advancedxy commented on issue #503: URL: https://github.com/apache/incubator-uniffle/issues/503#issuecomment-1413620158
> > The size of RPC queue is unlimited, is it possible relate to this? > > Maybe. But from the metric dashboard, the GC is always along with the huge partition appearance. I will share some metrics of one shuffle-server. > > **CMS single GC cost 20s** 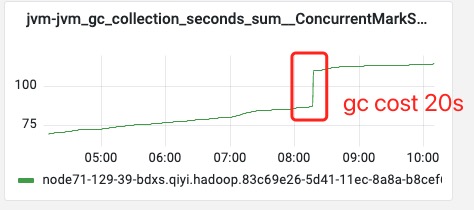 > > 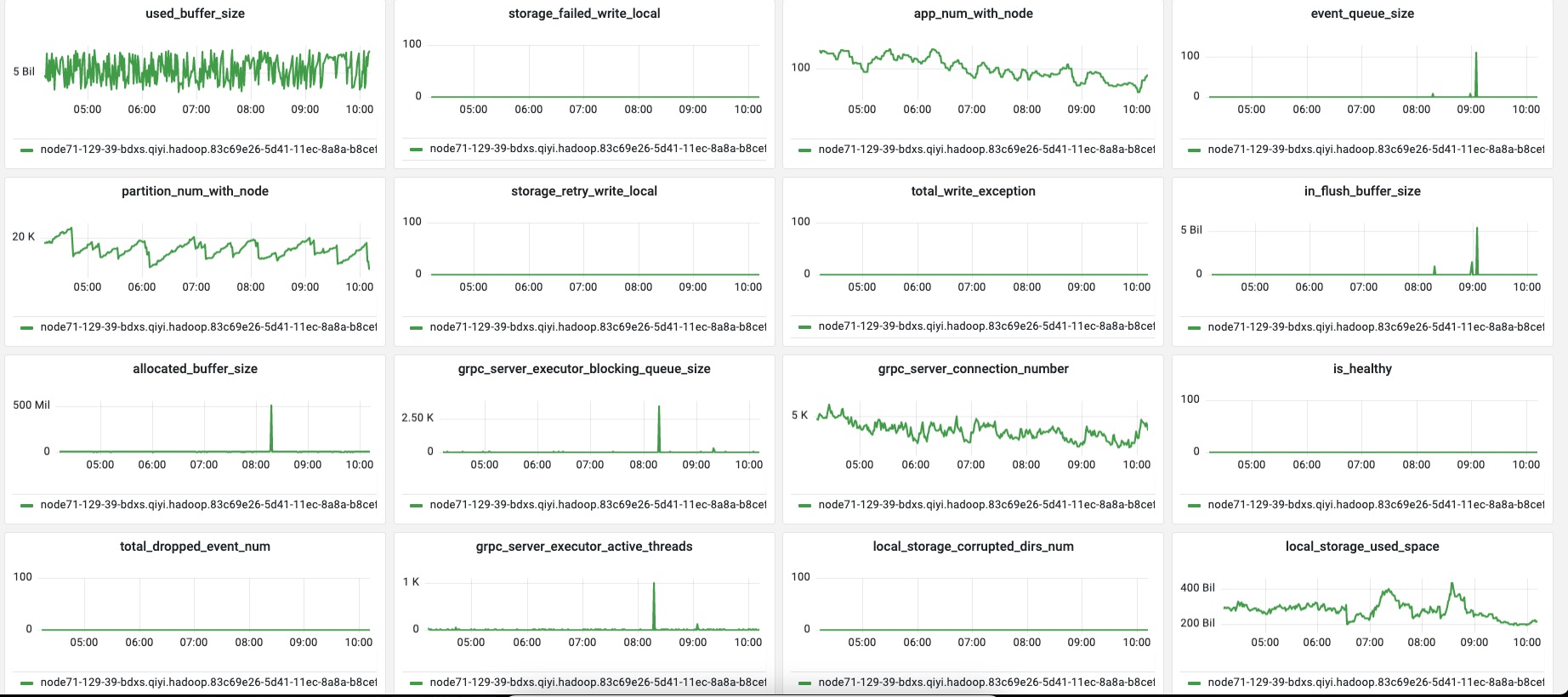 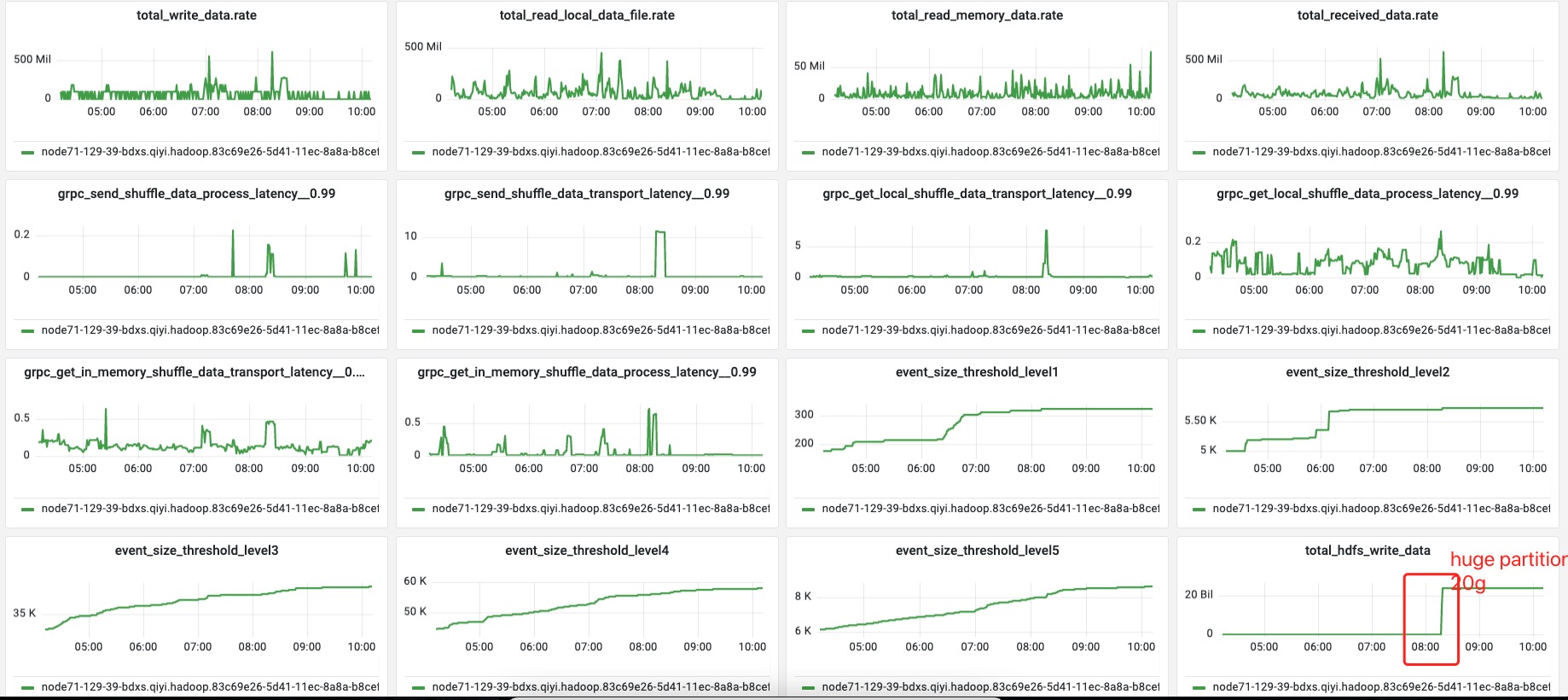 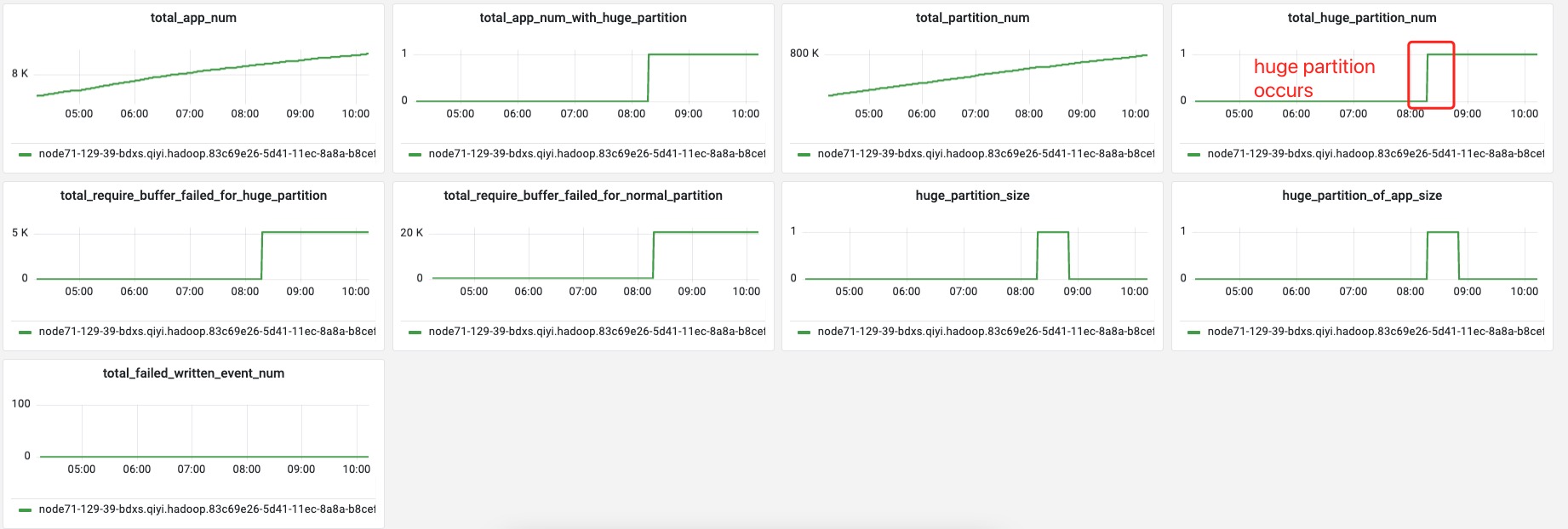 > > From this metric, I think the single buffer flush may solve this problem. <img width="917" alt="image" src="https://user-images.githubusercontent.com/807537/216317369-a41ea271-2861-4899-9b15-0c670dcd04a8.png";> Seems like the pre-allocation is also failed when the huge partition is arriving. I think this should match your speculation, shuffle server just cannot gc data quicker than the shuffle server. > I will enable the single buffer flush to avoid this problem Single buffer flush should have some effect. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected] --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}