[
https://issues.apache.org/jira/browse/OPENNLP-1266?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16866766#comment-16866766
]
ASF GitHub Bot commented on OPENNLP-1266:
-----------------------------------------
tballison commented on pull request #355: OPENNLP-1266 -- Limit regexes in
UrlCharSequenceNormalizer
URL: https://github.com/apache/opennlp/pull/355#discussion_r294889810
##########
File path:
opennlp-tools/src/main/java/opennlp/tools/util/normalizer/UrlCharSequenceNormalizer.java
##########
@@ -24,9 +24,9 @@
public class UrlCharSequenceNormalizer implements CharSequenceNormalizer {
private static final Pattern URL_REGEX =
- Pattern.compile("https?://[-_.?&~;+=/#0-9A-Za-z]+");
+ Pattern.compile("https?://[-_.?&~;+=/#0-9A-Za-z]{1,10000}");
private static final Pattern MAIL_REGEX =
- Pattern.compile("[-_.0-9A-Za-z]+@[-_0-9A-Za-z]+[-_.0-9A-Za-z]+");
+
Pattern.compile("[-_.0-9A-Za-z]{1,100}@[-_0-9A-Za-z]{1,100}[-_.0-9A-Za-z]{1,100}");
Review comment:
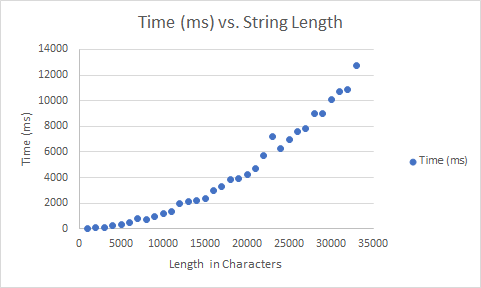
Y. These do limit the lengths. This was one solution that prevented worse
than linear processing times on long strings of text. When Tika updated its
regression corpus, one doc had a really long string of DNA with no spaces.
This caused a similar regex in Optimaize to take > 5 minutes to process.
See the stats here:
https://issues.apache.org/jira/browse/OPENNLP-1266?focusedCommentId=16858605&page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel#comment-16858605
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
[email protected]
> Limit normalization regexes in UrlCharSequenceNormalizer
> --------------------------------------------------------
>
> Key: OPENNLP-1266
> URL: https://issues.apache.org/jira/browse/OPENNLP-1266
> Project: OpenNLP
> Issue Type: Task
> Reporter: Tim Allison
> Priority: Major
>
> The {{MAIL_REGEX}} in UrlCharSequenceNormalizer is unbounded and requires
> backtracking. In rare cases, this can cause eye-opening performance costs.
>
> I tested the other regexes in the other normalizers. I could be wrong, but
> they don't appear to require backtracking, and there are no surprising
> performance costs.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
{kind=link}