[
https://issues.apache.org/jira/browse/SPARK-13122?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Andrew Or resolved SPARK-13122.
-------------------------------
Resolution: Fixed
Fix Version/s: 2.0.0
1.6.1
Target Version/s: 1.6.1, 2.0.0 (was: 1.6.1)
> Race condition in MemoryStore.unrollSafely() causes memory leak
> ---------------------------------------------------------------
>
> Key: SPARK-13122
> URL: https://issues.apache.org/jira/browse/SPARK-13122
> Project: Spark
> Issue Type: Bug
> Components: Spark Core, Streaming
> Affects Versions: 1.6.0
> Reporter: Adam Budde
> Assignee: Adam Budde
> Fix For: 1.6.1, 2.0.0
>
>
> The
> [unrollSafely()|https://github.com/apache/spark/blob/v1.6.0/core/src/main/scala/org/apache/spark/storage/MemoryStore.scala#L249]
> method in MemoryStore will progressively unroll the contents of a block
> iterator into memory. It works by reserving an initial chunk of unroll memory
> and periodically checking if more memory must be reserved as it unrolls the
> iterator. The memory reserved for performing the unroll is considered
> "pending" memory and is tracked on a per-task attempt ID bases in a map
> object named pendingUnrollMemoryMap. When the unrolled block is committed to
> storage memory in the
> [tryToPut()|https://github.com/apache/spark/blob/v1.6.0/core/src/main/scala/org/apache/spark/storage/MemoryStore.scala#L362]
> method, a method named
> [releasePendingUnrollMemoryForThisTask()|https://github.com/apache/spark/blob/v1.6.0/core/src/main/scala/org/apache/spark/storage/MemoryStore.scala#L521]
> is invoked and this pending memory is released. tryToPut() then proceeds to
> allocate the storage memory required for the block.
> The unrollSafely() method computes the amount of pending memory used for the
> unroll operation by saving the amount of unroll memory reserved for the
> particular task attempt ID at the start of the method in a variable named
> previousMemoryReserved and subtracting this value from the unroll memory
> dedicated to the task at the end of the method. This value is stored as the
> variable amountToTransferToPending. This amount is then subtracted from the
> per-task unrollMemoryMap and added to pendingUnrollMemoryMap.
> The amount of unroll memory consumed for the task is obtained from
> unrollMemoryMap via the currentUnrollMemoryForThisTask method. In order for
> the semantics of unrollSafely() to work, the value of unrollMemoryMap for the
> task returned by
> [currentTaskAttemptId()|https://github.com/apache/spark/blob/v1.6.0/core/src/main/scala/org/apache/spark/storage/MemoryStore.scala#L475]
> must not be mutated between the computation of previousMemoryReserved and
> amountToTransferToPending. However, since there is no synchronization in
> place to ensure that computing both variables and updating the memory maps
> happens atomically, a race condition can occur when multiple threads for
> which currentTaskAttemptId() returns the same value are both trying to store
> blocks. This can lead to a negative value being computed for
> amountToTransferToPending, corrupting the unrollMemoryMap and
> pendingUnrollMemoryMap memory maps which in turn can lead to the memory
> manager leaking unroll memory.
> For example, lets consider how the state of the unrollMemoryMap and
> pendingUnrollMemoryMap variables might be affected if two threads returning
> the same value for currentTaskAttemptId() both execute unrollSafely()
> concurrently:
> ||Thread 1||Thread 2||unrollMemoryMap||pendingUnrollMemoryMap||
> |Enter unrollSafely()|-|0|0|
> |perviousMemoryReserved = 0|-|0|0|
> |(perform unroll)|-|2097152 (2 MiB)|0|
> |-|Enter unrollSafely()|2097152 (2 MiB)|0|
> |-|perviousMemoryReserved = 2097152|2097152 (2 MiB)|0|
> |-|(performUnroll)|3145728 (3 MiB)|0|
> |Enter finally { }|-|3145728 (3 MiB)|0|
> |amtToTransfer = 3145728|-|3145728 (3 MiB)|0|
> |Update memory maps|-|0|3145728 (3 MiB)|
> |Return|Enter finally { }|0|3145728 (3 MiB)|
> |-|amtToTrasnfer = -2097152|0|3145728 (3 MiB)|
> |-|Update memory maps|-2097152 (2 MiB)|1048576 (1 MiB)|
> In this example, we end up leaking 2 MiB of unroll memory since both Thread 1
> and Thread 2 think that the task has only 1 MiB of unroll memory allocated to
> it when it actually has 3 MiB. The negative value stored in unrollMemoryMap
> will also propagate to future invocations of unrollSafely().
> In our particular case, this behavior manifests since the
> currentTaskAttemptId() method is returning -1 for each Spark receiver task.
> This in and of itself could be a bug and is something I'm going to look into.
> We noticed that blocks would start to spill over to disk when more than
> enough storage memory was available, so we inserted log statements into
> MemoryManager's acquireUnrollMemory() and releaseUnrollMemory() in order to
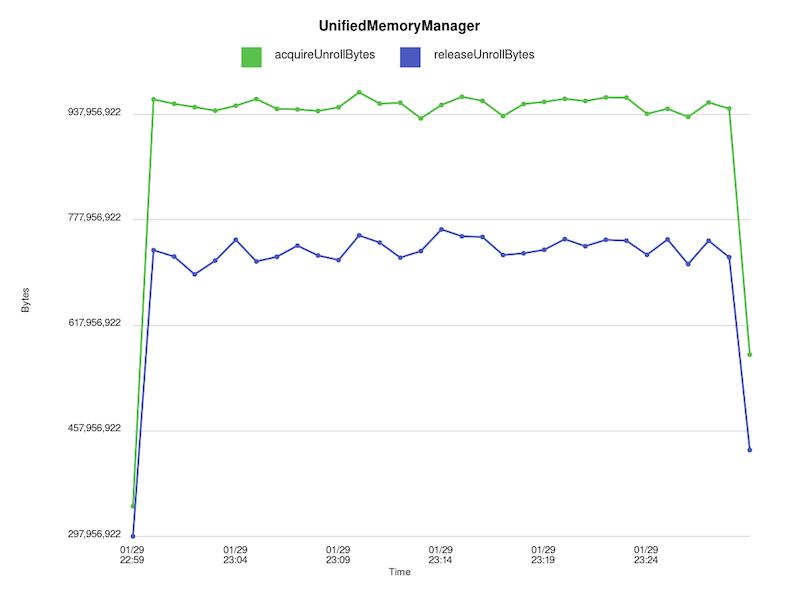
> collect the number of unroll bytes acquired and released. When we plot the
> output, it is apparent that unroll memory is being leaked:
> !https://raw.githubusercontent.com/budde/spark_debug/master/plots/UnifiedMemoryManager/leaked_unroll_bytes.png!
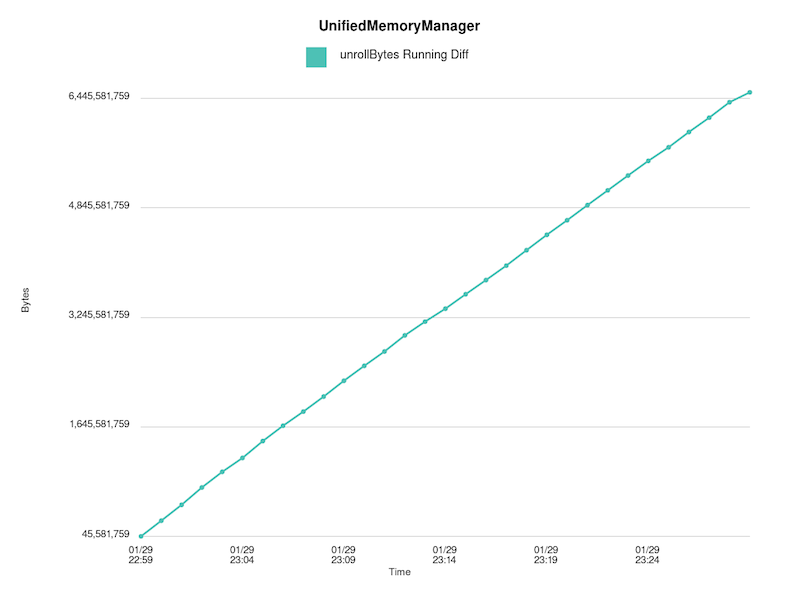
> Running difference between acquire/release bytes:
> !https://raw.githubusercontent.com/budde/spark_debug/master/plots/UnifiedMemoryManager/leaked_unroll_bytes_running_diff.png!
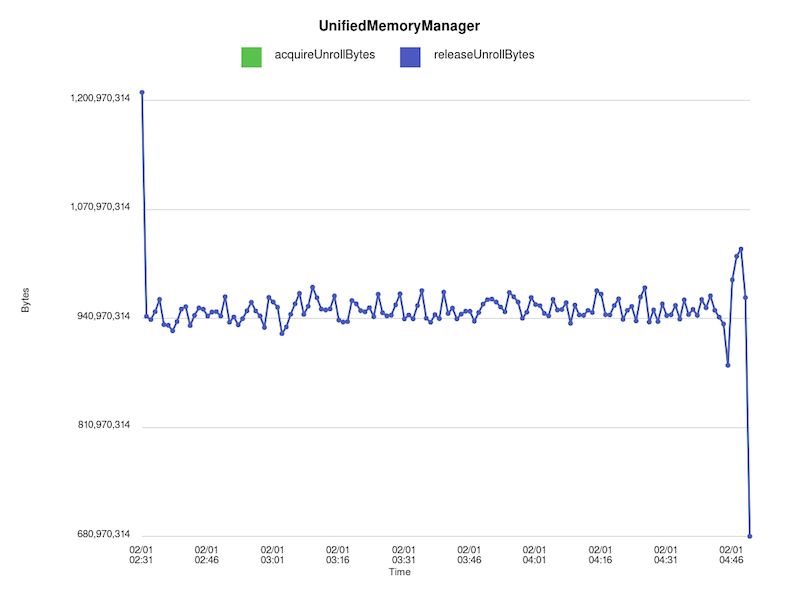
> However, if we change the implementation of unrollSafely() so that the entire
> method is within a synchronized block, we no longer see this leak:
> !https://raw.githubusercontent.com/budde/spark_debug/master/plots/UnifiedMemoryManager/synchronized_unroll_bytes.png!
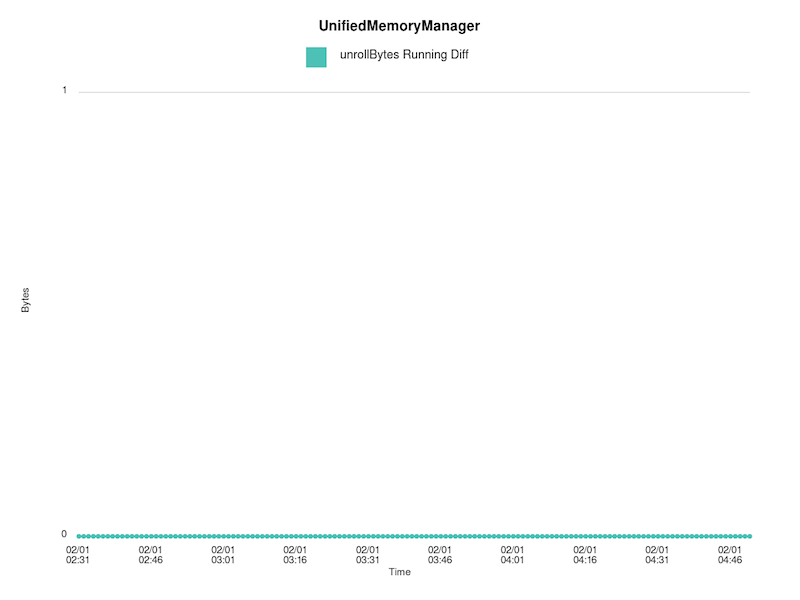
> Running difference between acquire/release bytes:
> !https://raw.githubusercontent.com/budde/spark_debug/master/plots/UnifiedMemoryManager/synchronized_unroll_bytes_running_diff.png!
--
This message was sent by Atlassian JIRA
(v6.3.4#6332)
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}