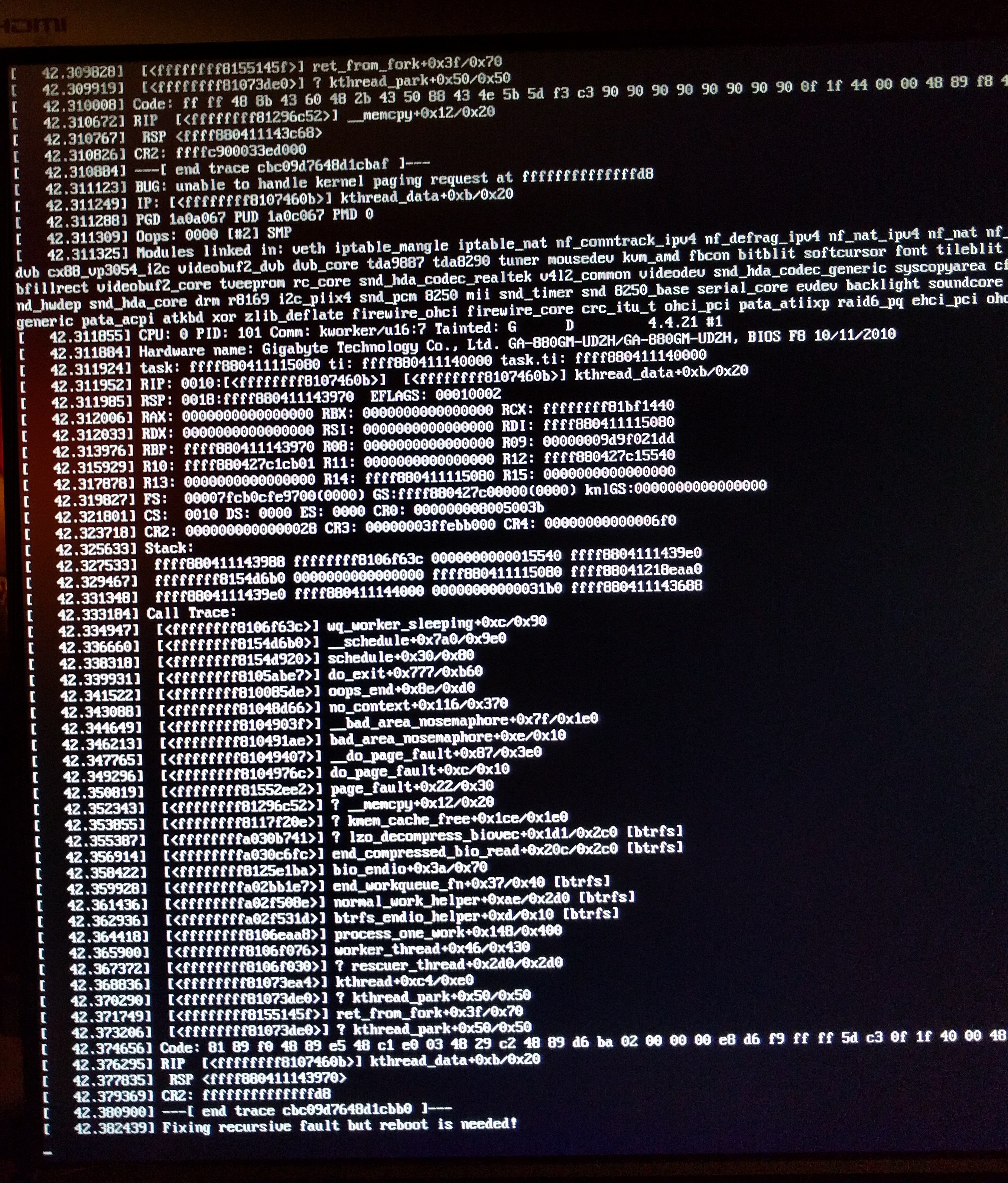
Rich Freeman posted on Thu, 22 Sep 2016 07:18:35 -0500 as excerpted: > I have been getting panics consistently after doing a btrfs replace > operation on a raid1 and rebooting. I linked a photo of the panic; I > haven't been able to get a text capture of it. > > https://ibin.co/2vx0HhDeViu3.jpg > > I'm getting this error on the latest 4.4, 4.1, and even on an old > 3.18.26 kernel I had lying around. > > I tried the remove root_log_ctx from ctx list before btrfs_sync_log > returns patch on 4.1 and that did not solve my problem either. > > I'm able to boot into single-user mode and if I don't start any > processes the system seems fairly stable. I am also able to start a > btrfs balance and run that for several hours without issue. If I start > launching services the system will tend to panic, though how many > processes I can launch will vary. I don't think that it is a particular > file being accessed that is triggering the issue since the point where > it fails varies. I suspect it may be load-related. > > Mounting with compress=no doesn't seem to help either. Granted, I see > lzo_decompress in the backtrace and that is probably a read operation. > > Any suggestions? Google hasn't been helpful on this one...
{kind=link}
Btrfs raid1 you say, and you have existing compressed files it's trying to read in the backtrace? Sounds like the issues I see sometimes and have posted about where after a crash that resulted in one device of my raid1 pair getting behind the other, the kernel will crash if it sees too many csum-errors, even tho it's /supposed/ to check the other copy and read from it if valid (which it is as a btrfs scrub resolves the issue). When booted to rescue/single-user mode, can you run a scrub? If it's the csum-related problem I see and the replace worked, a scrub should complete fine, repairing the bad copy from the mirror, and the problem should be resolved. If the replace bugged out and you now have only one copy of some chunks, if scrub finds an error there it obviously won't be able to repair from the good mirror, but it should at least spot some csum errors it can't repair. If a scrub crashes too, if it completes without finding any errors to correct, or if it finds and corrects errors but the issue persists, then it's unlikely to be the issue I've seen. FWIW, the issue I've seen appears to be related to attempts to read compressed files. It does not appear to affect users who don't have any such files or do but they're simply not accessed in ordinary operations. It may or may not affect other than raid1 and likely raid10, but they make it easiest to verify due to the possibility of one copy getting out of sync with the other, and due to scrub's ability to confirm that as the problem as it can repair the bad copy from the good one, which the kernel should do dynamically as well, but that's where the bug is as too many dynamic csum errors trigger a crash even when there's a second copy available, that scrub later verifies as valid. -- Duncan - List replies preferred. No HTML msgs. "Every nonfree program has a lord, a master -- and if you use the program, he is your master." Richard Stallman -- To unsubscribe from this list: send the line "unsubscribe linux-btrfs" in the body of a message to majord...@vger.kernel.org More majordomo info at http://vger.kernel.org/majordomo-info.html