However my fundamental concerns about the policy whether to disable the sched
tick remain:
Mixing the precise timer and vague heuristic for the decision is
dangerous. The timer should not be wrong, heuristic may be.
Well, I wouldn't say "dangerous". It may be suboptimal, but even that is not
a given. Besides ->
Decisions should use actual time points rather than the generic tick
duration and residency time. e.g.
expected_interval < delta_next_us
vs
expected_interval < TICK_USEC
-> the role of this check is to justify taking the overhead of stopping the
tick and it certainly is justifiable if the governor doesn't anticipate any
wakeups (timer or not) in the TICK_USEC range. It may be justifiable in
other cases too, but that's a matter of some more complex checks and may not
be worth the extra complexity at all.
I tried that change. It's just just a bit bulky because I
cache the result of ktime_to_us(delta_next) early.
diff --git a/drivers/cpuidle/governors/menu.c b/drivers/cpuidle/governors/menu.c
index a6eca02..cad87bf 100644
--- a/drivers/cpuidle/governors/menu.c
+++ b/drivers/cpuidle/governors/menu.c
@@ -296,6 +296,7 @@ static int menu_select(struct cpuidle_driver *drv, struct
cpuidle_device *dev,
unsigned long nr_iowaiters, cpu_load;
int resume_latency = dev_pm_qos_raw_read_value(device);
ktime_t delta_next;
+ unsigned long delta_next_us;
if (data->needs_update) {
menu_update(drv, dev);
@@ -314,6 +315,7 @@ static int menu_select(struct cpuidle_driver *drv, struct
cpuidle_device *dev,
/* determine the expected residency time, round up */
data->next_timer_us =
ktime_to_us(tick_nohz_get_sleep_length(&delta_next));
+ delta_next_us = ktime_to_us(delta_next);
get_iowait_load(&nr_iowaiters, &cpu_load);
data->bucket = which_bucket(data->next_timer_us, nr_iowaiters);
@@ -364,7 +366,7 @@ static int menu_select(struct cpuidle_driver *drv, struct
cpuidle_device *dev,
*/
if (data->predicted_us < TICK_USEC)
data->predicted_us = min_t(unsigned int, TICK_USEC,
- ktime_to_us(delta_next));
+ delta_next_us);
} else {
/*
* Use the performance multiplier and the user-configurable
@@ -412,9 +414,7 @@ static int menu_select(struct cpuidle_driver *drv, struct
cpuidle_device *dev,
* expected idle duration is shorter than the tick period length.
*/
if ((drv->states[idx].flags & CPUIDLE_FLAG_POLLING) ||
- expected_interval < TICK_USEC) {
- unsigned int delta_next_us = ktime_to_us(delta_next);
-
+ expected_interval < delta_next_us) {
*stop_tick = false;
if (!tick_nohz_tick_stopped() && idx > 0 &&
This works as a I expect in the sense of stopping the tick more often
and allowing deeper sleep states in some cases. However, it
drastically *increases* the power consumption for some affected
workloads test system (SKL-SP).
So while I believe this generally improves the behavior - I can't
recommend it based on the practical implications. Below are some
details for the curious:
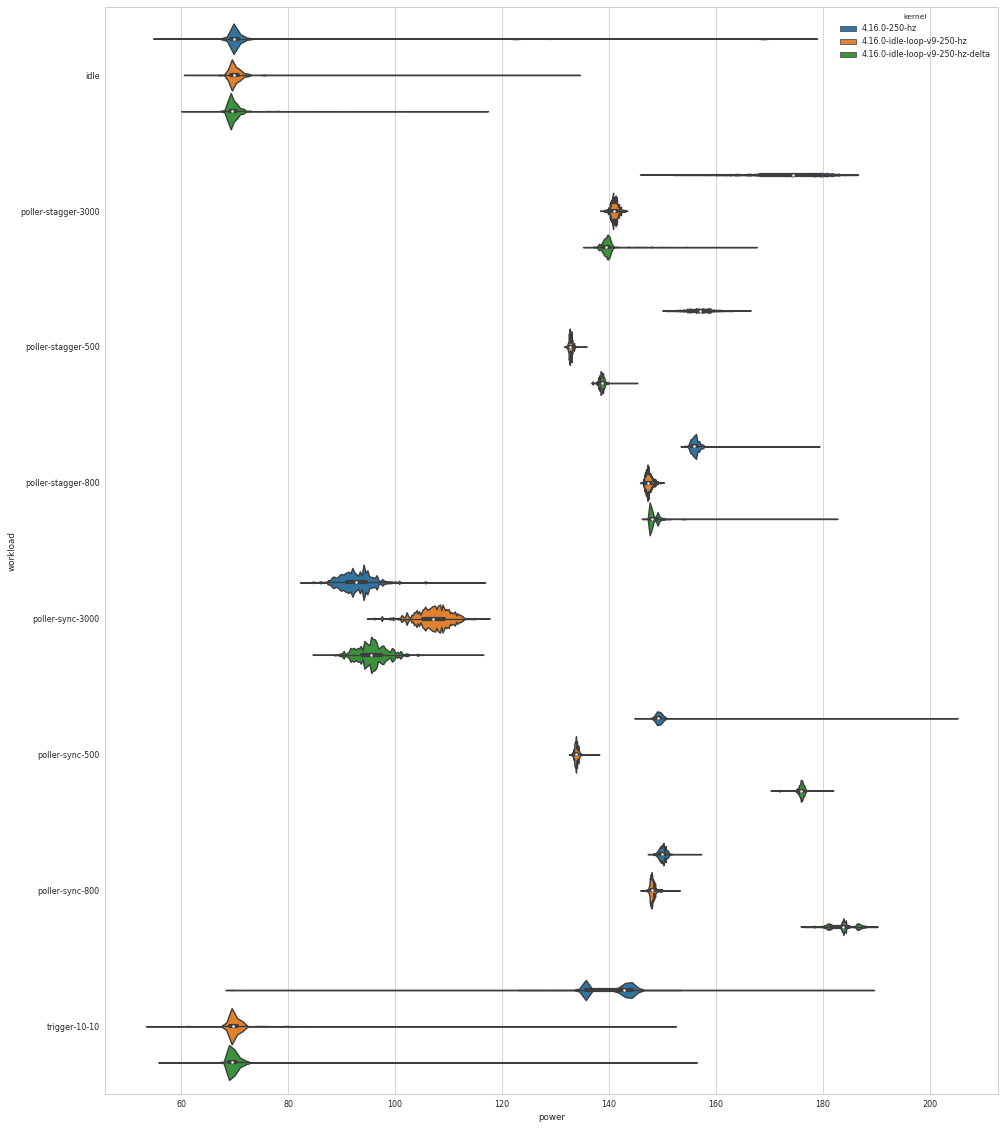
power consumption for various workload configurations with 250 Hz
kernels 4.16.0, v9, v9+delta_next patch:
https://wwwpub.zih.tu-dresden.de/~tilsche/powernightmares/v9_250_Hz_power.png
Practically v9 has the best power consumption in most cases.
The following detailed looks are with 1000 Hz kernels.
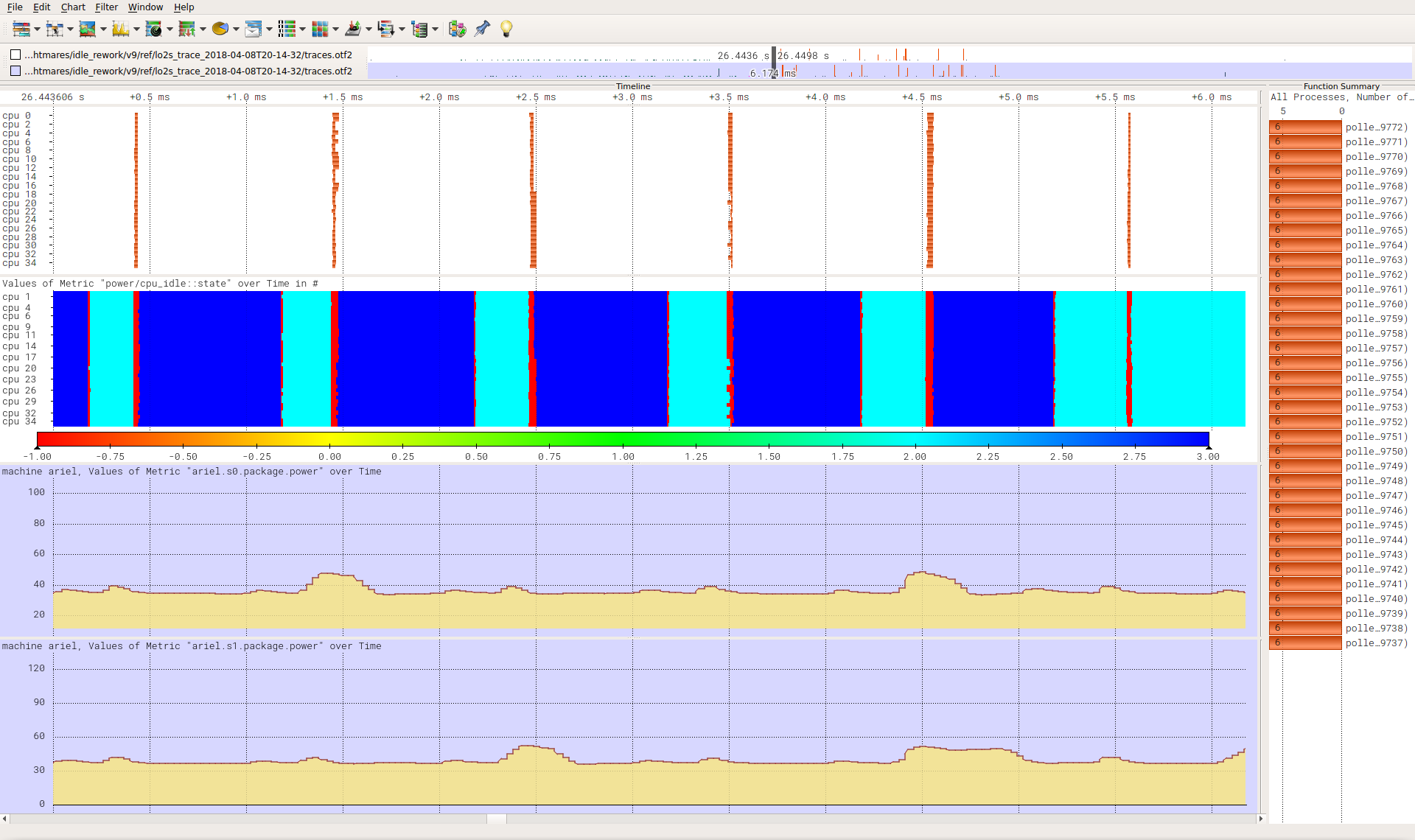
v9 with a synchronized 950 us sleep workload:
https://wwwpub.zih.tu-dresden.de/~tilsche/powernightmares/v9_poll_sync.png
v9 with a staggered 950 us sleep workload:
https://wwwpub.zih.tu-dresden.de/~tilsche/powernightmares/v9_poll_stagger.png
Both show that the sched tick is kept on and this causes more requests
to C1E than C6
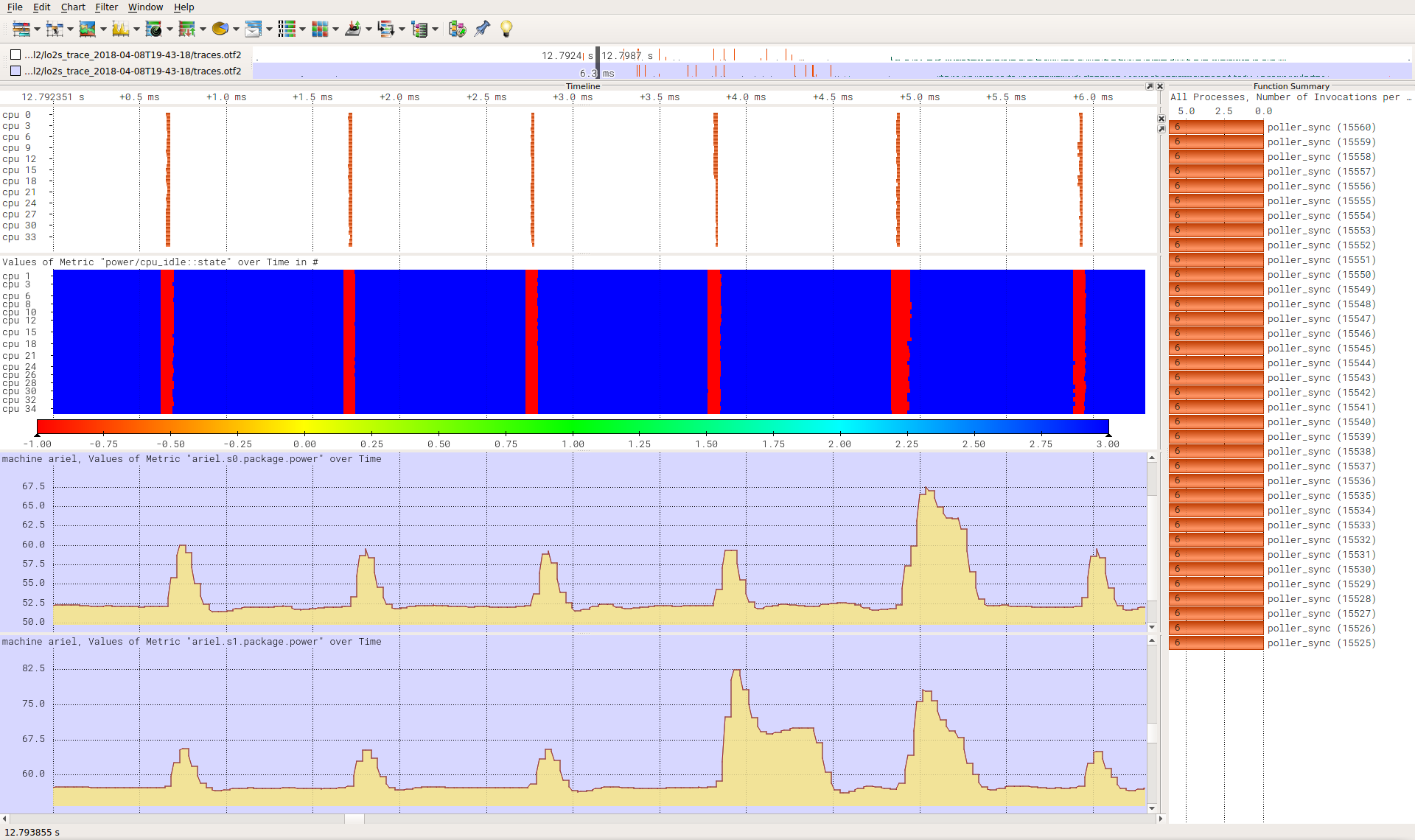
v9+delta_next with a synchronized 950 us sleep workload:
https://wwwpub.zih.tu-dresden.de/~tilsche/powernightmares/v9_delta_poll_sync.png
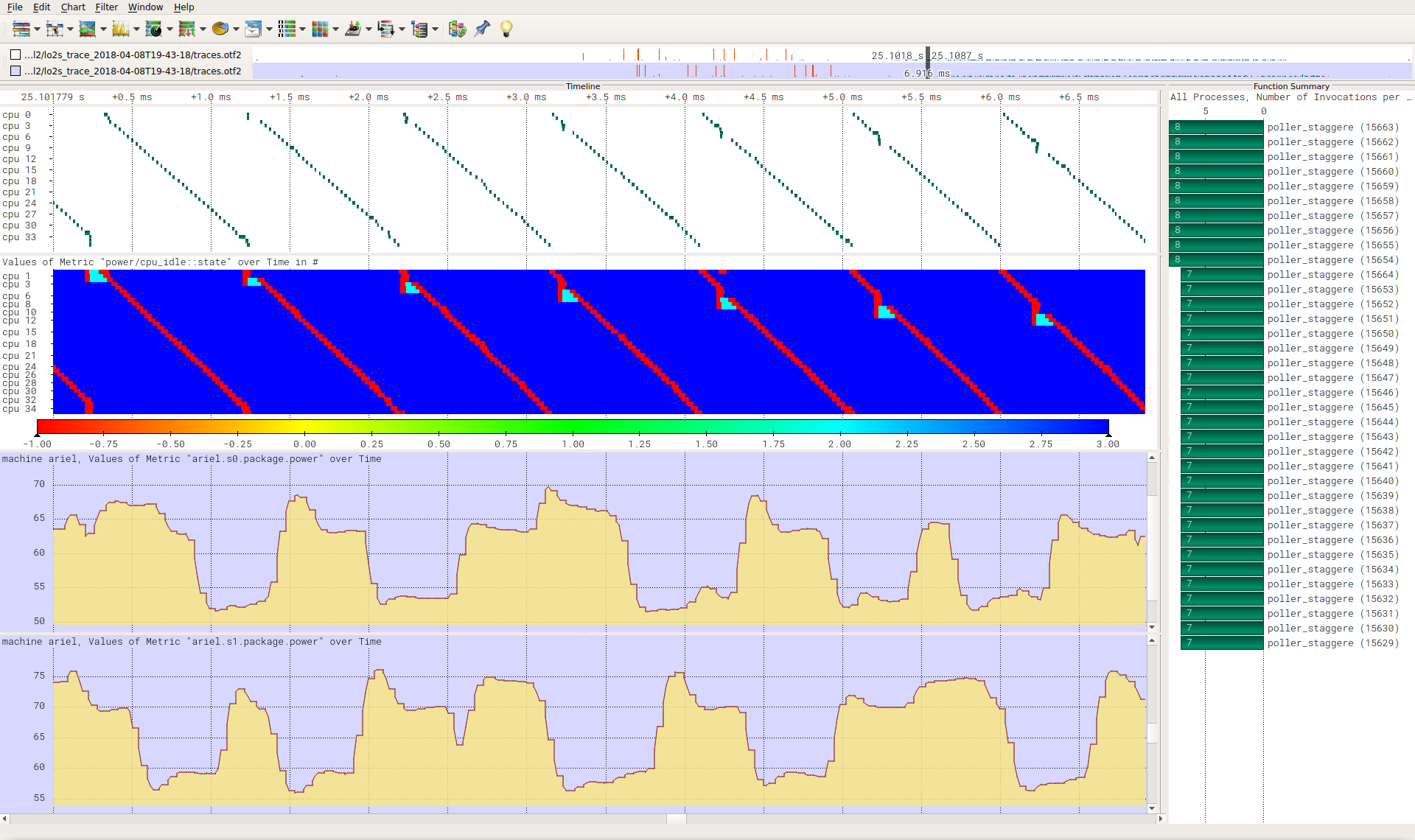
v9+delta_next with a staggered 950 us sleep workload:
https://wwwpub.zih.tu-dresden.de/~tilsche/powernightmares/v9_delta_poll_stagger.png
No more sched tick, no more C1E requests, but increased power.
Besides:
- the hardware reports 0 residency in C6 (both core and PKG) for
both v9 and v9+delta_next_us.
- the increased power consumption comes after a ramp-up of ~200 ms
for the staggered and ~2 s for the synchronized workload.
For reference traces from an unmodified 4.16.0:
https://wwwpub.zih.tu-dresden.de/~tilsche/powernightmares/v4.16.0_poll_sync.png
https://wwwpub.zih.tu-dresden.de/~tilsche/powernightmares/v4.16.0_poll_stagger.png
It behaves similar to the delta_next patch but does not show the
increased power consumption in this exact workload configuration.
I couldn't help to dig into the effect a bit more and am able to
reproduce it even under unmodified kernels with staggered sleep cycles
between ~1.2 ms and ~2.5 ms where power is increased by > 40 W.
Anyway, this effect seems to be beyond what the governor should
consider. It is an example where it doesn't seem possible to decide
for the optimal C state without considering the state of other cores
and such unexpected hardware behavior.
And these are only the results from one system and a limited set of
workload configurations.
For some cases the unmodified sched tick is not efficient as fallback.
Is it feasible to
1) enable the sched tick when it's currently disabled instead of
blindly choosing a different C state?
It is not "blindly" if you will. It is very much "consciously". :-)
Restarting the tick from within menu_select() wouldn't work IMO and
restarting it from cpuidle_idle_call() every time it was stopped might
be wasteful.
It could be done, but AFAICS if the CPU in deep idle is woken up by an
occasional interrupt that doesn't set need_resched, it is more likely
to go into deep idle again than to go into shallow idle at that point.
2) modify the next upcoming sched tick to be better suitable as
fallback timer?
Im not sure what you mean.
I think with the infrastructure changes it should be possible to
implement the policy I envisioned previously
(https://marc.info/?l=linux-pm&m=151384941425947&w=2), which is based
on the ordering of timers and the heuristically predicted idle time.
If the sleep_length issue is fixed and I have some mechanism for a
modifiable fallback timer, I'll try to demonstrate that on top of your
changes.
Sure. I'm not against adding more complexity to this in principle, but there
needs to be a good enough justification for it.
As I said in one of the previous messages, if simple code gets the job done,
the extra complexity may just not be worth it. That's why I went for very
simple code here. Still, if there is a clear case for making it more complex,
that can be done.
Thanks!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}