Reo-LEI commented on PR #5061: URL: https://github.com/apache/iceberg/pull/5061#issuecomment-1170750467
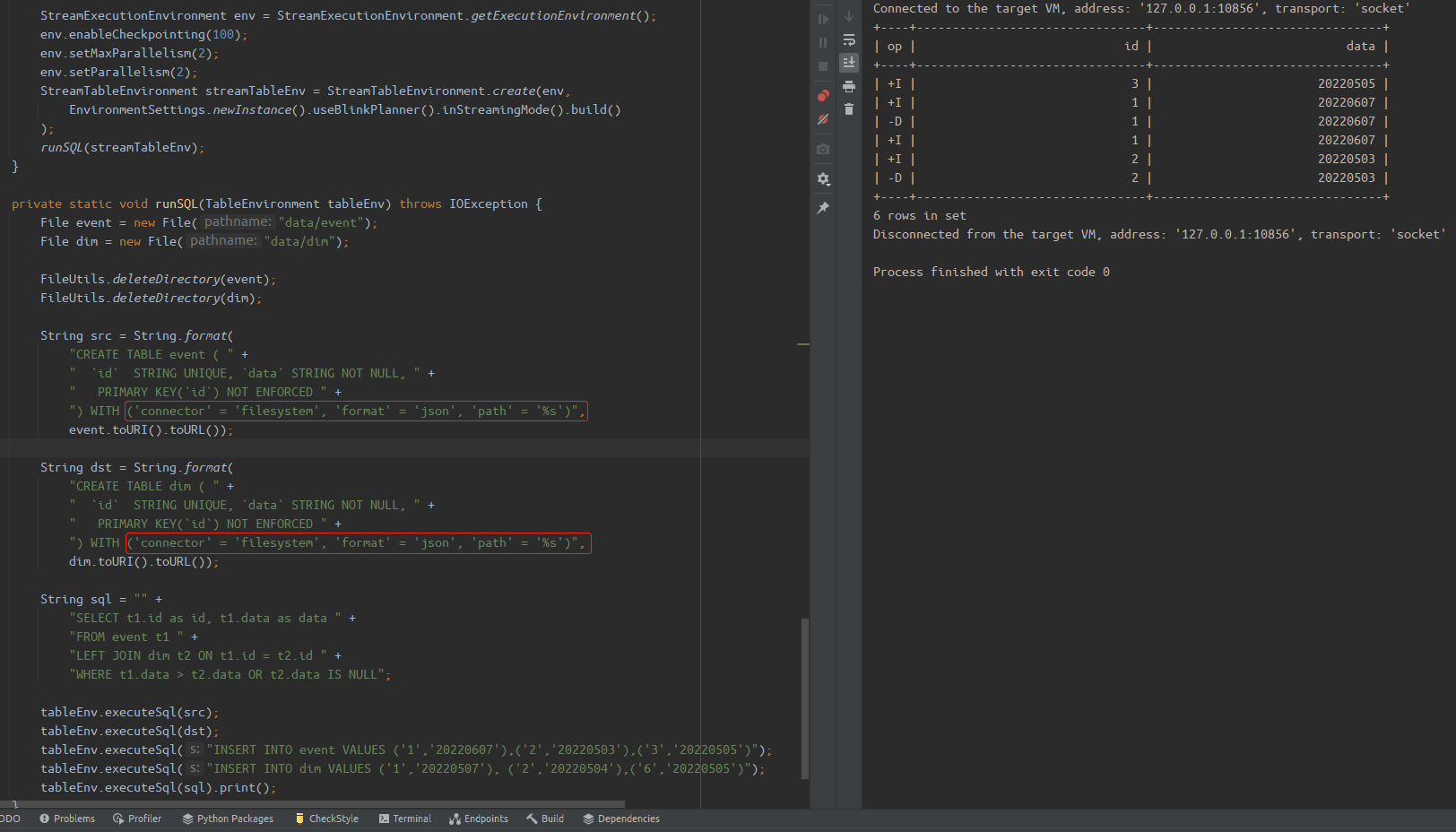 @hililiwei I reproduced this case in my local env, the `id=2` record will be deleted is Flink's behavior, has nothing to do with iceberg. And I think this record should be delete becasue the record `('2','20220503')` does not meet this filter condition `t1.data > t2.data`. So the expected final result should be `('1','20220607'), ('3','20220505')` same as the batch result. <br/> 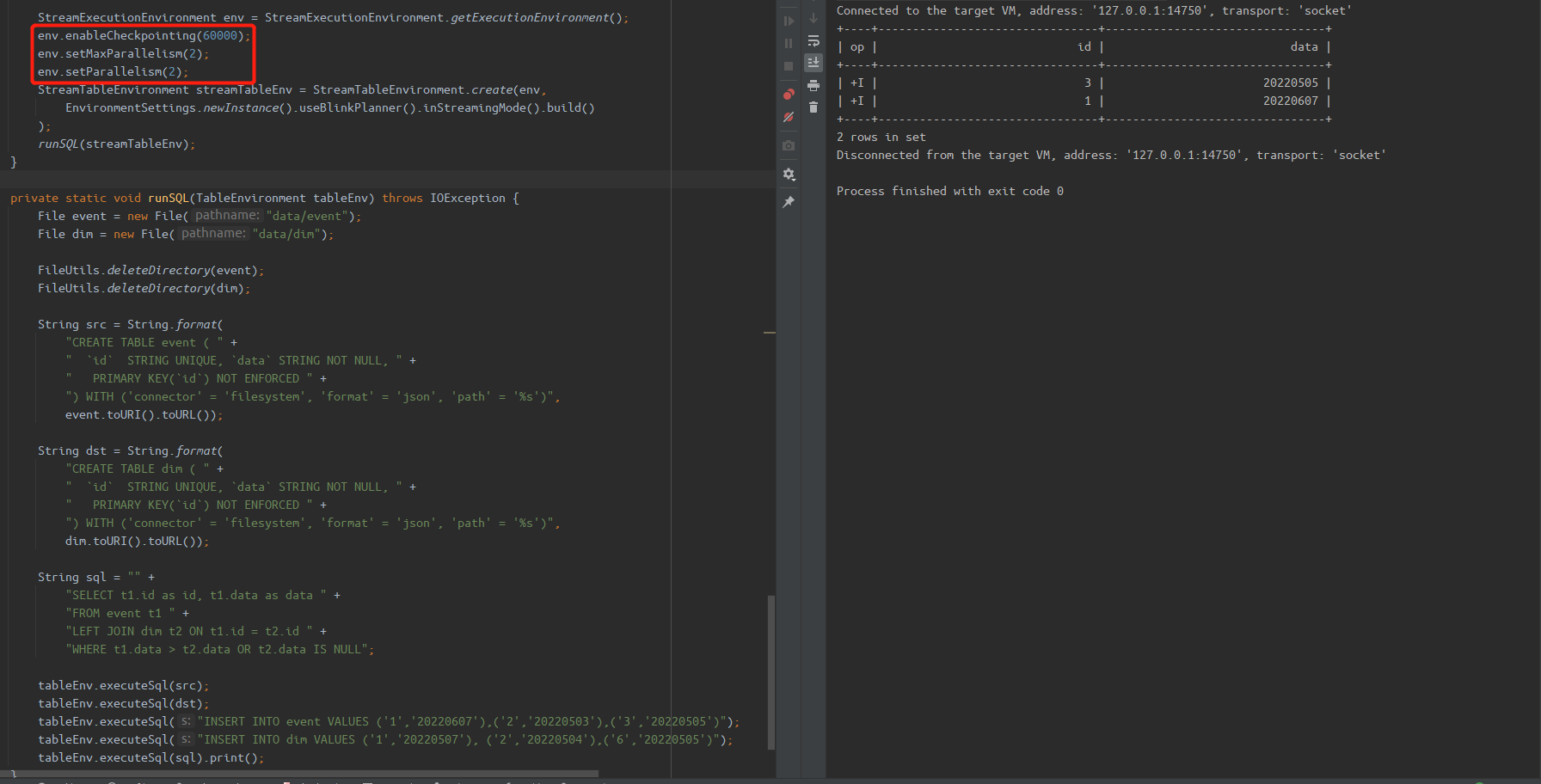 > so it is strange to have +I[2, ...] and -D[2, ...] in the join output. @rdblue If we adjust the env setting, the +I[2, ...] and -D[2, ...] will disappear occasionally. I think the occurrence of these records is related to the timing of checkpoint and the distribution of data. <br/> > As we apache iceberg format v2 don't support incremental streaming reading, then how could we accomplish this streaming read and streaming join ? @openinx Because this test only setting the env as `StreamTableEnvironment`, but there not setting the `ScanContext.isStreaming` as true(that is false by default). Therefor, the iceberg table will be scan by batch but not streaming. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected] --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}