On Sun, 13 Apr 2014, Slawomir Pryczek wrote: > So high evictions when cleaning algo isn't enabled could be caused by slab > imbalance due to high-memory slabs eating most of ram... and i just > incorrectly assumed low TTL items are expired before high TTL items, because > in such cases the cache didn't have enough memory to store all low TTL > items, and both - low and high TTL's were evicted, interesting...
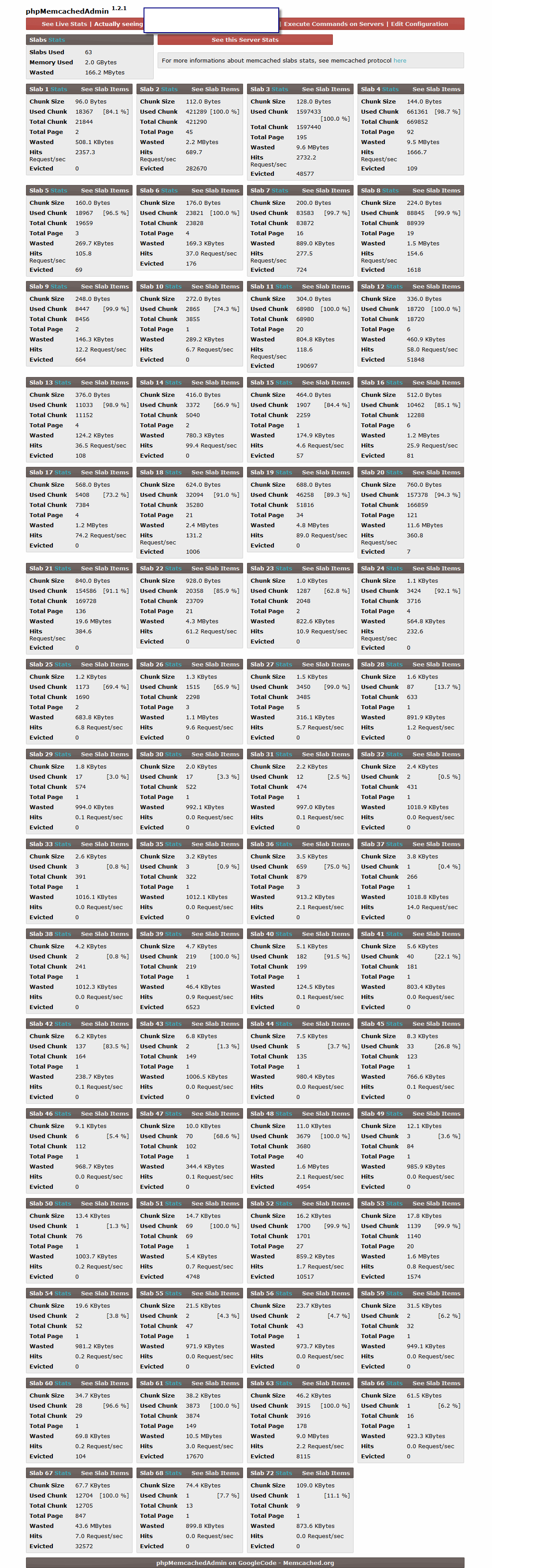
yes. > So you're saying if i set some item X, to evict it - i'd need to write AT > LEAST as many new items as as X's slab contains, because item will be > added on head, and you're removing from tail, right? yes. It's actually worse than that, since deleting items or fetching expired ones will make extra room, slowing it down. > Sending some slab stats, and TTL left for slab 1 where there are no evictions > + slab 2 where there is plenty. Unfortunately i can't send dumps as > these contain some sensitive data. > http://img.liczniki.org/20140414/slabs_all_918-1397431358.png Can you *please* sent a text dump of stats items and stats slabs? Just grep out or censor what you don't want to share? Doing math against a picture is a huge annoyance. It's also missing important counters I'd like to look at. > For ratio of long/short hard to tell... but most are definitely short. > > >Slab class 3 has 1875968 total chunks in your example, which means in > >order to cause a 120s item to evict early you need to insert into *that > >slab class* at a rate of 15,000 items per second, unless it's a multi-hour > >item instead. In which case what you said is happening but reversed: lots > >of junk 120s items are causing 5hr items to evict, but after many minutes > >and definitely not mere seconds. > > Yes but as you can see this class only contains 15% of valid data and have > plenty of evictions. The next class contains 7% valid data, but still > have 4 evictions. Probably would be best just to keep TTLs same for all > data... Your main complaint has been that 120s values don't persist for more than 60s, there's a 0% chance of any items in slab class 3 having a TTL of 120s. If you kept the TTL's all the same, what would they be? If they were all 120s and you rebalanced slabs, you'd probably never have a problem (but it seemed like you needed some data for longer). > > > > > > > > > W dniu niedziela, 13 kwietnia 2014 21:12:43 UTC+2 użytkownik Dormando napisał: > > Hey Dormando... > > > > Some quick question first... i have checked some Intel papers on > their memcached fork and for 1.6 it seems that there's some rather > big lock > > contention... have you thought about just "gluing" individual items > to a thread, using maybe item hash or some configurable method... > this way 2 > > threads won't be able to access same item at one time. I'm wondering > what whould be problems with such approach because it seems > rational at first > > glance, instead of locking the whole cache... im just curious. Is > there some release plan for 1.6... i think 2-3 years ago it was in > > developement... you're getting closer to releasing it? > > 1.4 tree has much less lock contention than 1.6. I made repeated calls > for > people to help pull bugs out of 1.6 and was ignored, so I ended up > continuing development against 1.4... There's no whole-cache lock in > 1.4, > there's a whole-LRU lock but the operations are a lot shorter. It's much > much faster than the older code. > > > Im not ignoring your posts, actually i read them but didn't want that > my posts were too large. Actually we tried using several other > things beside > > memcached. After switching from mysql with some memory tables to > memcached ~2 years ago measured throughput went from 40-50 req/s to > about 4000 > > r/s. Back then it was fine, then when traffic went higher the cache > was no longer able to evict items almost at all. > > > > Changing infrastructure in project that was in developement for over > 2 years is not easy thing. We also tested some other things like > mongodb, > > redis back then... and we just CAN'T have this data to be hitting > disks. Maybe now there are more options, but we are already > considering golang or > > C rewrite for this part... we don't want to switch to some other > "shared memory"-ish system, just be able to access data directly > between calls and > > do locking ourselves. > > > > So, again, as for current solution, decisions about what tools we use > were made a very long time ago, and are not easy to change now. > > > > >Almost instant evictions; so an item is stored, into a 16GB > instance, and < 120 seconds later is bumped out of the LRU? > > > > Yes, the items we insert for TTL=120 to 500s are not able to hold in > cache even for 60s, when we start to read/aggregate them, and > are thrown away > > instead of garbage. I understand why is that... > > S - short TTL > > L - long TTL > > SSSSSSSLSSS -> when we insert L item, no S items before L will be > able to get reclaimed, with current algo, ever. Because new L > items, will appear > > later too... for LRU to work optimially under high loads, every item > should have nearly the same TTL in given slab. You could try to > reclaim from > > top and bottom but this way one "hold forever" item would break the > whole thing as soon as it't get to top. > > I understand this part, I just find it suspicious. > > > Longest items in pool are set for 5-6h. And unfortunately item size > is no way correlated to TTL. We eg. store UA analyze and geo data > for 5h. These > > items are very short, as short as eg. impression counters. > > Ok. Any idea what the ratio to long to short is? like 10% 120s, 90% 5h, > or > reverse or whatever? > > > >You'll probably just ignore me again, but isn't this just slab > imbalance? > > No it isn't... how in hell can slab imbalance happen over just 1h, > without code changes ;) > > I can make slab imbalance happen in under 10 seconds. Not really the > point: Slab pages are pulled from the global pool as-needed as memory > fills. If your traffic has ebbs and flows, or tends to set a lot more > items in one class than others it will immediately fill and others will > starve. > > > >A better way to do this is to bucket the memory by TTL. You have > lots of > > >pretty decent options for this (and someone else already suggested > one) > > Sure, if we knew back then we'd just create 3-4 memcached instances, > add some API and shard the items based on requested TTL. > > You can't do that now? That doesn't really seem that hard and doesn't > change the fundamental infrastructure... It'd be a lot easier than > maintaining your own fork of memcached forever, I'd think. > > > >The slab rebalance system lets you plug in your own algorithm by > running >the page reassignment commands manually. Then you can > smooth out the > > pages > > >to where you think they should be. > > Sure, but that's actually not my problem... the problem is that im > having full of "expired" items, so this would require some hacking > of that slab > > rebalance algo (am i right?)... and it seems a little complicated to > me, to be done in 3-4 days time. > > Bleh. > > > >A better way to do this is to bucket the memory by TTL. You have > lots of > > >pretty decent options for this (and someone else already suggested > one)Haha, sure it's better :) We'd obviously have done that if we > knew 2 years > > ago what we know now :) > > > > I actually wrote a quick code to "redirect" about 20% of traffic > we're sending/receiving to/from memcached to my "hacked" version... > for all times > > on screens you neet to do minus 5 minutes (we run memcached, then > enabled the code 5 minutes after it was started)... > > > > How situation develops: > > http://screencast.com/t/YZCR2uc1bd > > http://screencast.com/t/pvCmbo13z6T > > http://screencast.com/t/MLwgvKzaeE > > > > Still no evictions: > > http://screencast.com/t/BJuz8l5c > > > > Full of 100% utulized slab classes: > > http://screencast.com/t/vTlFahoR > > > > After cleaning using hack some of these classes have only 10% of > non-expired items. > > http://screencast.com/t/z39z7U1TNW2 > > > > With current items TTL we insert into cache it can eat any amount of > memory. I think the problem was diagnosed correctly as just > problem with > > reclaiming algo (or our usage patters, looking from other side)... > > That's a 2G instance, and you can clearly see that two of those slab > classes only have 14 and 20 megabytes of data assigned to them. Another > one has 206 megabytes but only 4 evictions. This thing is also hiding a > lot of information... can we see the actual dumps? > > What's evicted_nonfetched? What's evicted_time? What's the full textual > output of "stats slabs" and "stats items" ? > > The thing that bothers me, is that in order for a 120 second item to be > evicted before it expires, you need to insert more data ahead of it than > will fit in the entire slab class within that period of time: > > Slab class 3 has 1875968 total chunks in your example, which means in > order to cause a 120s item to evict early you need to insert into *that > slab class* at a rate of 15,000 items per second, unless it's a > multi-hour > item instead. In which case what you said is happening but reversed: > lots > of junk 120s items are causing 5hr items to evict, but after many > minutes > and definitely not mere seconds. > > Your other screenshots indicate that your *global* set rate is closer to > 3,500. So even in this 2GB instance, and even with 5-6 hour items mixed > in, 120s items should never be blown out of slab class 3. 5-6 hour items > might be, but in that case we can argue that the instance is simply way > too small. Your screenshot also only accounts for 400 out of the 2000 > pages that should be in there. What's tying up the other 1600 pages? > > The classes at the bottom (11, 12) are much smaller and have far fewer > pages: 48286 chunks in 11, which only requires a set rate of 402/s to > blow the top off of for a 120s item. > > So yes, I absolutely think it's off balanced or sized wrong. I also > absolutely agree that doing some sort of internal cleaning would make > the > memory usage more efficient and reduce your evictions: I believe you > here. > However it's difficult to implement without causing extra latency, > again, > as you've seen. It's also going to work too aggressively since you're > trying store too many of them within a 40 megabyte subset of this 2000 > megabyte cachie instance! > > I'm also a bit worried that you may have been hitting some item > immortality issues: the current master branch has fixed a few of those > (and I suck for not getting it released yet). Refcount leaks and things. > Perhaps your patch was ungluing the bugs accidentally by killing > immortalized items. > > However, a properly sized instance with more carefully balanced slabs > would probably operate a lot better than what you're doing now. It may > also make your existing patch more efficient: as making it far less > likely > for a page-starved slab class to have to scan many items before finding > expired ones. :) > > I've wanted to implement an LRU "skimmer" but it's not exactly easy and > still relies on luck. It's what FB ended up doing but they extended it > in > some ways: I think it's literally arbitrary code to match items as it > crawls the LRU's from a background thread. > > ultimately a combination of page rebalance + an LRU skimmer would be > most > optimal. Having enough memory available and properly balanced pages > means > your "relcaimer/garbage collector" has to work less hard. This is a > universal truth in all garbage collected languages: if you don't want it > to impact latency, do things to make it work less. MC's default goes to > the extreme of never garbage collecting, since the use case is that > items > which don't ever get fetched have no value. > > > > > > > > > > > > > > > > > W dniu piątek, 11 kwietnia 2014 20:06:23 UTC+2 użytkownik Dormando > napisał: > > > > > > On Fri, 11 Apr 2014, Slawomir Pryczek wrote: > > > > > Hi Dormando, more about the behaviour... when we're using > "normal" memcached 1.4.13 16GB of memory gets exhausted in ~1h, > then we > > start to have > > > almost instant evictions of needed items (again these items > aren't really "needed" individually, just when many of them gets > evicted > > it's > > > unacceptable because of how badly it affects the system) > > > > Almost instant evictions; so an item is stored, into a 16GB > instance, and > > < 120 seconds later is bumped out of the LRU? > > > > You'll probably just ignore me again, but isn't this just slab > imbalance? > > Once your instance fills up there're probably a few slab > classes with way > > too little memory in them. > > > > 'stats slabs' shows you per-slab eviction rates, along with the > last > > accessed time of an item when it was evicted. What does this > look like on > > one of your full instances? > > > > The slab rebalance system lets you plug in your own algorithm > by running > > the page reassignment commands manually. Then you can smooth > out the pages > > to where you think they should be. > > > > You mention long and short TTL, but what are they exactly? 120s > and an > > hour? A week? > > > > I understand your desire to hack up something to solve this, > but as you've > > already seen scanning memory to remove expired items is > problematic: > > you're either going to do long walks from the tail, use a > background > > thread and walk a "probe" item through, or walk through random > slab pages > > looking for expired memory. None of these are very efficient > and tend to > > rely on luck. > > > > A better way to do this is to bucket the memory by TTL. You > have lots of > > pretty decent options for this (and someone else already > suggested one): > > > > - In your client, use different memcached pools for major TTL > buckets (ie; > > one instance only gets long items, one only short). Make sure > the slabs > > aren't imbalanced via the slab rebalancer. > > > > - Are the sizes of the items correlated with their TTL? Are > 120s items > > always in a ~300 byte range and longer items tend to be in a > different > > byte range? You could use length pagging to shunt them into > specific slab > > classes, separating them internally at the cost of some ram > efficiency. > > > > - A storage engine (god I wish we'd made 1.6 work...) which > allows > > bucketing by TTL ranges. You'd want a smaller set of slab > classes to not > > waste too much memory here, but the idea is the same as running > multiple > > individual instances, except internally splitting the storage > engine > > instead and storing everything in the same hash table. > > > > Those three options completely avoid latency problems, the > first one > > requires no code modifications and will work very well. The > third is the > > most work (and will be tricky due to things like slab > rebalance, and none > > of the slab class identification code will work). I would avoid > it unless > > I were really bored and wanted to maintain my own fork forever. > > > > > ~2 years ago i created another version based on that 1.4.13, > than does garbage collection using custom stats handler. That > version is > > able to be > > > running on half of the memory for like 2 weeks, with 0 > evictions. But we gave it full 16G and just restart it each week to be > sure > > memory usage is > > > kept in check, and we're not throwing away good data. > Actually after changing -f1.25 to -f1.041 the slabs are filling with > bad items > > much slower, > > > because items are distributed better and this custom eviction > function is able to catch more expired data. We have like 200GB > of data > > evicted this > > > way, daily. Because of volume (~40k req/s peak, much of it > are writes) and differences in expire time LRU isn't able to > reclaim items > > efficiently. > > > > > > Maybe people don't even realize the problem, but when we done > some testing and turned off that "custom" eviction we had like > 100% > > memory used with > > > 10% of waste reported by memcached admin. But then we run > that custom eviction algorithm it turned out that 90% of memory is > occupied > > by garbage. > > > Waste reported grew to 80% instantly after running unlimited > "reclaim expired" on all items in the cache. So in "standard" > client > > when people will > > > be using different expire times for items (we have it like > 1minute minimum, 6h max)... they even won't be able to see how > much memory > > they're > > > wasting in some specific cases, when they'll have many items > that won't be hit after expiration, like we have. > > > > > > When using memcached as a buffer for mysql writes, we know > exactly what to hit and when. Short TTL expired items, pile up > near the > > head... long TTL > > > "live" items pile up near the tail and it's creating a > barrier that prevents the LRU algo to reclaim almost anything, if im > getting > > how it > > > currently works, correctly... > > > > > > >You made it sound like you had some data which never > expired? Is this true? > > > Yes, i think because of how evictions are made (to be clear > we're not setting non-expiring items). These short expiring items > pile up > > in the front > > > of linked list, something that is supposed to live for eg. > 120 or 180 seconds is lingering in memory forever, untill we > restart the > > cache... and > > > new items are killed almost instantly because there are no > expired items on head. > > > > > > It's a special case, because after processing memory list, > aggregating data and putting it in mysql these items are no longer > > touched. The list for > > > new time period will have completely different set of keys. > As we use a prefix to generate all items in the list. > > > > > > $time_slice = floor( self::$time / 60) - $time_slices_back; > > > $prefix = ")ML){$list_id}-{$time_slice}"; > > > > > > Again, not saying current implementation is bad... because > it's fast and doesn't trash CPU cache when expire times are > ~equal, that > > was probably > > > the idea... but we have not typical use case, which LRU isn't > able to manage... > > > > > > Now im making ~same changes i made for .13... but for .17 and > i want to make it working a little better ;) > > > > > > > > > > > > W dniu piątek, 11 kwietnia 2014 05:12:10 UTC+2 użytkownik > Dormando napisał: > > > > > > > Hey Dormando, thanks again for some comments... > appreciate the help. > > > > > > > > Maybe i wasn't clear enough. I need only 1 minute > persistence, and i can lose data sometimes, just i can't keep > loosing data > > every > > > minute due to > > > > constant evictions caused by LRU. Actually i have > just wrote that in my previous post. We're loosing about 1 minute > of > > > non-meaningfull data every > > > > week because of restart that we do when memory starts > to fill up (even with our patch reclaiming using linked list, > we limit > > > reclaiming to keep > > > > speed better)... so the memory fills up after a week, > not 30 minutes... > > > > > > Can you explain what you're seeing in more detail? Your > data only needs to > > > persist for 1 minute, but it's being evicted before 1 > minute is up? > > > > > > You made it sound like you had some data which never > expired? Is this > > > true? > > > > > > If your instance is 16GB, takes a week to fill up, but > data only needs to > > > persist for a minute but isn't, something else is very > broken? Or am I > > > still misunderstanding you? > > > > > > > Now im creating better solution, to limit locking as > linked list is getting bigger. > > > > > > > > I explained what was worst implications of unwanted > evictions (or loosing all data in cache) in my use case: > > > > 1. loosing ~1 minute of non-significant data that's > about to be stored in sql > > > > 2. "flat" distribution of load to workers (not taking > response times into account because stats reset). > > > > 3. resorting to alternative targeting algorithm (with > global, not local statistics). > > > > > > > > I never, ever said im going to write data that have > to be persistent permanently. It's actually same idea as delayed > write. > > If power > > > fails you > > > > loose 5s of data, but you can do 100x more writes. So > you need the data to be persistent in memory, between writes > the data > > **can't > > > be lost**. > > > > However you can lose it sometimes, that's the > tradeoff that some people can make and some not. Obviously I can't keep > loosing > > this > > > data each > > > > minute, because if i loose much it'll become > meaningfull. > > > > > > > > Maybe i wasn't clear in that matter. I can loose all > data even 20 times a day. Sensitive data is stored using bulk > update or > > > transactions, > > > > bypassing that "delayed write" layer. "0 evictions", > that's the kind of "persistence" im going for. So items are > persistent > > for some > > > very short > > > > periods of time (1-5 minutes) without being killed. > It's just different use case. Running in production since 2 > years, based > > on > > > 1.4.13, tested for > > > > corectness, monitored so we have enough memory and 0 > evictions (just reclaims) > > > > > > > > When i came here with same idea ~2 years ago you just > said it's very stupid, now you even made me look like a moron > :) And i > > can > > > understand why you > > > > don't want features that are not ~O(1) perfectly, but > please don't get so personal about different ideas to do things > and use > > cases, > > > just because > > > > these won't work for you. > > > > > > > > > > > > > > > > > > > > > > > > W dniu czwartek, 10 kwietnia 2014 20:53:12 UTC+2 > użytkownik Dormando napisał: > > > > You really really really really really *must* > not put data in memcached > > > > which you can't lose. > > > > > > > > Seriously, really don't do it. If you need > persistence, try using a redis > > > > instance for the persistent stuff, and use > memcached for your cache stuff. > > > > I don't see why you feel like you need to write > your own thing, there're a > > > > lot of persistent key/value stores > (kyotocabinet/etc?). They have a much > > > > lower request ceiling and don't handle the > LRU/cache pattern as well, but > > > > that's why you can use both. > > > > > > > > Again, please please don't do it. You are > damaging your company. You are a > > > > *danger* to your company. > > > > > > > > On Thu, 10 Apr 2014, Slawomir Pryczek wrote: > > > > > > > > > Hi Dormando, thanks for suggestions, > background thread would be nice... > > > > > The idea is actually that with 2-3GB i get > plenty of evictions of items that need to be fetched later. And > with 16GB > > i still > > > get > > > > evictions, > > > > > actually probably i could throw more memory > than 16G and it'd only result in more expired items sitting in > the middle > > of > > > slabs, > > > > forever... Now im > > > > > going for persistence. Sounds probably crazy, > but we're having some data that we can't loose: > > > > > 1. statistics, we aggregate writes to DB > using memcached (+list implementation). If these items get evicted > we're > > loosing > > > rows in db. > > > > Loosing data > > > > > sometimes isn't a big problem. Eg. we restart > memcached once a week so we're loosing 1 minute of data every > week. But > > if we > > > have > > > > evictions we're > > > > > loosing data constantly (which we can't have) > > > > > 2. we drive load balancer using data in > memcached for statistics, again, not nice to loose data often because > workers > > can get > > > > incorrect amount of > > > > > traffic. > > > > > 3. we're doing some adserving optimizations, > eg. counting per-domain ad priority, for one domain it takes > about 10 > > seconds to > > > analyze > > > > all data and > > > > > create list of ads, so can't be done > online... we put result of this in memcached, if we loose too much of > this the > > system > > > will start > > > > to serve > > > > > suboptimal ads (because it'll need to switch > to more general data or much simpler algorithm that can be done > > instantly) > > > > > > > > > > Probably would be best to rewrite all this > using C or golang, and use memcached just for caching, but it'd > take too > > much time > > > which > > > > we don't have > > > > > currently... > > > > > > > > > > I have seen twitter and nk implementations > that seem to do what i need, but they seem old (based on old > code), so I > > prefer to > > > modify > > > > code of recent > > > > > "official" memcached, to not be stuck with > old code or abandonware. Actually there are many topics about > limitations > > of > > > currrent > > > > eviction algo and > > > > > option to enable some background thread to do > scraping based on statistics of most filled slabs (with some > parameter > > to > > > specify if it > > > > should take > > > > > light or aggressive approach) would be nice... > > > > > > > > > > As for the code... is that > slab_rebalance_move function in slab.c? It seems a little difficult to gasp > without some > > DOCs of > > > how > > > > things are > > > > > working... can you please write a very short > description of how this "angry birds" more workd? > > > > > > > > Look at doc/protocol.txt for explanations of > the slab move options. the > > > > names are greppable back to the source. > > > > > > > > > I have quick question about this above... > linked is item that's placed on linked list, but what other flags > means, > > and why 2 > > > last are > > > > 2 of them > > > > > temporary? > > > > > #define ITEM_LINKED 1 > > > > > #define ITEM_CAS 2 > > > > > > > > > > /* temp */ > > > > > #define ITEM_SLABBED 4 > > > > > #define ITEM_FETCHED 8 > > > > > > > > > > This from slab_rebalance_move seems > interesting: > > > > > refcount = refcount_incr(&it->refcount); > > > > > ... > > > > > if (refcount == 1) { /* item is unlinked, > unused */ > > > > > ... > > > > > } else if (refcount == 2) { /* item is linked > but not busy */ > > > > > > > > > > Is there some docs about refcounts, locks and > item states? Basically why item with refcount 2 is not busy? > You're > > increasing > > > refcount > > > > by 1 on > > > > > select, then again when reading data? Can > refcount ever be higher than 2 (3 in above case), meaning 2 threads > can > > access same > > > item? > > > > > > > > The comment on the same line is explaining > exactly what it means. > > > > > > > > Unfortunately it's a bit of a crap shoot. I > think I wrote a threads > > > > explanation somewhnere (some release notes, or > in a file in there, I can't > > > > quite remember offhand). Since scaling the > thread code it got a lot more > > > > complicated. You have to be extremely careful > under what circumstances you > > > > access items (you must hold an item lock + the > refcount must be 2 if you > > > > want to unlink it). > > > > > > > > You'll just have to study it a bit, sorry. Grep > around to see where the > > > > flags are used. > > > > > > > > > Thanks. > > > > > > > > > > W dniu czwartek, 10 kwietnia 2014 06:05:30 > UTC+2 użytkownik Dormando napisał: > > > > > > Hi Guys, > > > > > > im running a specific case where i > don't want (actually can't have) to have evicted items (evictions > = 0 > > ideally)... > > > now i > > > > have > > > > > created some simple > > > > > > algo that lock the cache, goes > through linked list and evicts items... it makes some problems, like > 10-20ms > > cache > > > locks on > > > > some > > > > > cases. > > > > > > > > > > > > Now im thinking about going through > each slab memory (slabs keep a list of allocated memory regions) > ... > > looking for > > > items, > > > > if > > > > > expired item is > > > > > > found, evict it... this way i can go > eg. 10k items or 1MB of memory at a time + pick slabs with high > > utilization and > > > run this > > > > > "additional" eviction > > > > > > only on them... so it'll prevent > allocating memory just because unneded data with short TTL is > occupying HEAD > > of the > > > list. > > > > > > > > > > > > With this linked list eviction im > able to run on 2-3GB of memory... without it 16GB of memory is > exhausted in > > 1-2h > > > and then > > > > memcached > > > > > starts to > > > > > > kill "good" items (leaving expired > ones wasting memory)... > > > > > > > > > > > > Any comments? > > > > > > Thanks. > > > > > > > > > > you're going a bit against the base > algorithm. if stuff is falling out of > > > > > 16GB of memory without ever being > utilized again, why is that critical? > > > > > Sounds like you're optimizing the > numbers instead of actually tuning > > > > > anything useful. > > > > > > > > > > That said, you can probably just extend > the slab rebalance code. There's a > > > > > hook in there (which I called "Angry > birds mode") that drives a slab > > > > > rebalance when it'd otherwise run an > eviction. That code already safely > > > > > walks the slab page for unlocked memory > and frees it; you could edit it > > > > > slightly to check for expiration and > then freelist it into the slab class > > > > > instead. > > > > > > > > > > Since it's already a background thread > you could further modify it to just > > > > > wake up and walk pages for stuff to > evict. > > > > > > > > > > -- > > > > > > > > > > --- > > > > > You received this message because you are > subscribed to the Google Groups "memcached" group. > > > > > To unsubscribe from this group and stop > receiving emails from it, send an email to > [email protected]. > > > > > For more options, visit > https://groups.google.com/d/optout. > > > > > > > > > > > > > > > > > > -- > > > > > > > > --- > > > > You received this message because you are subscribed > to the Google Groups "memcached" group. > > > > To unsubscribe from this group and stop receiving > emails from it, send an email to [email protected]. > > > > For more options, visit > https://groups.google.com/d/optout. > > > > > > > > > > > > > > -- > > > > > > --- > > > You received this message because you are subscribed to the > Google Groups "memcached" group. > > > To unsubscribe from this group and stop receiving emails from > it, send an email to [email protected]. > > > For more options, visit https://groups.google.com/d/optout. > > > > > > > > > > -- > > > > --- > > You received this message because you are subscribed to the Google > Groups "memcached" group. > > To unsubscribe from this group and stop receiving emails from it, > send an email to [email protected]. > > For more options, visit https://groups.google.com/d/optout. > > > > > > -- > > --- > You received this message because you are subscribed to the Google Groups > "memcached" group. > To unsubscribe from this group and stop receiving emails from it, send an > email to [email protected]. > For more options, visit https://groups.google.com/d/optout. > > -- --- You received this message because you are subscribed to the Google Groups "memcached" group. To unsubscribe from this group and stop receiving emails from it, send an email to [email protected]. For more options, visit https://groups.google.com/d/optout.
{kind=link}