Hello, On 2011-10-21 10:43, Michael Schnell wrote:
Of course you are right, but "move" and friends is "hardware-near programming" for this who know what they are doing. but basic (legacy) string operations like "myChar := myString[i]" is "office-level programming" and thus should work as a dummy expects.
What if a file on the user computer has 4byte [visible] character as 8th character and you, for example want to get 8 character file name? In this case you split that 4 byte character and have garbage. What it user inputs in your text field (or a command line parameter or anywhere else) a string containing 4 byte character and you split that string on that character? (For example when showing some kind of summary of his input.) Don't forget that user can input characters by copy-pasting them from the web, not only using his keyboard!
So, if you want to write PROFESSIONAL software with any user input - you must handle 4 byte characters at every place you get user input. Otherwise you leave a chance to get and show to the user garbage. Is this really easier than using UTF8 everywhere?
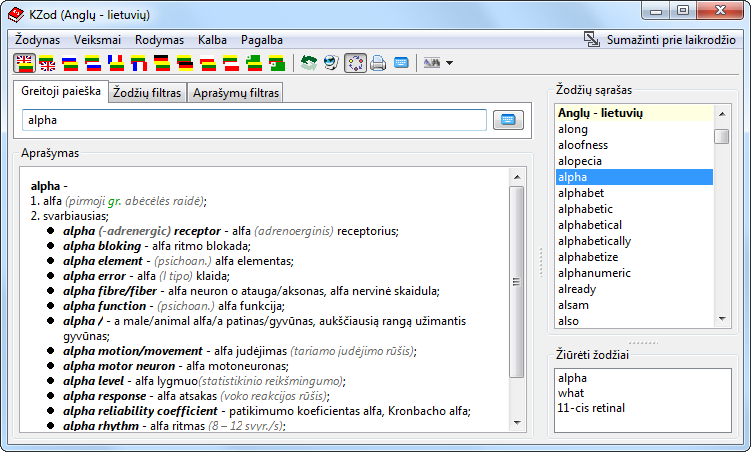
My personal experience: I am maintaining (as a hobby project) multi-language dictionary program (a screen-shoot: http://2.bp.blogspot.com/_3-IaodGIbVQ/TMHY-l9M4sI/AAAAAAAAAak/AbtShWq0ZUQ/s1600/KZod_screen_win7.png ) and it involves quite a bit of [multilingual] string manipulation and when I did migration from delphi to Lazarus I didn't know about requirement that all (GUI) strings must be UTF8 and I had no problems migrating! Yes, afterwards I tweaked some calls to RTL (mostly file handling) functions that expected to get ANSI encoding, but this is not a problem of UTF8, but or RTL being (mostly) ansi.
{kind=link}
Regards, Žilvinas Ledas -- _______________________________________________ Lazarus mailing list [email protected] http://lists.lazarus.freepascal.org/mailman/listinfo/lazarus