everywhere. Specifically Flink allows the user to > > Choose the different SDK(SQL/Table/DataStream) Choose the different execution mode(Batch/Stream) according to the scenarios(bounded/unbounded) We hope these things(SDK/Execution mode) are transparent to the sink API. This is the main change point of this PR. It retains most of the underlying logic, provides a V2 version of FlinkSink externally, and tries to minimize the impact of this change on users' experience. After this PR is completed, we can try to contact Flink community to see if it is possible to directly include this new Sink into Flink repo and exist as a separate Connector. For the above two FLIP and some other reasons, I think we should implement our Sink based on the latest API, which is clearer in structure, and this helps keep us in line with Flink.. 2. FLIP-191: Extend unified Sink interface to support small file compaction I think this illustration is very clear. 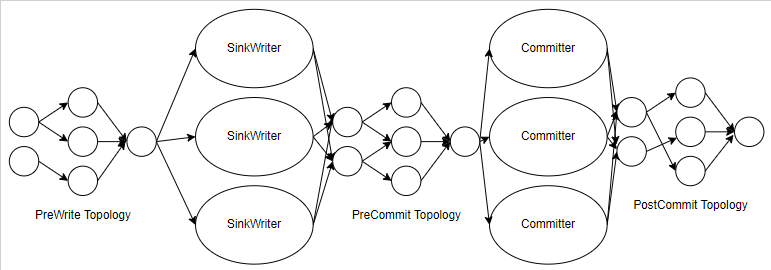 I'm going to do this in a separate PR because it's a bit of a performance bottleneck when we're dealing with a lot of data in production. If possible, I would like to raise PR after those issues are resolved. ## Brief change log 1. Add new flink sink base on [FLIP-143: Unified Sink API](https://cwiki.apache.org/confluence/display/FLINK/FLIP-143%3A+Unified+Sink+API) and [FLIP-191: Extend unified Sink interface to support small file compaction](https://cwiki.apache.org/confluence/display/FLINK/FLIP-191%3A+Extend+unified+Sink+interface+to+support+small+file+compaction) 2. `Iceberg Table Sink` uses the new sink instead of the old one. ## Verifying this change 1. Use existing unit tests. 2. Add some new ## To do 1. Unit tests to cover more case 2. Small file merge -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected] --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]
{kind=link}