hililiwei commented on code in PR #4904: URL: https://github.com/apache/iceberg/pull/4904#discussion_r948762700
########## flink/v1.15/flink/src/main/java/org/apache/iceberg/flink/sink/IcebergSink.java: ########## @@ -0,0 +1,696 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one + * or more contributor license agreements. See the NOTICE file + * distributed with this work for additional information + * regarding copyright ownership. The ASF licenses this file + * to you under the Apache License, Version 2.0 (the + * "License"); you may not use this file except in compliance + * with the License. You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, + * software distributed under the License is distributed on an + * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY + * KIND, either express or implied. See the License for the + * specific language governing permissions and limitations + * under the License. + */ +package org.apache.iceberg.flink.sink; + +import static org.apache.iceberg.TableProperties.WRITE_DISTRIBUTION_MODE; + +import java.io.IOException; +import java.io.UncheckedIOException; +import java.util.Collection; +import java.util.List; +import java.util.Map; +import java.util.Set; +import java.util.function.Function; +import javax.annotation.Nullable; +import org.apache.flink.api.common.functions.MapFunction; +import org.apache.flink.api.common.functions.RichMapFunction; +import org.apache.flink.api.common.typeinfo.TypeInformation; +import org.apache.flink.api.connector.sink2.Committer; +import org.apache.flink.api.connector.sink2.StatefulSink; +import org.apache.flink.configuration.Configuration; +import org.apache.flink.configuration.ReadableConfig; +import org.apache.flink.core.io.SimpleVersionedSerializer; +import org.apache.flink.streaming.api.connector.sink2.CommittableMessage; +import org.apache.flink.streaming.api.connector.sink2.CommittableWithLineage; +import org.apache.flink.streaming.api.connector.sink2.WithPostCommitTopology; +import org.apache.flink.streaming.api.connector.sink2.WithPreCommitTopology; +import org.apache.flink.streaming.api.connector.sink2.WithPreWriteTopology; +import org.apache.flink.streaming.api.datastream.DataStream; +import org.apache.flink.streaming.api.datastream.DataStreamSink; +import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; +import org.apache.flink.table.api.TableSchema; +import org.apache.flink.table.data.RowData; +import org.apache.flink.table.data.util.DataFormatConverters; +import org.apache.flink.table.types.DataType; +import org.apache.flink.table.types.logical.RowType; +import org.apache.flink.types.Row; +import org.apache.iceberg.DataFile; +import org.apache.iceberg.DistributionMode; +import org.apache.iceberg.FileFormat; +import org.apache.iceberg.PartitionField; +import org.apache.iceberg.PartitionSpec; +import org.apache.iceberg.Schema; +import org.apache.iceberg.SerializableTable; +import org.apache.iceberg.Table; +import org.apache.iceberg.flink.FlinkSchemaUtil; +import org.apache.iceberg.flink.FlinkWriteConf; +import org.apache.iceberg.flink.FlinkWriteOptions; +import org.apache.iceberg.flink.TableLoader; +import org.apache.iceberg.flink.sink.committer.FilesCommittable; +import org.apache.iceberg.flink.sink.committer.FilesCommittableSerializer; +import org.apache.iceberg.flink.sink.committer.FilesCommitter; +import org.apache.iceberg.flink.sink.writer.StreamWriter; +import org.apache.iceberg.flink.sink.writer.StreamWriterState; +import org.apache.iceberg.flink.sink.writer.StreamWriterStateSerializer; +import org.apache.iceberg.flink.util.FlinkCompatibilityUtil; +import org.apache.iceberg.relocated.com.google.common.base.Preconditions; +import org.apache.iceberg.relocated.com.google.common.collect.Lists; +import org.apache.iceberg.relocated.com.google.common.collect.Maps; +import org.apache.iceberg.relocated.com.google.common.collect.Sets; +import org.apache.iceberg.types.TypeUtil; +import org.slf4j.Logger; +import org.slf4j.LoggerFactory; + +/** + * Flink v2 sink offer different hooks to insert custom topologies into the sink. It includes + * writers that can write data to files in parallel and route commit info globally to one Committer. + * Post commit topology will take of compacting the already written files and updating the file log + * after the compaction. + * + * <pre>{@code + * Flink sink + * +------------------------------------------------------------------+ + * | | + * +-------+ | +-------------+ +---------------+ | + * | Map 1 | ==> | | writer 1 | =| | committer 1 | | + * +-------+ | +-------------+ +---------------+ | + * | \ | + * | \ | + * | \ | + * +-------+ | +-------------+ \ +---------------+ +---------------+ | + * | Map 2 | ==> | | writer 2 | =| --- >| committer 2 | ---> | post commit | | + * +-------+ | +-------------+ +---------------+ +---------------+ | + * | | + * +------------------------------------------------------------------+ + * }</pre> + */ +public class IcebergSink + implements StatefulSink<RowData, StreamWriterState>, + WithPreWriteTopology<RowData>, + WithPreCommitTopology<RowData, FilesCommittable>, + WithPostCommitTopology<RowData, FilesCommittable> { + private static final Logger LOG = LoggerFactory.getLogger(IcebergSink.class); + + private final TableLoader tableLoader; + private final Table table; + private final boolean overwrite; + private final boolean upsertMode; + private final DistributionMode distributionMode; + private final List<String> equalityFieldColumns; + private final List<Integer> equalityFieldIds; + private final FileFormat dataFileFormat; + private final int workerPoolSize; + private final long targetDataFileSize; + private final String uidPrefix; + private final Map<String, String> snapshotProperties; + private final RowType flinkRowType; + private Committer<FilesCommittable> committer; + + private IcebergSink( + TableLoader tableLoader, + @Nullable Table table, + List<Integer> equalityFieldIds, + List<String> equalityFieldColumns, + @Nullable String uidPrefix, + Map<String, String> snapshotProperties, + boolean upsertMode, + boolean overwrite, + TableSchema tableSchema, + DistributionMode distributionMode, + int workerPoolSize, + long targetDataFileSize, + FileFormat dataFileFormat) { + Preconditions.checkNotNull(tableLoader, "Table loader shouldn't be null"); + Preconditions.checkNotNull(table, "Table shouldn't be null"); + + this.tableLoader = tableLoader; + this.table = table; + this.equalityFieldIds = equalityFieldIds; + this.equalityFieldColumns = equalityFieldColumns; + this.uidPrefix = uidPrefix == null ? "" : uidPrefix; + this.snapshotProperties = snapshotProperties; + this.flinkRowType = toFlinkRowType(table.schema(), tableSchema); + this.upsertMode = upsertMode; + this.overwrite = overwrite; + this.distributionMode = distributionMode; + this.workerPoolSize = workerPoolSize; + this.targetDataFileSize = targetDataFileSize; + this.dataFileFormat = dataFileFormat; + } + + @Override + public DataStream<RowData> addPreWriteTopology(DataStream<RowData> inputDataStream) { + return distributeDataStream( + inputDataStream, + equalityFieldIds, + table.spec(), + table.schema(), + flinkRowType, + distributionMode, + equalityFieldColumns); + } + + @Override + public StreamWriter createWriter(InitContext context) { + return restoreWriter(context, null); + } + + @Override + public StreamWriter restoreWriter( + InitContext context, Collection<StreamWriterState> recoveredState) { + RowDataTaskWriterFactory taskWriterFactory = + new RowDataTaskWriterFactory( + SerializableTable.copyOf(table), + flinkRowType, + targetDataFileSize, + dataFileFormat, + equalityFieldIds, + upsertMode); + StreamWriter streamWriter = + new StreamWriter( + table.name(), + taskWriterFactory, + context.getSubtaskId(), + context.getNumberOfParallelSubtasks()); + if (recoveredState == null) { + return streamWriter; + } + + return streamWriter.restoreWriter(recoveredState); + } + + @Override + public SimpleVersionedSerializer<StreamWriterState> getWriterStateSerializer() { + return new StreamWriterStateSerializer(); + } + + @Override + public DataStream<CommittableMessage<FilesCommittable>> addPreCommitTopology( + DataStream<CommittableMessage<FilesCommittable>> writeResults) { + return writeResults + .map( + new RichMapFunction< + CommittableMessage<FilesCommittable>, CommittableMessage<FilesCommittable>>() { + @Override + public CommittableMessage<FilesCommittable> map( + CommittableMessage<FilesCommittable> message) { + if (message instanceof CommittableWithLineage) { Review Comment: In fact, if we can directly getcheckpointid\jobid\subtaskId in `prepareCommit`, we do not need to assign them here. The following is the Committable design document for reference. >We also introduce two common wrappers around the Sink Committables to ease the implementation of the topologies based on committables. 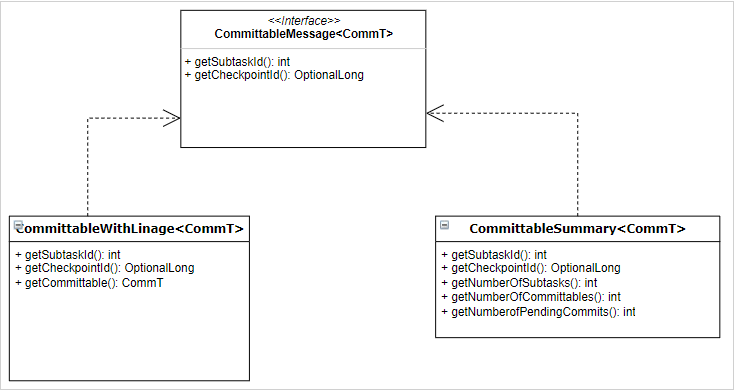 >In these topologies, the committable will always be part of the CommittableWithLinage to have a notion to which checkpoint it belongs and from which subtask it was sent. In this case, it can be either the SinkWriter or Committer depending on which topology is used (pre- or post-commit). Moreover, we introduce the CommittableSummary that is sent once as the last message of this checkpoint. Down-stream operators receiving this message can be sure that the subtask the message was coming from does not send more messages in this checkpoint. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected] --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]
{kind=link}