[
https://issues.apache.org/jira/browse/PHOENIX-5055?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16707637#comment-16707637
]
Hadoop QA commented on PHOENIX-5055:
------------------------------------
{color:red}-1 overall{color}. Here are the results of testing the latest
attachment
http://issues.apache.org/jira/secure/attachment/12950411/PHOENIX-5055-v4.x-HBase-1.4.patch
against 4.x-HBase-1.4 branch at commit
52b563d70830454609ad416ee8dd271e37eeeb70.
ATTACHMENT ID: 12950411
{color:green}+1 @author{color}. The patch does not contain any @author
tags.
{color:green}+1 tests included{color}. The patch appears to include 3 new
or modified tests.
{color:green}+1 javac{color}. The applied patch does not increase the
total number of javac compiler warnings.
{color:red}-1 release audit{color}. The applied patch generated 1 release
audit warnings (more than the master's current 0 warnings).
{color:red}-1 lineLengths{color}. The patch introduces the following lines
longer than 100:
+ try (PhoenixConnection conn =
DriverManager.getConnection(getUrl(), props).unwrap(PhoenixConnection.class)) {
+ conn.createStatement().executeUpdate("CREATE INDEX " + indexName +
" on " + tableName + " (C) INCLUDE(D)");
+ conn.createStatement().executeUpdate("UPSERT INTO " + tableName +
"(A,B,C,D) VALUES ('A2','B2','C2','D2')");
+ conn.createStatement().executeUpdate("UPSERT INTO " + tableName +
"(A,B,C,D) VALUES ('A3','B3', 'C3', null)");
+ assertEquals("(" + cell.toString() + ") has different
ts", ts, cell.getTimestamp());
+ public static List<List<Mutation>> getMutationBatchList(long batchSize,
long batchSizeBytes, List<Mutation> allMutationList) {
+ "Mutation types are put or delete, for one row all mutations
must be in one batch.");
+ for (;s < allMutationList.size() &&
Bytes.compareTo(allMutationList.get(s).getRow(), mutation.getRow()) == 0; s++) {
+ long mutationSizeBytes =
KeyValueUtil.calculateMutationDiskSize(allMutationList.get(s));
+ if (currentList.size() == batchSize || currentBatchSizeBytes +
mutationSizeBytes > batchSizeBytes) {
{color:green}+1 core tests{color}. The patch passed unit tests in .
Test results:
https://builds.apache.org/job/PreCommit-PHOENIX-Build/2184//testReport/
Release audit warnings:
https://builds.apache.org/job/PreCommit-PHOENIX-Build/2184//artifact/patchprocess/patchReleaseAuditWarnings.txt
Console output:
https://builds.apache.org/job/PreCommit-PHOENIX-Build/2184//console
This message is automatically generated.
> Split mutations batches probably affects correctness of index data
> ------------------------------------------------------------------
>
> Key: PHOENIX-5055
> URL: https://issues.apache.org/jira/browse/PHOENIX-5055
> Project: Phoenix
> Issue Type: Bug
> Affects Versions: 5.0.0, 4.14.1
> Reporter: Jaanai
> Assignee: Jaanai
> Priority: Critical
> Fix For: 5.1.0
>
> Attachments: ConcurrentTest.java, PHOENIX-5055-v4.x-HBase-1.4.patch
>
>
> In order to get more performance, we split the list of mutations into
> multiple batches in MutationSate. For one upsert SQL with some null values
> that will produce two type KeyValues(Put and DeleteColumn), These KeyValues
> should have the same timestamp so that keep on an atomic operation for
> corresponding the row key.
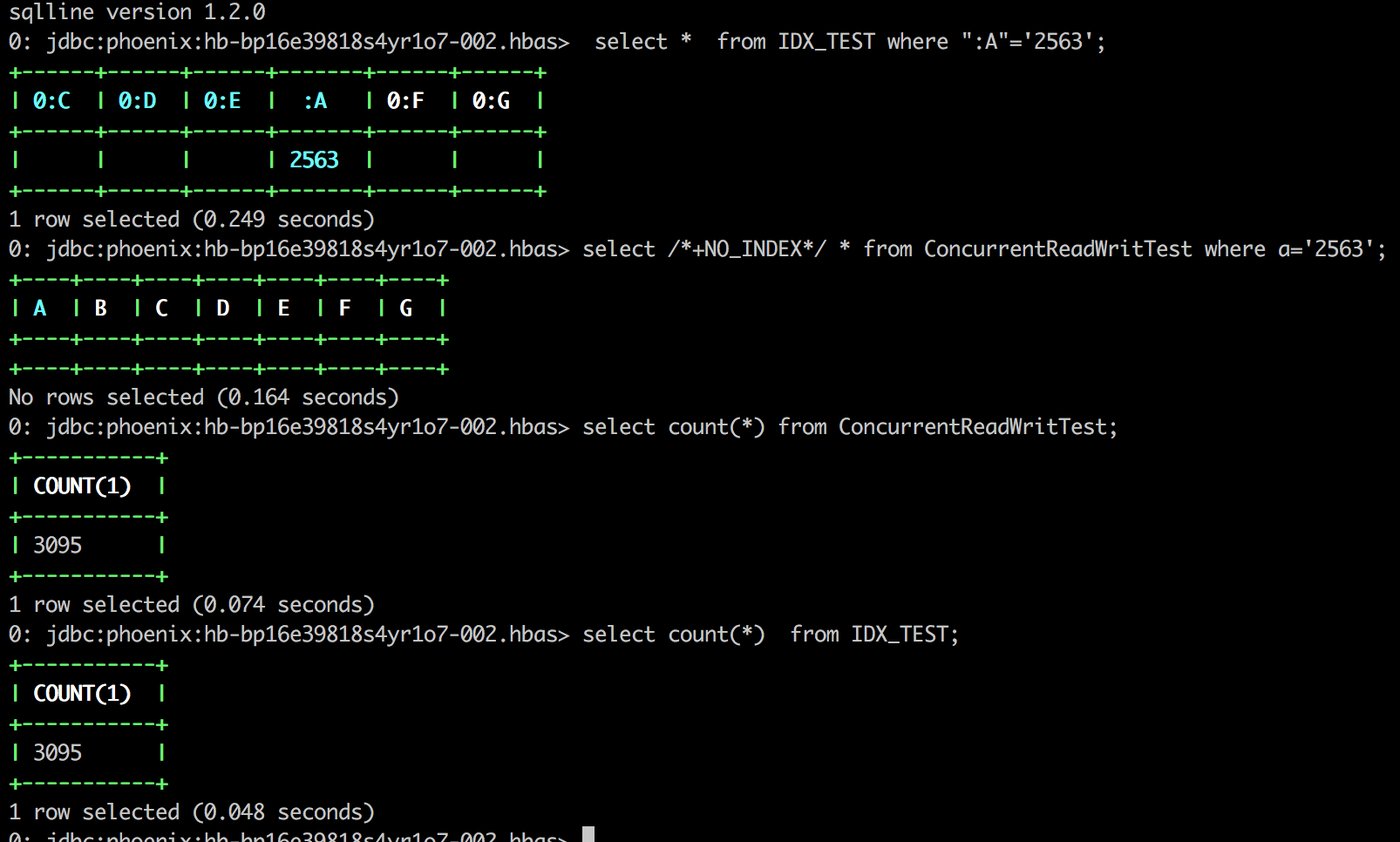
> Found incorrect indexed data for the index tables by sqlline.
> !https://gw.alicdn.com/tfscom/TB1nSDqpxTpK1RjSZFGXXcHqFXa.png|width=665,height=400!
>
> Running the following:
> {code:java}
> conn.createStatement().executeUpdate( "CREATE TABLE " + tableName + " (" + "A
> VARCHAR NOT NULL PRIMARY KEY," + "B VARCHAR," + "C VARCHAR," + "D VARCHAR)
> COLUMN_ENCODED_BYTES = 0");
> conn.createStatement().executeUpdate("CREATE INDEX " + indexName + " on " +
> tableName + " (C) INCLUDE(D)");
> conn.createStatement().executeUpdate("UPSERT INTO " + tableName + "(A,B,C,D)
> VALUES ('A2','B2','C2','D2')");
> conn.createStatement().executeUpdate("UPSERT INTO " + tableName + "(A,B,C,D)
> VALUES ('A3','B3', 'C3', null)");
> {code}
> dump IndexMemStore:
> {code:java}
> hbase.index.covered.data.IndexMemStore(117):
> Inserting:\x01A3/0:D/1542190446218/DeleteColumn/vlen=0/seqid=0/value=
> phoenix.hbase.index.covered.data.IndexMemStore(133): Current kv state:
> phoenix.hbase.index.covered.data.IndexMemStore(135): KV:
> \x01A3/0:B/1542190446167/Put/vlen=2/seqid=5/value=B3
> phoenix.hbase.index.covered.data.IndexMemStore(135): KV:
> \x01A3/0:C/1542190446167/Put/vlen=2/seqid=5/value=C3
> phoenix.hbase.index.covered.data.IndexMemStore(135): KV:
> \x01A3/0:D/1542190446218/DeleteColumn/vlen=0/seqid=0/value=
> phoenix.hbase.index.covered.data.IndexMemStore(135): KV:
> \x01A3/0:_0/1542190446167/Put/vlen=1/seqid=5/value=x
> phoenix.hbase.index.covered.data.IndexMemStore(137): ========== END MemStore
> Dump ==================
> {code}
>
> The DeleteColumn's timestamp larger than other mutations.
>
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
{kind=link}