hililiwei opened a new pull request, #5061:
URL: https://github.com/apache/iceberg/pull/5061
### Reappear
```sql
CREATE TABLE upsert_test (
`id` STRING UNIQUE COMMENT 'unique id',
`data` STRING NOT NULL,
PRIMARY KEY(`id`) NOT ENFORCED
) with ('format-version'='2', 'write.upsert.enabled'='true');
insert into upsert_test values ('1','20220507'),
('2','20220504'),('6','20220505');
CREATE TABLE upsert_sample (
`id` STRING UNIQUE COMMENT 'unique id',
`data` STRING NOT NULL,
PRIMARY KEY(`id`) NOT ENFORCED
) with ('format-version'='2', 'write.upsert.enabled'='true');
insert into upsert_sample values
('1','20220607'),('2','20220503'),('3','20220505');
insert into upsert_test
select
t1.id as id,
t1.data as data
from upsert_sample t1 left join upsert_test t2
on t1.id = t2.id
where t1.data > t2.data or t2.data is null;
```
Expected Results
```
id data
1 20220607
3 20220505
6 20220505
2 20220504
```
Actual Results
```
id data
1 20220607
3 20220505
6 20220505
```
or
```
id data
1 20220607
3 20220505
3 20220505
6 20220505
```
………………
**Note: This occurs occasionally.**
### Reason:
When we write data in this way, we get not only the result data, but all the
cdc data.
the above sql obviously didn't mean that, the CDC data caused the table
result to be abnormal.
Let's look at what happens when the ID2 data disappears.
look following SQL first:
```sql
select t1.id as id ,t1.data as data from upsert_sample t1 left join
upsert_test t2 on t1.id = t2.id where t1.data > t2.data or t2.data is null
```
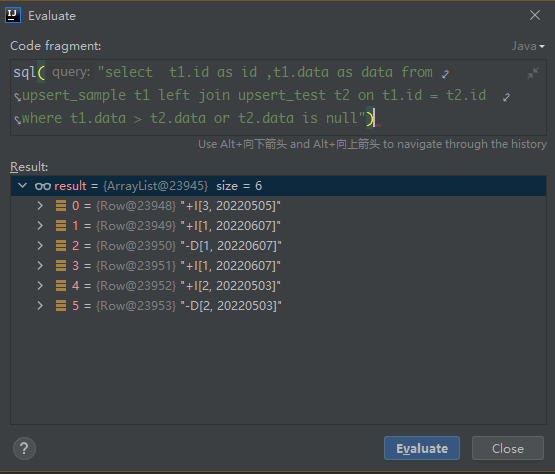
upsert_test data file:
```
**upsert_test/metadata**
$ java -jar /d/tools/iceberg-tools-1.0-SNAPSHOT.jar manifest2json
28dfde75-110d-409a-93fb-39dbf0daf99e-m1.avro v3.metadata.json
log4j:WARN No appenders could be found for logger
(org.apache.hadoop.metrics2.lib.MutableMetricsFactory).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for
more info.
[
{"status":1,"snapshot_id":{"long":5799541658712377255},"sequence_number":null,"data_file":{"content":2,"file_path":"file:/C:/Users/L00561~1/AppData/Local/Temp/junit1644645413478420150/default/db/upsert_test/data/00000-0-f39bdce9-96cc-46cf-adb8-9e84a0577ef2-00002.avro","file_format":"AVRO","partition":{},"record_count":2,"file_size_in_bytes":317,"column_sizes":null,"value_counts":null,"null_value_counts":null,"nan_value_counts":null,"lower_bounds":null,"upper_bounds":null,"key_metadata":null,"split_offsets":null,"equality_ids":{"array":[1]},"sort_order_id":{"int":0}}},
{"status":1,"snapshot_id":{"long":5799541658712377255},"sequence_number":null,"data_file":{"content":1,"file_path":"file:/C:/Users/L00561~1/AppData/Local/Temp/junit1644645413478420150/default/db/upsert_test/data/00000-0-f39bdce9-96cc-46cf-adb8-9e84a0577ef2-00003.avro","file_format":"AVRO","partition":{},"record_count":1,"file_size_in_bytes":801,"column_sizes":null,"value_counts":null,"null_value_counts":null,"nan_value_counts":null,"lower_bounds":null,"upper_bounds":null,"key_metadata":null,"split_offsets":null,"equality_ids":null,"sort_order_id":null}},
{"status":1,"snapshot_id":{"long":5799541658712377255},"sequence_number":null,"data_file":{"content":2,"file_path":"file:/C:/Users/L00561~1/AppData/Local/Temp/junit1644645413478420150/default/db/upsert_test/data/00001-0-683475d0-066a-48f2-96c9-52e4cb481fca-00002.avro","file_format":"AVRO","partition":{},"record_count":2,"file_size_in_bytes":317,"column_sizes":null,"value_counts":null,"null_value_counts":null,"nan_value_counts":null,"lower_bounds":null,"upper_bounds":null,"key_metadata":null,"split_offsets":null,"equality_ids":{"array":[1]},"sort_order_id":{"int":0}}},
{"status":1,"snapshot_id":{"long":5799541658712377255},"sequence_number":null,"data_file":{"content":1,"file_path":"file:/C:/Users/L00561~1/AppData/Local/Temp/junit1644645413478420150/default/db/upsert_test/data/00001-0-683475d0-066a-48f2-96c9-52e4cb481fca-00003.avro","file_format":"AVRO","partition":{},"record_count":1,"file_size_in_bytes":800,"column_sizes":null,"value_counts":null,"null_value_counts":null,"nan_value_counts":null,"lower_bounds":null,"upper_bounds":null,"key_metadata":null,"split_offsets":null,"equality_ids":null,"sort_order_id":null}}
]
$ java -jar /d/tools/iceberg-tools-1.0-SNAPSHOT.jar manifest2json
28dfde75-110d-409a-93fb-39dbf0daf99e-m0.avro v3.metadata.json
log4j:WARN No appenders could be found for logger
(org.apache.hadoop.metrics2.lib.MutableMetricsFactory).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for
more info.
[
{"status":1,"snapshot_id":{"long":5799541658712377255},"sequence_number":null,"data_file":{"content":0,"file_path":"file:/C:/Users/L00561~1/AppData/Local/Temp/junit1644645413478420150/default/db/upsert_test/data/00000-0-f39bdce9-96cc-46cf-adb8-9e84a0577ef2-00001.avro","file_format":"AVRO","partition":{},"record_count":2,"file_size_in_bytes":413,"column_sizes":null,"value_counts":null,"null_value_counts":null,"nan_value_counts":null,"lower_bounds":null,"upper_bounds":null,"key_metadata":null,"split_offsets":null,"equality_ids":null,"sort_order_id":{"int":0}}},
{"status":1,"snapshot_id":{"long":5799541658712377255},"sequence_number":null,"data_file":{"content":0,"file_path":"file:/C:/Users/L00561~1/AppData/Local/Temp/junit1644645413478420150/default/db/upsert_test/data/00001-0-683475d0-066a-48f2-96c9-52e4cb481fca-00001.avro","file_format":"AVRO","partition":{},"record_count":2,"file_size_in_bytes":415,"column_sizes":null,"value_counts":null,"null_value_counts":null,"nan_value_counts":null,"lower_bounds":null,"upper_bounds":null,"key_metadata":null,"split_offsets":null,"equality_ids":null,"sort_order_id":{"int":0}}}
]
**upsert_test/data**
$ java -jar /d/tools/avro-tools-1.11.0.jar tojson
00001-0-683475d0-066a-48f2-96c9-52e4cb481fca-00003.avro
{"file_path":"file:/C:/Users/L00561~1/AppData/Local/Temp/junit1644645413478420150/default/db/upsert_test/data/00001-0-683475d0-066a-48f2-96c9-52e4cb481fca-00001.avro","pos":1}
$ java -jar /d/tools/avro-tools-1.11.0.jar tojson
00001-0-683475d0-066a-48f2-96c9-52e4cb481fca-00002.avro
{"id":"3"}
{"id":"2"}
$ java -jar /d/tools/avro-tools-1.11.0.jar tojson
00001-0-683475d0-066a-48f2-96c9-52e4cb481fca-00001.avro
{"id":"3","data":"20220505"}
{"id":"2","data":"20220503"}
```
https://github.com/apache/iceberg/blob/547152cf3dfa5e399351b851c48edd8f916e9c48/flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/FlinkSink.java#L418-L421
https://github.com/apache/iceberg/blob/547152cf3dfa5e399351b851c48edd8f916e9c48/flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/BaseDeltaTaskWriter.java#L76-L101
### Resolves
We are currently using the new Sink API to fix it temporarily, FYI #4904
(add a configuration that specifies whether to enable the new version sink)
But in this way, we can't get the CDC data.
In the above case, CDC conflicts with upsert. Do we have a better way to
deal with it?
### Questions:
Maybe we didn't pinpoint the real problem.
We also wanted to find a simple way to solve it.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}