bryanck opened a new pull request, #5225: URL: https://github.com/apache/iceberg/pull/5225
During query planning, Iceberg broadcasts table data, and Spark will run its size estimator tool on the object as part of the broadcast. This size estimation can be an expensive operation in some cases, for example, when the table uses `S3FileIO`, as the object graph being analyzed is large even if the data isn't being serialized. Ultimately this can cause performance problems in query planning. Also, the size estimate is not correct as it includes data that will not be serialized. For example, a table with an S3FileIO reference was being estimated at 16MB in size when the serialized size was only ~32KB. This PR creates a subclass of `SerializableTable` that implements Spark's `KnownSizeEstimation` trait and uses that for broadcasts. By doing this, the expensive size estimation calculation is bypassed. The size is set to 32KB, as during testing the size of the serialized data was very roughly in this ballpark. One side note - it appears as if the same table is being broadcast multiple times during query planning, so there are further opportunities for optimization in this area. 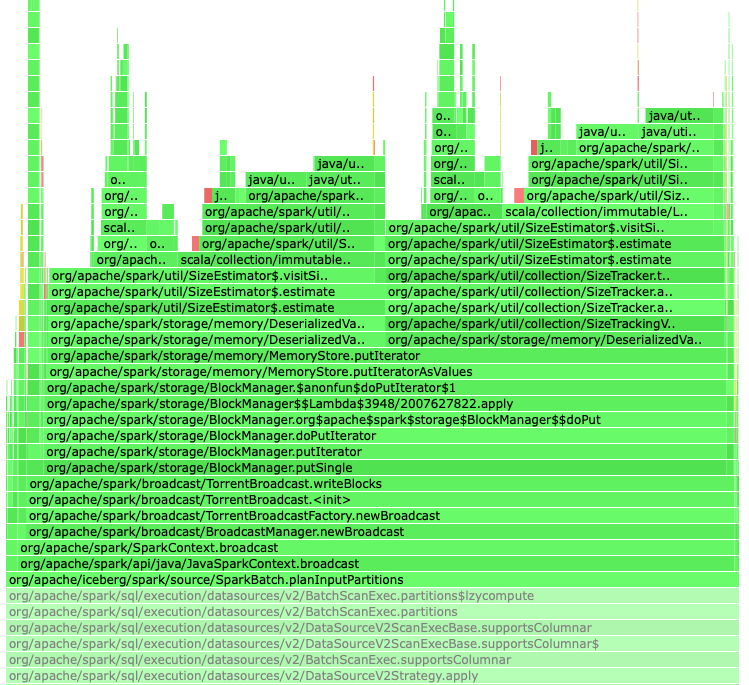 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected] --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]
{kind=link}