Hiya, I've been working for some time on improving the libc malloc in DragonFly, specifically improving its thread scaling and reducing the number of mmap/munmap system calls it issues.
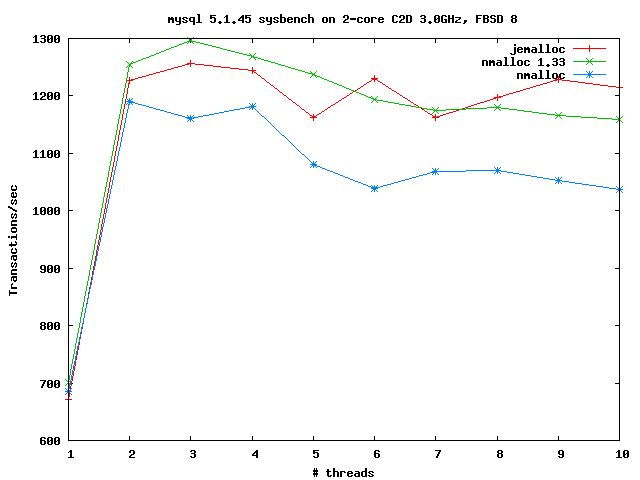
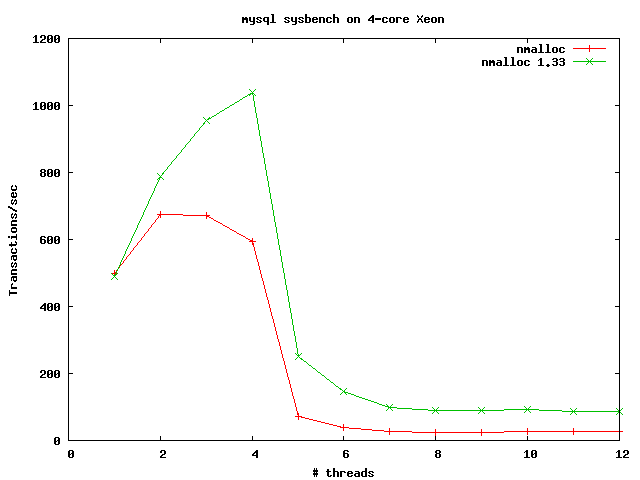
To address the issue of scaling, I added per-thread magazines for allocations < 8K (ones that would hit the current slab zones); the magazine logic is based straight on Bonwick and Adams's 2001 'Magazines and Vmem' paper, about the Solaris kernel allocator and libumem. To address the number of mmaps the allocator was making, I added a single magazine between the slab layer and mmap - it caches up to 64 zones and will reuse them rather than requesting/releasing to the system. In addition, I made the first request for a zone allocate not one, but 8 zones, the second will allocate 6, so on and on, till we have stabilized at allocating one-at-a-time. This logic was meant to deal with programs issuing requests for different-sized objects early on in their life. Some benchmark results so far: sh6bench ============================= To quote Jason Evans, 'is a quirky malloc benchmark that has been used in some of the published malloc literature, so I include it here. sh6bench does cycles of allocating groups of objects, where the size of objects in each group is random. Sometimes the objects are held for a while before being freed.' The test is available at: http://m-net.arbornet.org/~sv5679/sh6bench.c When run on DragonFly, with 50000 calls for objects between 1 and 1512 bytes, nmalloc (the current libc allocator) takes 85sec to finish the test; nmalloc-1.33 takes 58s, spending nearly 20 sec less in system time. When tested with 2500 calls, for 1...1512 byte objects on FreeBSD 8, nmalloc, nmalloc 1.33, and jemalloc (the FreeBSD libc allocator) turn in times very close to one another. Here are the total memory uses and mmap call counts: (nmalloc 'g' is nmalloc with the per-thread caches disabled). mmaps / munmaps total space requested/release diff nmalloc 1582 / 438 107,598,464 b / 29,220,560 b 78,377,904 b nmalloc 1.33 1154 / 9 81,261,328 b / 852,752 b 80,408,576 b nmalloc 1.33 'g' 1148 / 9 81,130,256 b / 852,752 b 80,277,504 b jemalloc 45 / 4 82,718,411 b / 1,609,424 b 81,108,987 b I also graphed the allocation structure using Jason Evans's mtrgraph tool (nmalloc 1.33 can generate utrace events). nmalloc: http://acm.jhu.edu/~me/heap/sh6bench_nmalloc.png nmalloc 1.33: http://acm.jhu.edu/~me/heap/sh6bench_nmalloc133.png jemalloc: http://acm.jhu.edu/~me/heap/sh6bench_jemalloc.png The horizontal axis of this graph is time in terms of allocation/free events. The vertical is address space, split into buckets. Similar traces were generated when jemalloc was in development: http://people.freebsd.org/~jasone/jemalloc/plots/ >From these, you can see that nmalloc 1.33 has similar heap structure and fragmentation characteristics to the original DragonFly allocator; this thread scaling work has not unduly increased fragmentation at least. MySQL sysbench ================================== I ran sysbench OLTP against a MySQL server on FreeBSD 8 (2-core Core2Duo 3.0GHz) and varied the number of threads; this is how nmalloc 1.33 fared against nmalloc and jemalloc (in transactions/sec): http://m-net.arbornet.org/~sv5679/sysbench_nmalloc.gif Polachok repeated these tests on a 4-core Xeon server (4 core + 4 HTT, 2.6GHz) running DragonFly; here is the improvement, again in transactions/sec: http://m-net.arbornet.org/~sv5679/sysbench_nmalloc_df.gif =================================== I'd appreciate if people could try these allocator improvements out; to do so, you can either: 1) Grab http://m-net.arbornet.org/~sv5679/nmalloc.c and http://m-net.arbornet.org/~sv5679/Makefile ;run make, you will get a shared object that you can LD_PRELOAD. 2) Grab http://m-net.arbornet.org/~sv5679/nmalloc.c and replace /usr/src/lib/libc/stdlib/nmalloc.c ; rebuild world. Your entire system will use the new allocator. Kick it around, see if it is faster; see if it explodes in use. All of this work is also at http://gitweb.dragonflybsd.org/~vsrinivas/dragonfly.git, in the nmalloc_mt branch. I'd also appreciate any code reviews, if anyone is interested. Thanks! -- vs
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}