[
https://issues.apache.org/jira/browse/SPARK-16217?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
GuangFancui(ISCAS) updated SPARK-16217:
---------------------------------------
Description:
The *SELECT INTO* statement selects data from one table and inserts it into a
new table as follows.
{code:sql}
SELECT column_name(s)
INTO newtable
FROM table1;
{code}
This statement is commonly used in SQL but not currently supported in SparkSQL.
We investigated the Catalyst and found that this statement can be implemented
by improving the grammar and reusing the logical plan of *CREAT TABLE AS
SELECT* as follows.
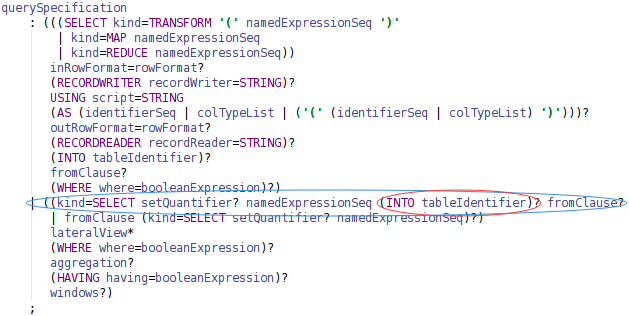
# Improve grammar: Add _intoClause_ to _SELECT ... FROM_ in
_querySpecification_ grammar in SqlBase.g4 file.
!https://raw.githubusercontent.com/wuxianxingkong/storage/master/selectinto_g4_v2.png!
For example
{code:sql}
SELECT *
INTO NEW_TABLE
FROM OLD_TABLE
{code}
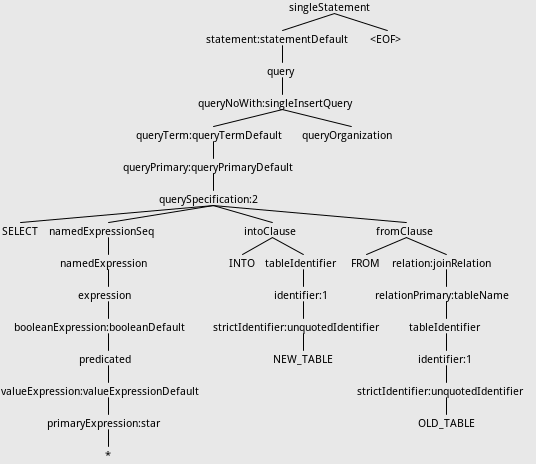
Then the grammar tree will be:
!https://raw.githubusercontent.com/wuxianxingkong/storage/master/selectinto_tree_v2.png!
Furthermore, we can argue whether it's necessary to add _intoCaluse_ to
_TRANSFORM_ in _querySpecification_
# Identify _SELECT INTO_ in _Parser_: Modify _visitSingleInsertQuery_ function.
Extract _IntoClauseContext_ with _existIntoClause_ fucntion.
_IntoClauseContext_ is then passed as an argument to _withSelectInto_ function
.(_intoClause_ and queryOrganization are not in the same level, so we need to
extract _IntoClauseContext_ when visiting _singleInsertQuery_)
# Conversion in _Parser_: Convert current logical plan to _CTAS_(Strictly
speaking, as a child of CTAS) using _withSelectInto_ function.
*Hive support* should be opened since _CreateHiveTableAsSelectCommand_ relies
on it.
_withSelectInto_ function copies code of _visitCreateTable_ to do conversion.
So it requires further discussion and optimization.
Implements are based on the following _assumptions_:
# _intoClause_ must be together with _fromClause_.{code:sql}(intoClause?
fromClause)?{code}This structure can ensure that this modification won’t affect
existed _multiInsertQuery_.
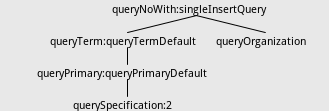
# _SELECT INOT_ statement will be translated to the following tree structure:
!https://raw.githubusercontent.com/wuxianxingkong/storage/master/hierarchy.png!
As shown, if there is a _intoClause_, the actual subclass of _queryTerm_ is
_queryTermDefault_, besides, the actual subclass of _queryPrimary_ is
_queryPrimaryDefault_. We use _existIntoClause_ function to match designated
subclass. Only all conditions are satisfied can this function return
intoClauseContext, if not, return null.
We’ve implemented and tested the above approach. Please refer to PR:
https://github.com/apache/spark/pull/14191
was:
The *SELECT INTO* statement selects data from one table and inserts it into a
new table as follows.
{code:sql}
SELECT column_name(s)
INTO newtable
FROM table1;
{code}
This statement is commonly used in SQL but not currently supported in SparkSQL.
We investigated the Catalyst and found that this statement can be implemented
by improving the grammar and reusing the logical plan of *CREAT TABLE AS
SELECT* as follows.
# Improve grammar: Add _INTO tableIdentifier_ to _SELECT ... FROM_ in
_querySpecification_ grammar in SqlBase.g4 file.
!https://raw.githubusercontent.com/wuxianxingkong/storage/master/selectinto_g4.png!
For example
{code:sql}
SELECT *
INTO NEW_TABLE
FROM OLD_TABLE
{code}
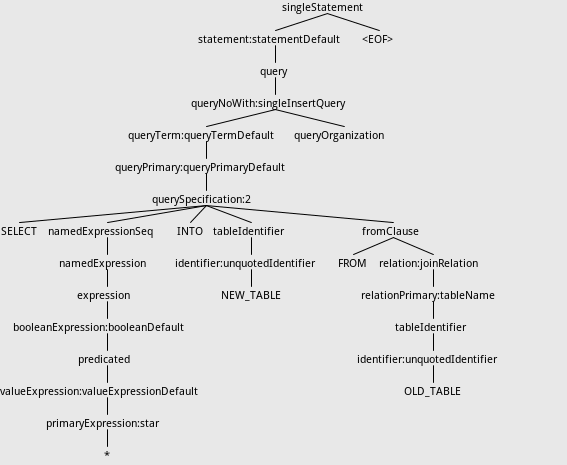
Then the grammar tree will be:
!https://raw.githubusercontent.com/wuxianxingkong/storage/master/selectinto_tree.png!
Furthermore, we can argue whether it's necessary to add _INTO_ to _TRANSFORM_
in _querySpecification_
# Add new logicalplan: _SelectIntoLogicalPlan_
# Identify _SELECT INTO_ in the Parser: Modify _withQuerySpecification_
function. If there is _INTO tableIdentifier_, we can change it to
_SelectIntoLogicalPlan_ with _withSelectInto_(custom function).
# Conversion in Analyzer: Convert _SelectIntoLogicalPlan_ to
_CreateTableAsSelectCommand_ by adding a rule in the Analyzer.
*Hive support* should be opened since _CreateTableAsSelectCommand_ relies on it.
We’ve implemented and tested the above approach. If possible, we can make some
pull requests.
> Support SELECT INTO statement
> -----------------------------
>
> Key: SPARK-16217
> URL: https://issues.apache.org/jira/browse/SPARK-16217
> Project: Spark
> Issue Type: Improvement
> Components: SQL
> Affects Versions: 2.1.0
> Reporter: GuangFancui(ISCAS)
>
> The *SELECT INTO* statement selects data from one table and inserts it into a
> new table as follows.
> {code:sql}
> SELECT column_name(s)
> INTO newtable
> FROM table1;
> {code}
> This statement is commonly used in SQL but not currently supported in
> SparkSQL.
> We investigated the Catalyst and found that this statement can be implemented
> by improving the grammar and reusing the logical plan of *CREAT TABLE AS
> SELECT* as follows.
> # Improve grammar: Add _intoClause_ to _SELECT ... FROM_ in
> _querySpecification_ grammar in SqlBase.g4 file.
> !https://raw.githubusercontent.com/wuxianxingkong/storage/master/selectinto_g4_v2.png!
> For example
> {code:sql}
> SELECT *
> INTO NEW_TABLE
> FROM OLD_TABLE
> {code}
> Then the grammar tree will be:
> !https://raw.githubusercontent.com/wuxianxingkong/storage/master/selectinto_tree_v2.png!
> Furthermore, we can argue whether it's necessary to add _intoCaluse_ to
> _TRANSFORM_ in _querySpecification_
> # Identify _SELECT INTO_ in _Parser_: Modify _visitSingleInsertQuery_
> function. Extract _IntoClauseContext_ with _existIntoClause_ fucntion.
> _IntoClauseContext_ is then passed as an argument to _withSelectInto_
> function .(_intoClause_ and queryOrganization are not in the same level, so
> we need to extract _IntoClauseContext_ when visiting _singleInsertQuery_)
> # Conversion in _Parser_: Convert current logical plan to _CTAS_(Strictly
> speaking, as a child of CTAS) using _withSelectInto_ function.
> *Hive support* should be opened since _CreateHiveTableAsSelectCommand_ relies
> on it.
> _withSelectInto_ function copies code of _visitCreateTable_ to do conversion.
> So it requires further discussion and optimization.
> Implements are based on the following _assumptions_:
> # _intoClause_ must be together with _fromClause_.{code:sql}(intoClause?
> fromClause)?{code}This structure can ensure that this modification won’t
> affect existed _multiInsertQuery_.
> # _SELECT INOT_ statement will be translated to the following tree structure:
> !https://raw.githubusercontent.com/wuxianxingkong/storage/master/hierarchy.png!
> As shown, if there is a _intoClause_, the actual subclass of _queryTerm_ is
> _queryTermDefault_, besides, the actual subclass of _queryPrimary_ is
> _queryPrimaryDefault_. We use _existIntoClause_ function to match designated
> subclass. Only all conditions are satisfied can this function return
> intoClauseContext, if not, return null.
> We’ve implemented and tested the above approach. Please refer to PR:
> https://github.com/apache/spark/pull/14191
--
This message was sent by Atlassian JIRA
(v6.3.4#6332)
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}