Thanks to Wes
at http://wes.skeweredrook.com/the-mythical-with-neo4js-cypher-query-language/
parsing the CommaSeparatedListOfIds above is not allowed. Instead do this:
MATCH (n)-[r]-()
WHERE id(n) IN CommaSeparatedListOfIds
DELETE r, n
On Monday, February 24, 2014 2:47:18 PM UTC-5, Alx wrote:
> Hi Kenny,
>
> Thank you for the post. It helped me with my duplicates removal. However
> when I try to run Step 2 I get the following error:
>
> Invalid input 'C': expected whitespace, an unsigned integer, a parameter or
> '*' (line 9, column 14)
> "START k=node(CommaSeparatedListOfIds)"
>
>
> I replaced the last sentence of Step 1 with the following:
>
> WITH COLLECT(DuplicateId) as CommaSeparatedListOfIds
>
> to connect to the Step 2 query.
>
> Any ideas? Am I missing something? Thanks a lot!
>
> On Wednesday, August 14, 2013 12:49:53 PM UTC-4, Kenny Bastani wrote:
>>
>> Hey all,
>>
>> The following 3 steps will allow you to using the admin console and
>> Cypher query to select and delete duplicate nodes by index and property.
>>
>> *STEP 1 (COLLECT duplicate nodes by ID):*
>>
>> START n=node:search("search:(\"TEXT MINING\")") // Cypher query for
>> collecting the ids of indexed nodes containing duplicate properties
>> WITH n
>> ORDER BY id(n) DESC // Order by descending to delete the most recent
>> duplicated record
>> WITH n.Key? as DuplicateKey, COUNT(n) as ColCount, COLLECT(id(n)) as
>> ColNode
>> WITH DuplicateKey, ColCount, ColNode, HEAD(ColNode) as DuplicateId
>> WHERE ColCount > 1 AND (DuplicateKey is not null) AND (DuplicateId is not
>> null)
>> WITH DuplicateKey, ColCount, ColNode, DuplicateId
>> ORDER BY DuplicateId
>> RETURN DuplicateKey, ColCount, DuplicateId // Toggle comment on/off for
>> validating duplicate records before moving to next step (do not proceed to
>> delete without validating)
>> //RETURN COLLECT(DuplicateId) as CommaSeparatedListOfIds
>>
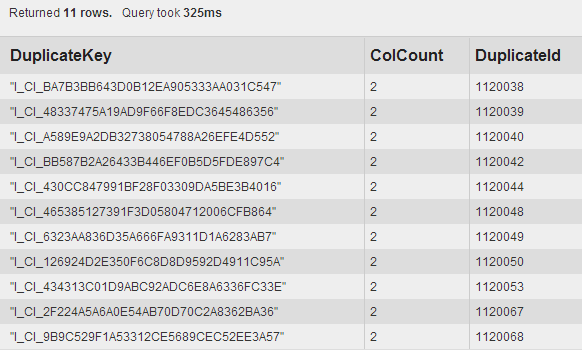
>> *Example output - validation screenshot:*
>>
>>
>> <https://lh6.googleusercontent.com/-fLaTfRuWS4M/UguyfiZs2LI/AAAAAAAAA2Y/bP9-dHFZtaM/s1600/validate-duplicates.PNG>
>>
>> *Example output - collected IDs that will be used in the next step:*
>>
>>
>> <https://lh5.googleusercontent.com/-yAsElzgm64w/UguywmR7rpI/AAAAAAAAA2g/bK0dtatJR4o/s1600/comma-separated-list-id-duplicates.PNG>
>>
>> *STEP 2 (DELETE duplicate nodes and connected relationships by ID):*
>>
>> START n=node(
>> 1120038,1120039,1120040,1120042,1120044,1120048,1120049,1120050,1120053,1120067,1120068
>> ) // Replace highlighted ids with CommaSeparatedListOfIds from step 1
>> MATCH n-[r]-() // Delete relationships for each duplicate before
>> deleting the node
>> DELETE r, n
>>
>> *STEP 3:*
>>
>> Re-run the query from the first step to make sure that the duplicate
>> nodes were deleted
>>
>> Thanks,
>>
>> Kenny
>>
>> Follow me on Twitter: http://www.twitter.com/kennybastani
>>
>> On Monday, January 28, 2013 2:36:38 AM UTC-5, Michael Hunger wrote:
>>>
>>> There is no automatic way of doing this in Neo4j.
>>> Usually that's a concern handled in application level code.
>>>
>>> You could for instance write a cypher statement that queries the
>>> relevant-sub-graph of the node, returns the identifying properties.
>>>
>>> Then hash the result rows and set them as a property on your
>>> aggregate-root node for future comparison. Might even be indexed.
>>> (Instead of hashing they could also be concatinated in a sensible way
>>> (e.g. path/to/property:value, ...)
>>>
>>> When inserting new data you can check for that hash and if matched deep
>>> check the subgraph with a dedicated cypher query (can all be in one query).
>>>
>>> If the data/structure is not there, create it.
>>>
>>> Michael
>>>
>>> Am 28.01.2013 um 00:42 schrieb Rory Madden <[email protected]>:
>>>
>>> Unique indexes are great to prevent duplicates being created but is
>>> there a suggested approach for identifying duplicates across the graph.
>>>
>>> E.g. with the movie graph if you don't implement unique indexes (because
>>> movies can have the same name) and two people create the same movie with
>>> the same actors is there a way to identify the duplication?
>>>
>>> Solr has MD5Signature, Lookup3Signature, TextProfileSignature algoritms
>>> for detecting duplicates but are there any examples of people using similar
>>> algorithms with Neo4j and the Lucene instance?
>>>
>>> Thanks,
>>> Rory
>>>
>>> On Saturday, 21 January 2012 06:37:28 UTC-3, Peter Neubauer wrote:
>>>>
>>>> You mean creating entries only if they exist?
>>>>
>>>> That came in 1.6.M03, see
>>>> http://docs.neo4j.org/chunked/snapshot/rest-api-unique-indexes.html
>>>> and
>>>> http://components.neo4j.org/neo4j/1.6.M03/apidocs/org/neo4j/graphdb/index/Index.html#putIfAbsent%28T,%20java.lang.String,%20java.lang.Object%29
>>>>
>>>> Cheers,
>>>>
>>>> /peter neubauer
>>>>
>>>> Google: neubauer.peter
>>>> Skype: peter.neubauer
>>>> Phone: +46 704 106975
>>>> LinkedIn: http://www.linkedin.com/in/neubauer
>>>> Twitter: @peterneubauer
>>>> Tungle: tungle.me/peterneubauer
>>>>
>>>> brew install neo4j && neo4j start
>>>> heroku addons:add neo4j
>>>>
>>>> On Fri, Jan 20, 2012 at 11:33 PM, Timothy Braun <[email protected]>
>>>> wrote:
>>>> > Hey Guys,
>>>> > Any suggestions for finding duplicate nodes based on a node index
>>>> ie,
>>>> > index on username property of a node?
>>>> >
>>>> > Also, is there any way to implement unique node constraints?
>>>> >
>>>> > Thanks,
>>>> > Tim
>>>>
>>>>
>>>>
>>>>
>>>>
>>>>
>>>>
>>> --
>>> You received this message because you are subscribed to the Google
>>> Groups "Neo4j" group.
>>> To unsubscribe from this group, send email to
>>> [email protected].
>>> For more options, visit https://groups.google.com/groups/opt_out.
>>>
>>>
>>>
>>>
>>>
--
You received this message because you are subscribed to the Google Groups
"Neo4j" group.
To unsubscribe from this group and stop receiving emails from it, send an email
to [email protected].
For more options, visit https://groups.google.com/groups/opt_out.
{kind=link}
{kind=link}