hellochueng opened a new issue, #7455: URL: https://github.com/apache/iceberg/issues/7455
### Query engine spark ### Question use spark3.3 iceberg 1.2 insert into partition table,Large amount of data in one partition doc  Iceberg requires the data to be sorted according to the partition spec per task (Spark partition) in prior to write against partitioned table. This applies both Writing with SQL and Writing with DataFrames. 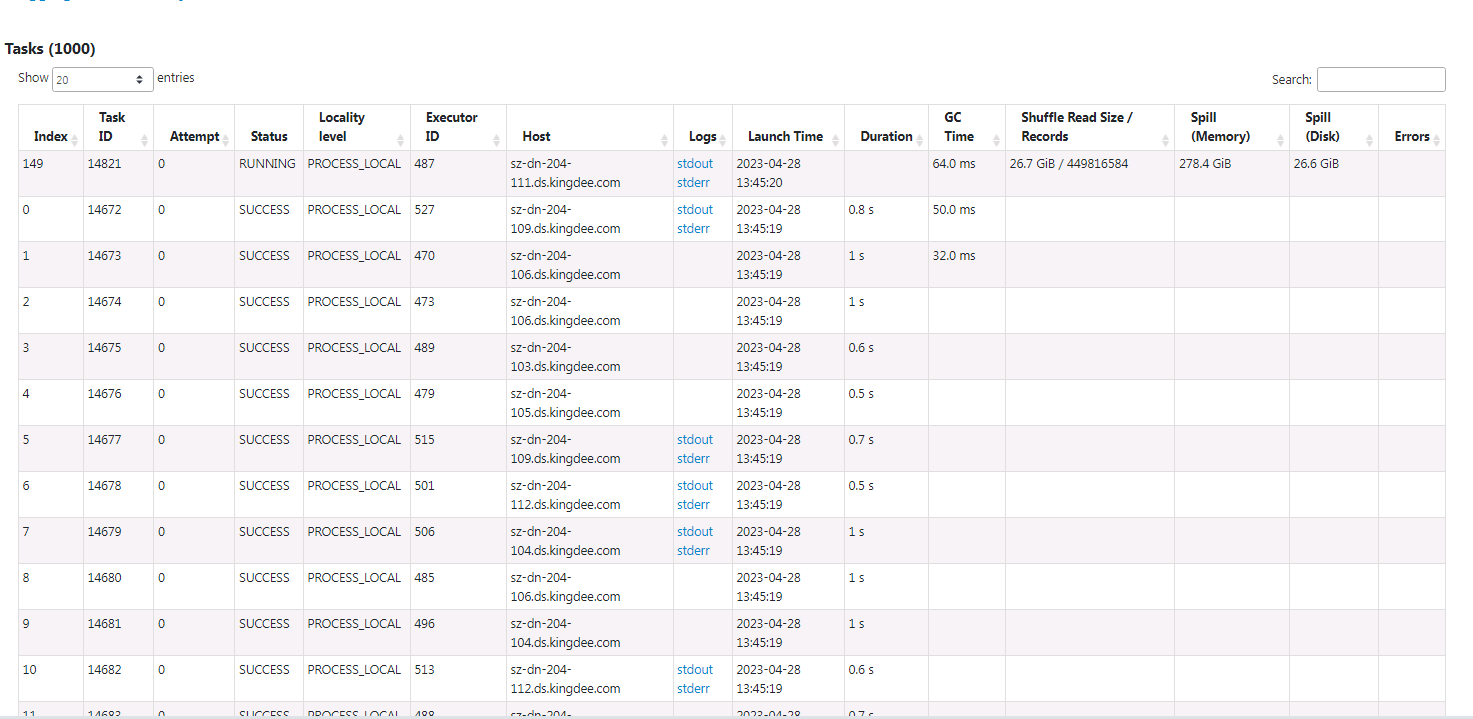 The problem of slanting data writing occurred in my job how can i solve this problem -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected] --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}