[
https://issues.apache.org/jira/browse/SPARK-55311?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Angel Alvarez Pascua updated SPARK-55311:
-----------------------------------------
Description:
Spark 4.1 introduced a new feature ({*}ChecksumCheckpointFileManager){*} where
each partition creates its own {{{}ChecksumFileOutputSuite{}}}, and each suite
spawns *4 threads* to parallelize checkpoint file operations (offset logs,
metadata, state updates, commit logs, etc.).
In {*}Structured Streaming{*}, every trigger writes checkpoint files. The
effect becomes extreme when users run streaming queries with the default:
spark.sql.shuffle.partitions = 200
With the new threaded ChecksumCheckpointFileManager implementation:
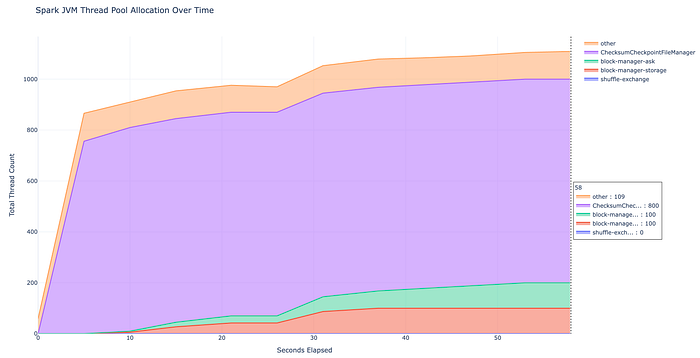
* 200 shuffle partitions × 4 threads per partition = *~800 new threads created*
* Even simple streaming jobs (e.g., noop sink) see large thread-pool explosions
* {{.outputMode("complete")}} amplifies the effect by rewriting results each
trigger
* High throughput workloads (e.g., SHA-512 hashing, explode operations, 50k
rows/s) cause sustained thread churn and pressure on the JVM and OS
These threads are created *regardless of user intent* and {*}regardless of
whether high parallelism is needed{*}, because streaming uses the batch default
of 200 partitions.
This regression does _not_ appear in batch jobs because they write far fewer
metadata files.
*Proposed Change*
For Structured Streaming only, reduce the default:
spark.sql.shuffle.partitions = 25
Rationale:
* Many streaming workloads do not require 200 partitions; 25 is sufficient for
typical micro-batches.
* Users needing higher parallelism can always increase the value explicitly.
* Fewer default partitions dramatically reduces ChecksumCheckpointFileManager
threads (25×4 = 100 threads instead of 800).
* Prevents unexpected thread explosions for users upgrading to Spark 4.1.
* More sensible default until AQE becomes supported/fully enabled for
streaming.
*Compatibility*
Low risk. Users needing 200 partitions can explicitly override the default.
*Additional Notes*
This issue has been observed in real workloads where Spark 4.1 streaming jobs
show unpredictable spikes of hundreds of threads even with moderate throughput
and lightweight sinks.
!https://miro.medium.com/v2/resize:fit:700/1*dIiANw3pVPj2DOAfuqfV-g.png!
was:
Spark 4.1 introduced a new feature ({*}ChecksumCheckpointFileManager){*} where
each partition creates its own {{{}ChecksumFileOutputSuite{}}}, and each suite
spawns *4 threads* to parallelize checkpoint file operations (offset logs,
metadata, state updates, commit logs, etc.).
In {*}Structured Streaming{*}, every trigger writes checkpoint files. The
effect becomes extreme when users run streaming queries with the default:
spark.sql.shuffle.partitions = 200
With the new threaded ChecksumCheckpointFileManager implementation:
* 200 shuffle partitions × 4 threads per partition = *~800 new threads created*
* Even simple streaming jobs (e.g., noop sink) see large thread-pool explosions
* {{.outputMode("complete")}} amplifies the effect by rewriting results each
trigger
* High throughput workloads (e.g., SHA-512 hashing, explode operations, 50k
rows/s) cause sustained thread churn and pressure on the JVM and OS
These threads are created *regardless of user intent* and {*}regardless of
whether high parallelism is needed{*}, because streaming uses the batch default
of 200 partitions.
This regression does _not_ appear in batch jobs because they write far fewer
metadata files.
*Proposed Change*
For Structured Streaming only, reduce the default:
spark.sql.shuffle.partitions = 25
Rationale: * Many streaming workloads do not require 200 partitions; 25 is
sufficient for typical micro-batches.
* Users needing higher parallelism can always increase the value explicitly.
* Fewer default partitions dramatically reduces ChecksumCheckpointFileManager
threads (25×4 = 100 threads instead of 800).
* Prevents unexpected thread explosions for users upgrading to Spark 4.1.
* More sensible default until AQE becomes supported/fully enabled for
streaming.
*Compatibility*
Low risk. Users needing 200 partitions can explicitly override the default.
*Additional Notes*
This issue has been observed in real workloads where Spark 4.1 streaming jobs
show unpredictable spikes of hundreds of threads even with moderate throughput
and lightweight sinks.
!https://miro.medium.com/v2/resize:fit:700/1*dIiANw3pVPj2DOAfuqfV-g.png!
> ChecksumCheckpointFileManager spawns 800 threads by default in streaming jobs
> -----------------------------------------------------------------------------
>
> Key: SPARK-55311
> URL: https://issues.apache.org/jira/browse/SPARK-55311
> Project: Spark
> Issue Type: Improvement
> Components: SQL
> Affects Versions: 4.1.0, 4.1.1
> Reporter: Angel Alvarez Pascua
> Priority: Trivial
>
> Spark 4.1 introduced a new feature ({*}ChecksumCheckpointFileManager){*}
> where each partition creates its own {{{}ChecksumFileOutputSuite{}}}, and
> each suite spawns *4 threads* to parallelize checkpoint file operations
> (offset logs, metadata, state updates, commit logs, etc.).
> In {*}Structured Streaming{*}, every trigger writes checkpoint files. The
> effect becomes extreme when users run streaming queries with the default:
> spark.sql.shuffle.partitions = 200
> With the new threaded ChecksumCheckpointFileManager implementation:
> * 200 shuffle partitions × 4 threads per partition = *~800 new threads
> created*
> * Even simple streaming jobs (e.g., noop sink) see large thread-pool
> explosions
> * {{.outputMode("complete")}} amplifies the effect by rewriting results each
> trigger
> * High throughput workloads (e.g., SHA-512 hashing, explode operations, 50k
> rows/s) cause sustained thread churn and pressure on the JVM and OS
> These threads are created *regardless of user intent* and {*}regardless of
> whether high parallelism is needed{*}, because streaming uses the batch
> default of 200 partitions.
> This regression does _not_ appear in batch jobs because they write far fewer
> metadata files.
> *Proposed Change*
> For Structured Streaming only, reduce the default:
> spark.sql.shuffle.partitions = 25
>
> Rationale:
> * Many streaming workloads do not require 200 partitions; 25 is sufficient
> for typical micro-batches.
> * Users needing higher parallelism can always increase the value explicitly.
> * Fewer default partitions dramatically reduces
> ChecksumCheckpointFileManager threads (25×4 = 100 threads instead of 800).
> * Prevents unexpected thread explosions for users upgrading to Spark 4.1.
> * More sensible default until AQE becomes supported/fully enabled for
> streaming.
> *Compatibility*
> Low risk. Users needing 200 partitions can explicitly override the default.
> *Additional Notes*
> This issue has been observed in real workloads where Spark 4.1 streaming jobs
> show unpredictable spikes of hundreds of threads even with moderate
> throughput and lightweight sinks.
>
> !https://miro.medium.com/v2/resize:fit:700/1*dIiANw3pVPj2DOAfuqfV-g.png!
--
This message was sent by Atlassian Jira
(v8.20.10#820010)
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}