keith-turner opened a new pull request #2330: URL: https://github.com/apache/accumulo/pull/2330
Currently Accumulo uses the total number of files in a tablet as the priority for compactions that run against a tablet. So for the following tablet compactions Tablet Name | Total files | Compacting files -|-|- A | 20 | 10 B | 22 | 3 The tablet B with 22 total files would have a higher priority than A and would compact first. The goal of the priority is to reduce the overall number of files per tablet. Running the compaction for A before B would better accomplish this goal because it will compact 10 files resulting in the tablet having 11 files after the compaction. The compaction for B will compact 3 files resulting in a total of 20 file after the compaction. However the current priority scheme chooses B before A. This PR changes a compactions priority from totalTabletFiles to totalTableFiles+numFilesCompaction. With this scheme the compaction for tablet A would have a priority of 30 and tablet B a priority of 25, resulting the compaction A running first. To see if this made a noticeable difference I updated [compaculation](https://github.com/keith-turner/compaculation) to use Accumulo's pluggable compaction planners and ran a test w/ the old and new prioritizations schemes. The simulation only had a single thread for executing compactions, so that compactions would be always be queued making the prioritization really matter. The following config was used for the compaction planner. ``` "[{'name':'large','type':'internal','numThreads':1}]" ``` Below is a plot of the test running over 3 simulated days, adding 4 files to 4 random tablets every second. There were 100 simulated tablets. The plot shows the average files per tablet over time. The new prioritization scheme has a slightly lower files per tablet over time, which is good. 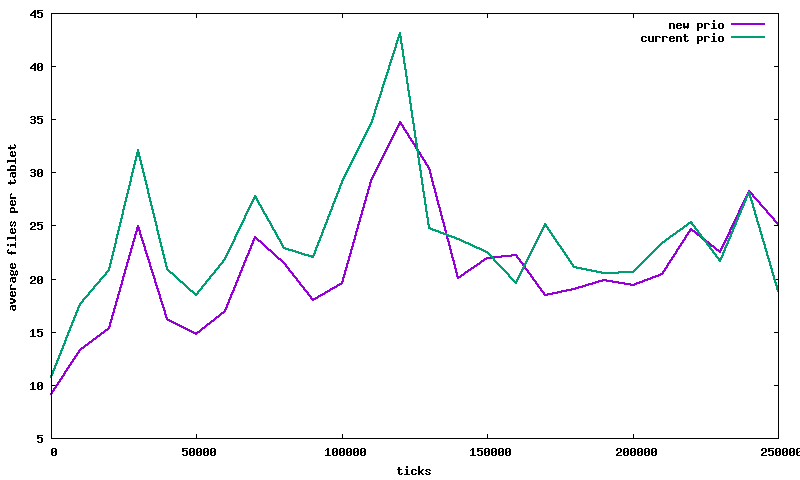 The simulation produces a line for every second, which is too much data. The following commands were used to average every 10,000 lines of the file into a single line. The summary files were plotted. ``` cat results-old-prio.txt | datamash -W -H -f bin:10000 1 | datamash -H -g 9 mean 4 > results-old-prio-summary.txt cat results-new-prio.txt | datamash -W -H -f bin:10000 1 | datamash -H -g 9 mean 4 > results-new-prio-summary.txt ``` The following are the averages of files per tablet over the entire lifetime of the two test. The new priority scheme has a slightly lower average for the entire test at 21.15. ``` $ cat results-old-prio.txt | datamash -H -W mean 4 mean(fsumAvg) 23.754240592279 $ cat results-new-prio.txt | datamash -H -W mean 4 mean(fsumAvg) 21.1524313084 ``` This a very small improvement, that would only matter when lots of compaction work is constantly queued. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}