And a couple more thoughts: - The performance is highly data dependent, so it would be nice to see an image of the test datasets to aid in understanding. If this was provided it would be easy to see that the query geometry is a regular polygon (I think?). As mentioned, this doesn't really take advantage of monotone chains. - It's pretty hard to synthesize data that approximates real-world data. You might want to try and work with real datasets. - I think relative peformance is going to be highly data-dependent. For example, a highly convex query geometry against a lot of small target geometries might show PG is much faster than Raw.
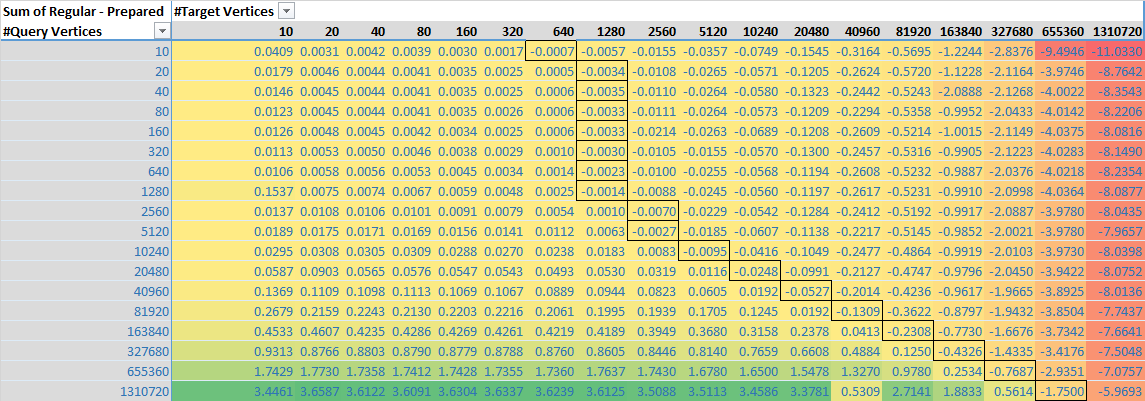
On Sun, Jun 14, 2015 at 3:11 PM, Joe Amenta <[email protected]> wrote: > Martin's "intersects != intersection" point is actually extremely relevant > here... the latest version on GitHub does an apples-to-oranges comparison. > > The initial version before the "fixed methodology" commit compared > PreparedGeometry.intersects(Geometry) with Geometry.*intersects*(Geometry), > whereas the latest version compares PreparedGeometry.intersects(Geometry) > with Geometry.*intersection*(Geometry). > > Just wanted to point this out... > > On Sun, Jun 14, 2015 at 5:51 PM, Martin Davis <[email protected]> wrote: > >> Interesting and very thorough analysis! It's definitely a surprise that >> PreparedGeometry drops below raw Geometry for large query sizes. It's >> maybe a bit less of a surprise that small PGs don't provide much >> improvement. >> >> It's going to take me a while to fully digest this, but a few initial >> comments: >> >> - In JTS the intersects and intersection operation are quite different >> (very much so in semantics, and currently somewhat less so in >> implementation). PreparedGeometry currently provides only the intersects >> operation. Support for intersection might be forthcoming at some point, >> but it's not there now. You might want to adjust your terminology to >> reflect this, to avoid confusion. >> >> - Increasing vertex count by densifying lines *might* be skewing the >> results somewhat, since it might defeat the use of monotone chains to >> improve indexing. Not sure how easy this is to mitigate - it's hard to >> generate large random polygons! Nevertheless, real-world datasets might >> show different performance characteristics (hopefully better!). >> >> - To figure out what's going on it will probably be necessary to profile >> the execution for large PGs. Typically in geometric algorithms performance >> problems are due to an O(n^2) operation lurking somewhere in the code. >> These sometimes don't show up until very large input sizes. >> >> Thanks for the post - if this provides better guidance on using PG vs >> Raw, this will be very helpful. >> >> >> >> On Sun, Jun 14, 2015 at 1:38 PM, Chris Bennight <[email protected]> >> wrote: >> >>> >>> I put together a quick project to try and understand some of the >>> trade-offs for prepared vs. non-prepared geometries (when to use a prepared >>> geometry, when not to, etc.) >>> >>> The readme has a summary of the tests and results, with graphics >>> https://github.com/chrisbennight/intersection-test >>> >>> Probably the best summary is this chart: >>> >>> https://raw.githubusercontent.com/chrisbennight/intersection-test/master/src/main/resources/difference%20-%20prepared%20vs%20non%20prepared%20-%20chart.png >>> >>> which shows the difference of (prepared geometry intersection time - >>> regular geometry intersection time) as a function of the number of points >>> in each geometry. >>> >>> My big takeaway is that once the target geometry starts getting around >>> 10k or more points, using a regular geometry intersection may be faster >>> than using a prepared geometry intersection. (Not saying 10k is a magic >>> number, just using that as a rough estimate of when I might need to start >>> caring) >>> >>> I think a typically use case of a query window (think typically WMS, >>> WFS, etc. BBOX query) with 5 points matching against complex geometries in >>> the database might very easily see worse performance by creating a new >>> PreparedGeometry instance of that 5 point geometry. >>> >>> Which is completely fair - just trying to understand the trade-offs and >>> heuristics for using it. Other strategies - such as in the case above, >>> preparing the target geometry and flipping the intersection test (since in >>> testing preparing the geometry was orders of magnitude faster than the >>> intersection) are also things I'm interested in. >>> >>> Probably my big request is a little review from the experts - have I >>> missed something obvious, done something horribly wrong, or is this a >>> reasonable outcome? I'd also be curious if there are any guidelines for >>> how/when people use a prepared geometry. It looks like PostGIS might >>> employ some heuristics in what and when to prepared the geometry? >>> >>> Anyway, just looking for a quick vector check as well as any >>> thoughts/guidance. Overall I'd like to come up with a heuristic for when >>> to used prepared geometry against arbitrary sets of polygons. >>> >>> >>> ------------------------------------------------------------------------------ >>> >>> _______________________________________________ >>> Jts-topo-suite-user mailing list >>> [email protected] >>> https://lists.sourceforge.net/lists/listinfo/jts-topo-suite-user >>> >>> >> >> >> ------------------------------------------------------------------------------ >> >> _______________________________________________ >> Jts-topo-suite-user mailing list >> [email protected] >> https://lists.sourceforge.net/lists/listinfo/jts-topo-suite-user >> >> >
{kind=link}
------------------------------------------------------------------------------
_______________________________________________ Jts-topo-suite-user mailing list [email protected] https://lists.sourceforge.net/lists/listinfo/jts-topo-suite-user