SusurHe opened a new issue, #5099:
URL: https://github.com/apache/iceberg/issues/5099
Hi,
Recently, I was preparing to upgrade Spark and Iceberg, but i find it
produced a lot of small files when i perform `MERGE INTO` operation; In
previous versions(3.1 + 0.12.1), a parquet file size was 100+mb, but now it is
only 20-30mb;
i don't know I don't know what changes caused the increase of small files, I
tried some configurations of spark and iceberg, but they didn't work as well as
i wanted:
- `spark.sql.adaptive.coalescePartitions.minPartitionSize`
- `spark.sql.adaptive.advisoryPartitionSizeInBytes`
- `write.parquet.row-group-size-bytes`
- `write.target-file-size-bytes`
***How can reduce the small files of `MERGE INTO` operation, or control
their size?***
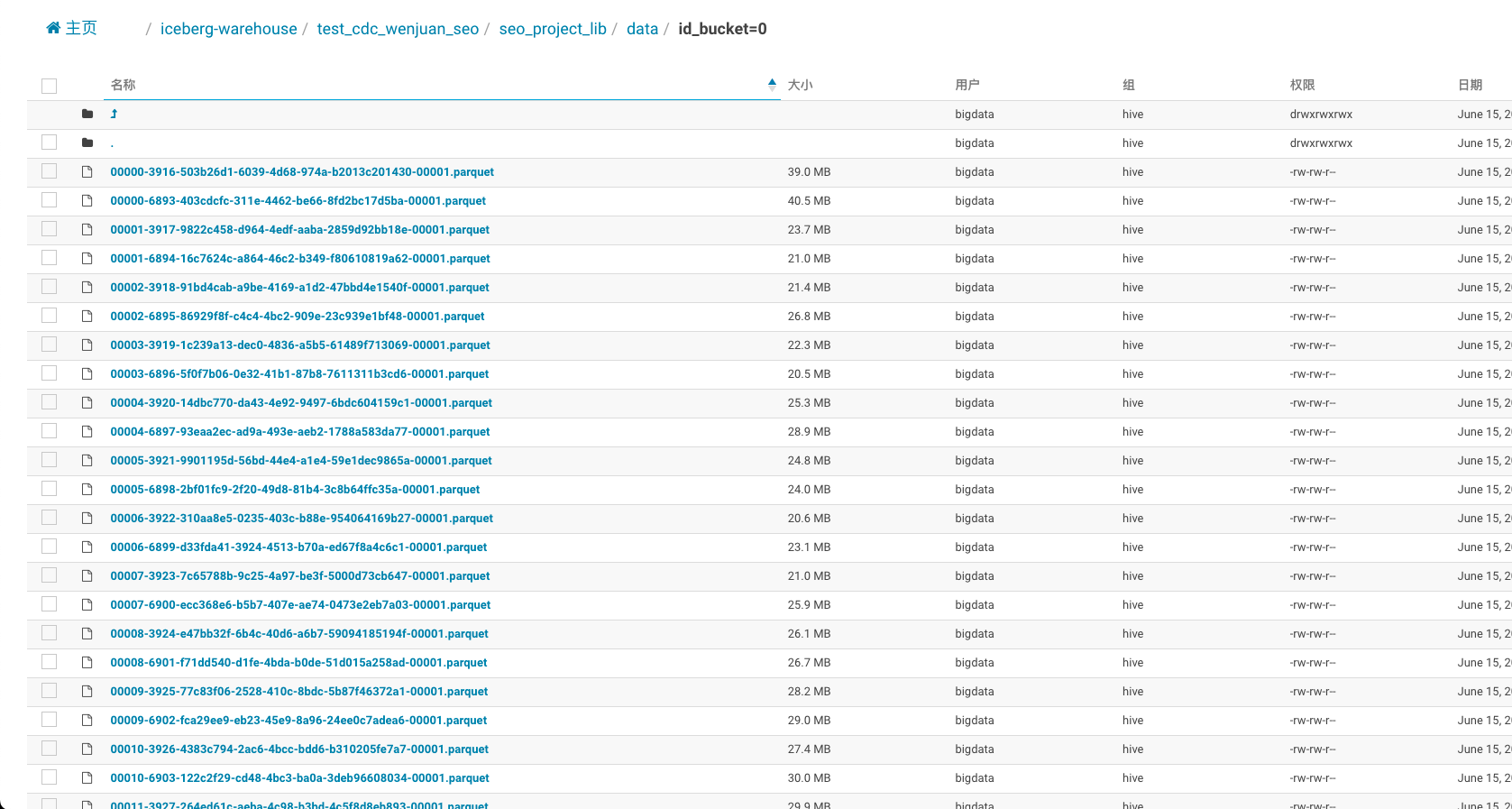
- Spark3.2 + Iceberg0.13.1 data files:
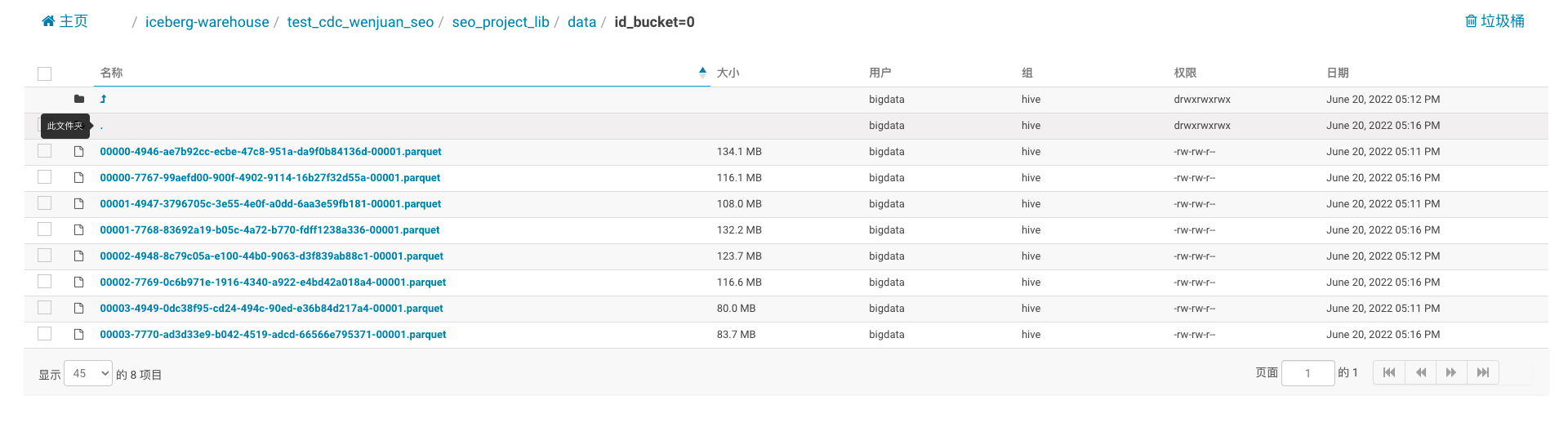
- Spark3.1 + Iceberg0.12.1 data files:
Thanks all;
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}