skrawcz commented on code in PR #1532: URL: https://github.com/apache/hamilton/pull/1532#discussion_r3035105394
########## examples/LLM_Workflows/neo4j_graph_rag/data/README.md: ########## Review Comment: apache2 header plz ########## examples/LLM_Workflows/neo4j_graph_rag/.gitignore: ########## @@ -0,0 +1,27 @@ +# Environment Review Comment: apache2 header plz ########## examples/LLM_Workflows/neo4j_graph_rag/requirements.txt: ########## @@ -0,0 +1,10 @@ +sf-hamilton>=1.73.0 Review Comment: apache2 header plz ########## examples/LLM_Workflows/neo4j_graph_rag/README.md: ########## @@ -0,0 +1,205 @@ +<!-- +Licensed to the Apache Software Foundation (ASF) under one +or more contributor license agreements. See the NOTICE file +distributed with this work for additional information +regarding copyright ownership. The ASF licenses this file +to you under the Apache License, Version 2.0 (the +"License"); you may not use this file except in compliance +with the License. You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, +software distributed under the License is distributed on an +"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY +KIND, either express or implied. See the License for the +specific language governing permissions and limitations +under the License. +--> + +# Neo4j GraphRAG — TMDB Movies + +A full GraphRAG pipeline over a movie knowledge graph stored in Neo4j, +built entirely with Apache Hamilton. Ingestion, embedding, and retrieval +are each expressed as first-class Hamilton DAGs — dependencies declared +through function signatures, execution graph built automatically. + +## Hamilton DAG visualisations + +Run `--visualise` on any mode to regenerate these from source without +executing the pipeline. + +### Ingestion DAG + +```bash +python run.py --mode ingest --visualise +``` + +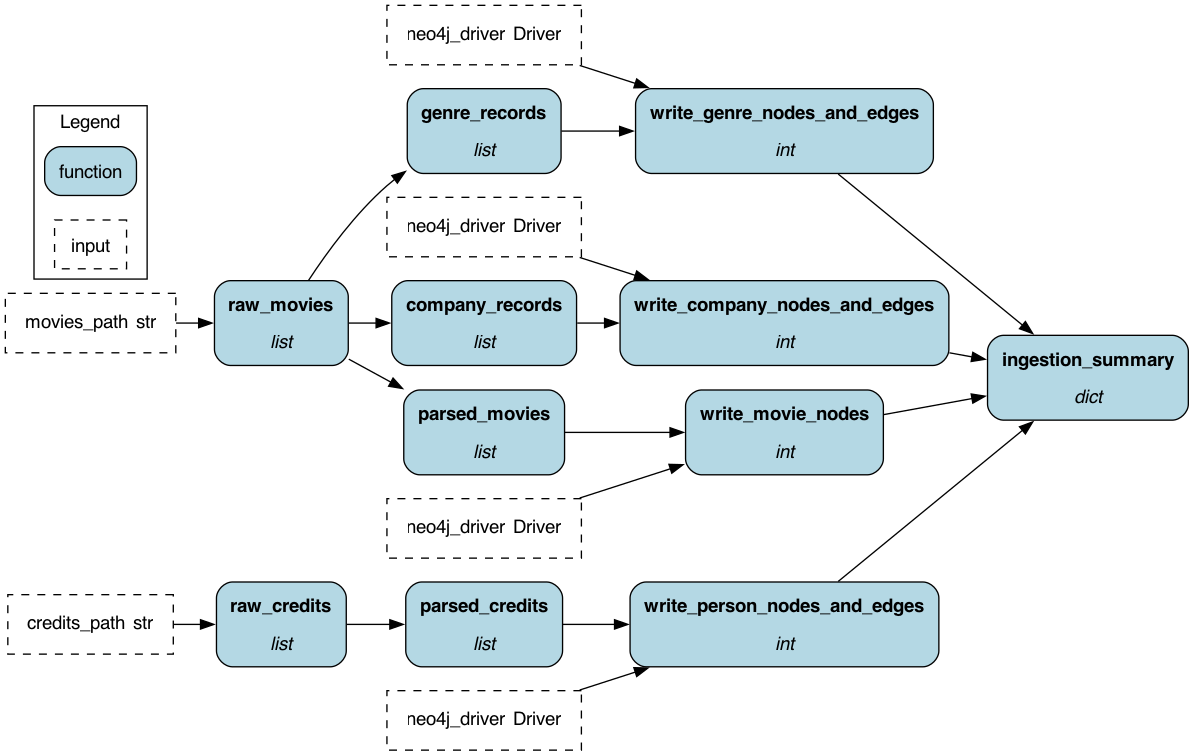 + +Raw TMDB JSON flows through parsing nodes into batched Neo4j writes. +Hamilton automatically parallelises the four independent branches +(movies, genres, companies, person edges) from the shared `raw_movies` +and `raw_credits` inputs. + +--- + +### Embedding DAG + +```bash +python run.py --mode embed --visualise +``` + +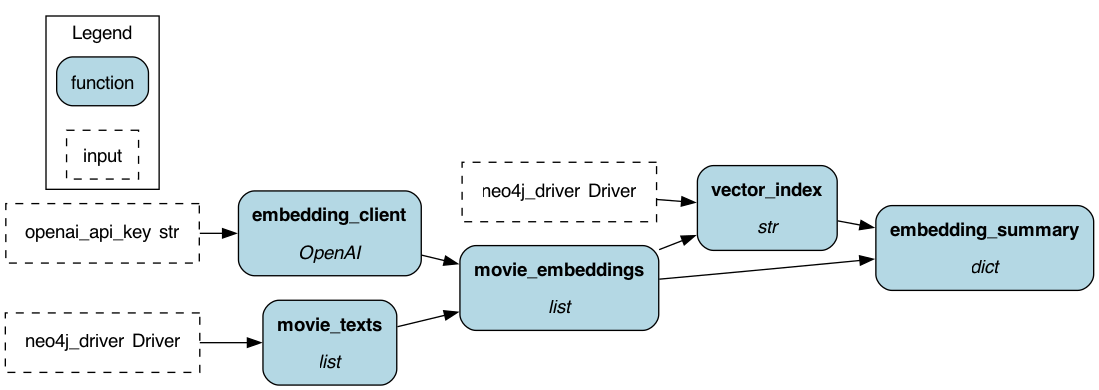 Review Comment: same here ########## examples/LLM_Workflows/neo4j_graph_rag/README.md: ########## @@ -0,0 +1,205 @@ +<!-- +Licensed to the Apache Software Foundation (ASF) under one +or more contributor license agreements. See the NOTICE file +distributed with this work for additional information +regarding copyright ownership. The ASF licenses this file +to you under the Apache License, Version 2.0 (the +"License"); you may not use this file except in compliance +with the License. You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, +software distributed under the License is distributed on an +"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY +KIND, either express or implied. See the License for the +specific language governing permissions and limitations +under the License. +--> + +# Neo4j GraphRAG — TMDB Movies + +A full GraphRAG pipeline over a movie knowledge graph stored in Neo4j, +built entirely with Apache Hamilton. Ingestion, embedding, and retrieval +are each expressed as first-class Hamilton DAGs — dependencies declared +through function signatures, execution graph built automatically. + +## Hamilton DAG visualisations + +Run `--visualise` on any mode to regenerate these from source without +executing the pipeline. + +### Ingestion DAG + +```bash +python run.py --mode ingest --visualise +``` + + + +Raw TMDB JSON flows through parsing nodes into batched Neo4j writes. +Hamilton automatically parallelises the four independent branches +(movies, genres, companies, person edges) from the shared `raw_movies` +and `raw_credits` inputs. + +--- + +### Embedding DAG + +```bash +python run.py --mode embed --visualise +``` + + + +Movie texts are fetched from Neo4j, batched through the OpenAI embeddings +API, written back to Movie nodes, and a cosine vector index is created. + +--- + +### Retrieval + Generation DAG + +```bash +python run.py --mode query --visualise +``` + +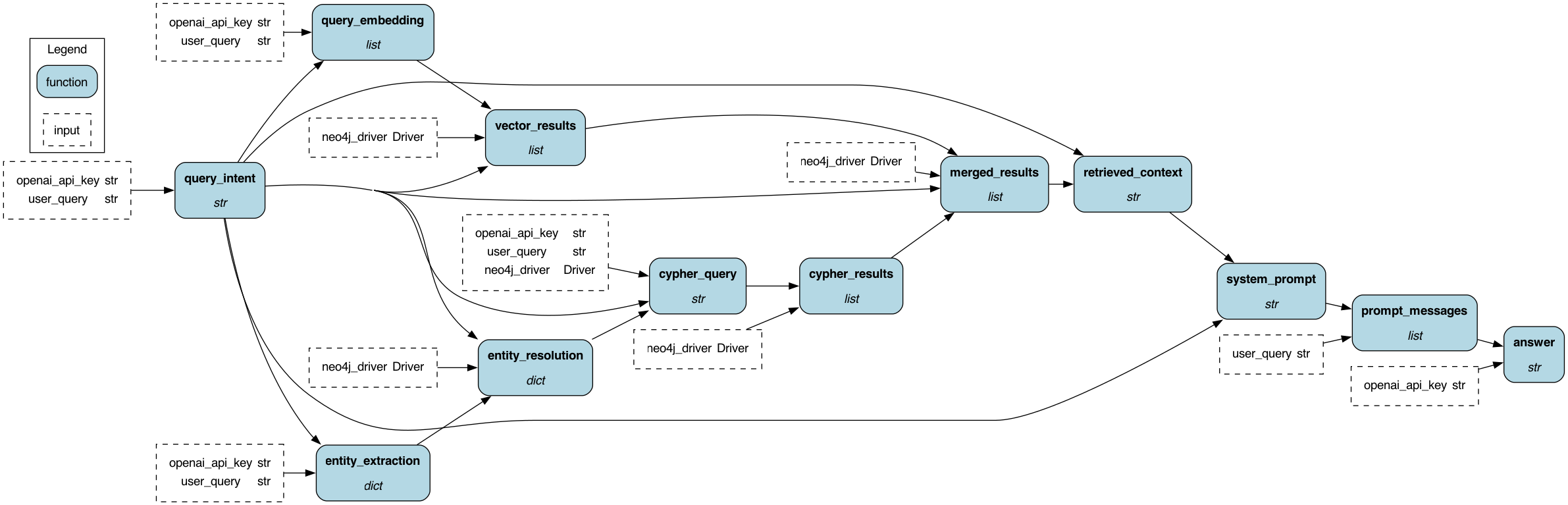 + +The full 13-node RAG pipeline. Hamilton wires all dependencies from +function signatures — no manual orchestration: + +``` +user_query + openai_api_key + neo4j_driver + -> query_intent classify into VECTOR / CYPHER / AGGREGATE / HYBRID + -> entity_extraction extract persons, movies, genres, companies, filters + -> entity_resolution fuzzy-match each entity against the live graph + -> query_embedding embed query (VECTOR / HYBRID only) + -> vector_results cosine similarity search (VECTOR / HYBRID only) + -> cypher_query LLM generates Cypher from resolved entities + -> cypher_results execute Cypher against Neo4j + -> merged_results combine both retrieval paths + -> retrieved_context format as numbered plain-text records + -> system_prompt inject context into LLM system prompt + -> prompt_messages assemble message list + -> answer gpt-4o generates final answer +``` + +## What it demonstrates + +**Ingestion DAG** (`ingest_module.py`) +Loads TMDB JSON, parses entities and relationships, writes to Neo4j via +batched Cypher `MERGE`. + +**Embedding DAG** (`embed_module.py`) +Computes OpenAI `text-embedding-3-small` embeddings over title + overview, +writes vectors to Movie nodes, creates a Neo4j cosine vector index. + +**Retrieval DAG** (`retrieval_module.py`) +Classifies each query into one of four strategies, resolves named entities +against the graph to get canonical names, then executes retrieval: + +| Strategy | When used | How it retrieves | +|-------------|----------------------------------|-----------------------------------------------| +| `VECTOR` | Thematic / semantic queries | Cosine vector search over Movie embeddings | +| `CYPHER` | Relational / factual queries | LLM-generated Cypher with resolved entities | +| `AGGREGATE` | Counting / ranking queries | Aggregation Cypher with popularity guard | +| `HYBRID` | Filtered + semantic queries | CYPHER + VECTOR, results merged | + +The semantic entity resolution layer looks up every extracted entity in +Neo4j before generating Cypher, so "Warner Bros movies" always resolves +to the canonical `"Warner Bros."` name in the graph. + +**Generation DAG** (`generation_module.py`) +Formats retrieved records into a grounded system prompt and calls gpt-4o. + +## Knowledge graph schema + +``` +(:Movie {id, title, release_date, overview, popularity, vote_average}) +(:Person {id, name}) +(:Genre {name}) +(:ProductionCompany {id, name}) + +(:Person)-[:ACTED_IN {order, character}]->(:Movie) +(:Person)-[:DIRECTED]->(:Movie) +(:Movie)-[:IN_GENRE]->(:Genre) +(:Movie)-[:PRODUCED_BY]->(:ProductionCompany) +``` + +Dataset: 4,803 movies · 56,603 persons · 106,257 ACTED_IN · 5,166 DIRECTED · 20 genres · 5,047 companies + +## Prerequisites + +- Docker +- Python 3.10+ +- OpenAI API key (`gpt-4o` access) +- TMDB dataset (see `data/README.md`) + +## Setup + +### 1. Start Neo4j + +```bash +docker compose up -d +``` + +Neo4j browser: http://localhost:7474 (user: `neo4j`, password: `password`) + +### 2. Install dependencies + +```bash +python -m venv venv +source venv/bin/activate +pip install -r requirements.txt +``` + +### 3. Configure environment + +```bash +cp .env.example .env +# edit .env — add your OPENAI_API_KEY +``` + +### 4. Download the dataset + +Follow `data/README.md` to download and convert the TMDB dataset. + +## Running + +```bash +# Step 1 — load graph (takes ~5 seconds) +python run.py --mode ingest + +# Step 2 — compute and store embeddings (takes ~2 minutes) +python run.py --mode embed + +# Step 3 — query +python run.py --mode query --question "Who directed Inception?" +python run.py --mode query --question "Which movies did Tom Hanks and Robin Wright appear in together?" +python run.py --mode query --question "Which production company made the most action movies?" +python run.py --mode query --question "Recommend movies similar to Inception" +python run.py --mode query --question "Find me war films rated above 7.5" +python run.py --mode query --question "Which actors appeared in both a Christopher Nolan and a Steven Spielberg film?" +``` + +## Project structure + +``` +neo4j_graph_rag/ +├── docker-compose.yml Neo4j 5 + APOC +├── requirements.txt +├── .env.example Review Comment: can you add this file - I don't see it. ########## examples/LLM_Workflows/neo4j_graph_rag/README.md: ########## @@ -0,0 +1,205 @@ +<!-- +Licensed to the Apache Software Foundation (ASF) under one +or more contributor license agreements. See the NOTICE file +distributed with this work for additional information +regarding copyright ownership. The ASF licenses this file +to you under the Apache License, Version 2.0 (the +"License"); you may not use this file except in compliance +with the License. You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, +software distributed under the License is distributed on an +"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY +KIND, either express or implied. See the License for the +specific language governing permissions and limitations +under the License. +--> + +# Neo4j GraphRAG — TMDB Movies + +A full GraphRAG pipeline over a movie knowledge graph stored in Neo4j, +built entirely with Apache Hamilton. Ingestion, embedding, and retrieval +are each expressed as first-class Hamilton DAGs — dependencies declared +through function signatures, execution graph built automatically. + +## Hamilton DAG visualisations + +Run `--visualise` on any mode to regenerate these from source without +executing the pipeline. + +### Ingestion DAG + +```bash +python run.py --mode ingest --visualise +``` + + + +Raw TMDB JSON flows through parsing nodes into batched Neo4j writes. +Hamilton automatically parallelises the four independent branches +(movies, genres, companies, person edges) from the shared `raw_movies` +and `raw_credits` inputs. + +--- + +### Embedding DAG + +```bash +python run.py --mode embed --visualise +``` + + + +Movie texts are fetched from Neo4j, batched through the OpenAI embeddings +API, written back to Movie nodes, and a cosine vector index is created. + +--- + +### Retrieval + Generation DAG + +```bash +python run.py --mode query --visualise +``` + + Review Comment: ditto ########## examples/LLM_Workflows/neo4j_graph_rag/requirements.txt: ########## @@ -0,0 +1,10 @@ +sf-hamilton>=1.73.0 +neo4j>=5.18.0 +llama-index>=0.10.0 +llama-index-graph-stores-neo4j>=0.2.0 +llama-index-llms-openai>=0.1.0 +llama-index-embeddings-openai>=0.1.0 Review Comment: remove these, right? ########## examples/LLM_Workflows/neo4j_graph_rag/README.md: ########## @@ -0,0 +1,205 @@ +<!-- +Licensed to the Apache Software Foundation (ASF) under one +or more contributor license agreements. See the NOTICE file +distributed with this work for additional information +regarding copyright ownership. The ASF licenses this file +to you under the Apache License, Version 2.0 (the +"License"); you may not use this file except in compliance +with the License. You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + +Unless required by applicable law or agreed to in writing, +software distributed under the License is distributed on an +"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY +KIND, either express or implied. See the License for the +specific language governing permissions and limitations +under the License. +--> + +# Neo4j GraphRAG — TMDB Movies + +A full GraphRAG pipeline over a movie knowledge graph stored in Neo4j, +built entirely with Apache Hamilton. Ingestion, embedding, and retrieval +are each expressed as first-class Hamilton DAGs — dependencies declared +through function signatures, execution graph built automatically. + +## Hamilton DAG visualisations + +Run `--visualise` on any mode to regenerate these from source without +executing the pipeline. + +### Ingestion DAG + +```bash +python run.py --mode ingest --visualise +``` + + Review Comment: should point to this repo -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}
{kind=link}