chibenwa opened a new pull request #464: URL: https://github.com/apache/james-project/pull/464
After ~1 month of background work I finally get a decent proof of concept out of this... Cf https://issues.apache.org/jira/browse/JAMES-3576 ## The facts Here is our message structure: ``` cqlsh:apache_james> DESCRIBE TABLE imapuidtable ; CREATE TABLE apache_james.imapuidtable ( messageid timeuuid, mailboxid timeuuid, uid bigint, flaganswered boolean, flagdeleted boolean, flagdraft boolean, flagflagged boolean, flagrecent boolean, flagseen boolean, flaguser boolean, modseq bigint, userflags set<text>, PRIMARY KEY (messageid, mailboxid, uid) ) WITH comment = 'Holds mailbox and flags for each message, lookup by message ID'; cqlsh:apache_james> DESCRIBE TABLE messageidtable ; CREATE TABLE apache_james.messageidtable ( mailboxid timeuuid, uid bigint, flaganswered boolean, flagdeleted boolean, flagdraft boolean, flagflagged boolean, flagrecent boolean, flagseen boolean, flaguser boolean, messageid timeuuid, modseq bigint, userflags set<text>, PRIMARY KEY (mailboxid, uid) ) WITH comment = 'Holds mailbox and flags for each message, lookup by mailbox ID + UID'; cqlsh:apache_james> DESCRIBE TABLE messagev3 ; CREATE TABLE apache_james.messagev3 ( messageid timeuuid PRIMARY KEY, bodycontent text, bodyoctets bigint, bodystartoctet int, attachments list<frozen<attachments>>, // and also message properties ) WITH comment = 'Holds message metadata, independently of any mailboxes. Content of messages is stored in `blobs` and `blobparts` tables. Optimizes property storage compared to V2.'; ``` Some very common patterns is to access messages headers. 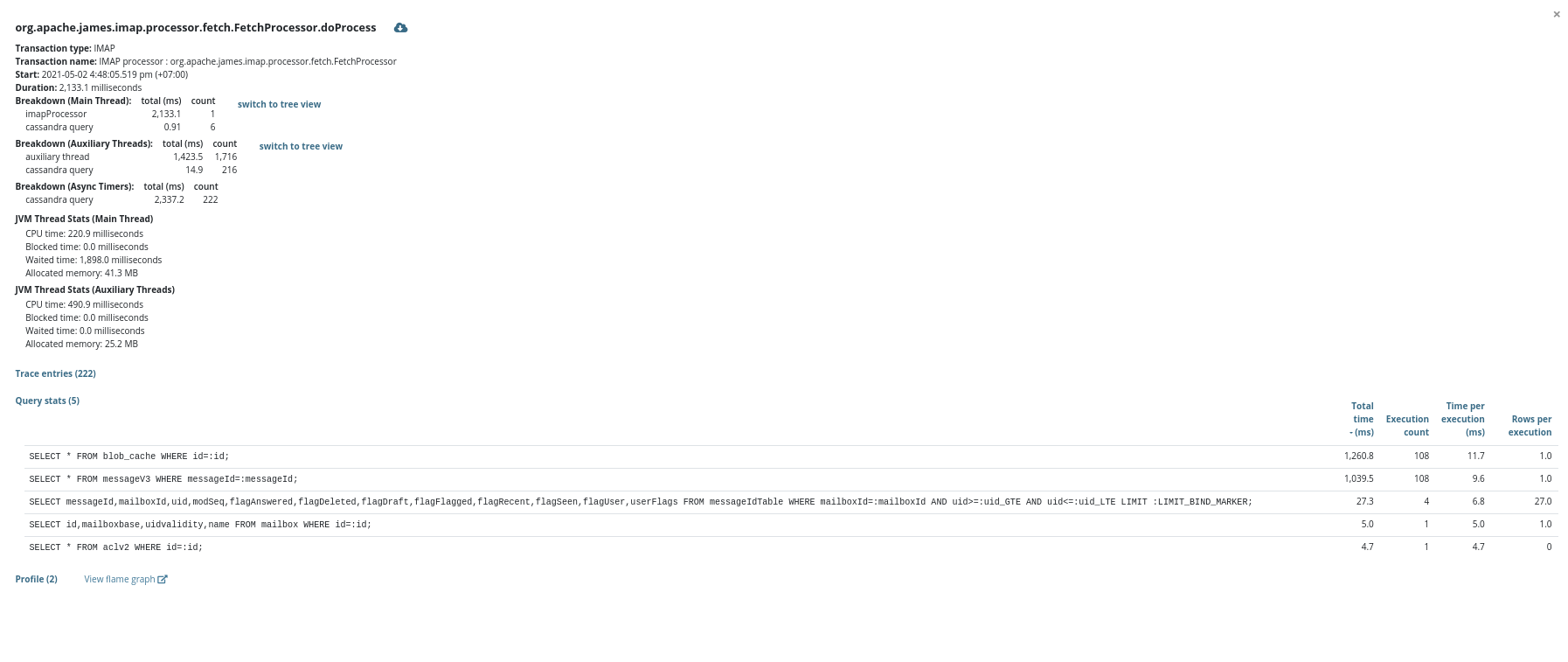 - this shows me opening my IMAP mailbox after a long weekend. We can see that my MUA lists headers of the 108 messages received in the time laps. We can see that, in order to retrieve the storage informations, the messagev3 table needs to be accessed for each message, generating a huge count of PRIMARY KEY reads that are not strictly necessary, and reading messageV3 yields second place in query time occupation. 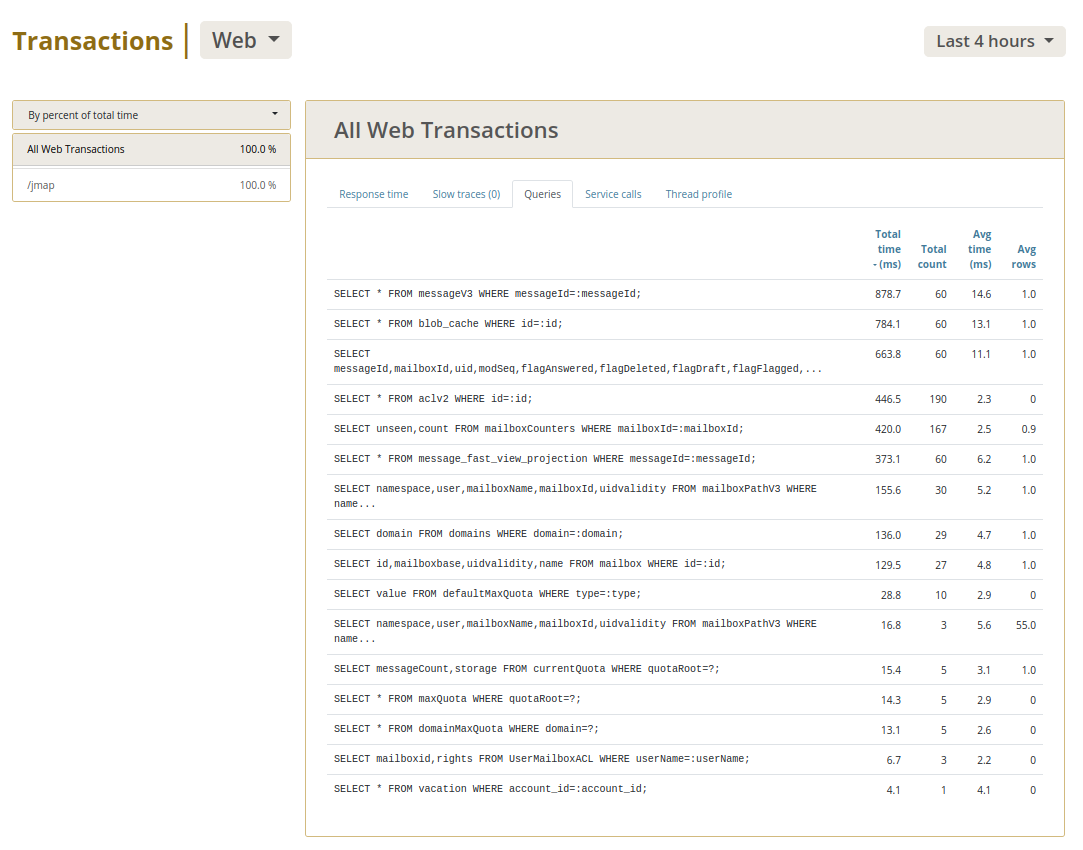 - Similar things happens on top of JMAP. This shows 2 webmail email list loads. Same things: For each message entry, we need to query messagev3 to retrieve storage informations and being able to retireve headers. Here messagev3 reads yields first place, before the message metadata reads, before the header reads. ## The bit of Cassandra philosophy we might have missed... https://www.datastax.com/blog/basic-rules-cassandra-data-modeling ``` # Non-Goals ## Minimize the Number of Writes Writes in Cassandra aren't free, but they're awfully cheap. Cassandra is optimized for high write throughput, and almost all writes are equally efficient [1]. ## Minimize Data Duplication Denormalization and duplication of data is a fact of life with Cassandra. Don't be afraid of it. [...] In order to get the most efficient reads, you often need to duplicate data. # Basic goals [...] ## Rule 2: Minimize the Number of Partitions Read [...] Furthermore, even on a single node, it's more expensive to read from multiple partitions than from a single one due to the way rows are stored. ``` https://thelastpickle.com/blog/2017/03/16/compaction-nuance.html ``` An incorrect data model can turn a single query into hundreds of queries, resulting in increased latency, decreased throughput, and missed SLAs. ``` (This one is of an article about compaction but my feeling is that it is very relevant to the situation I describe, so I could not refrain from quoting it...) ## The new data-model I propose to do the following: ``` cqlsh:apache_james> ALTER TABLE messageIdTable ADD internalDate timestamp ; cqlsh:apache_james> ALTER TABLE messageIdTable ADD bodyStartOctet int ; cqlsh:apache_james> ALTER TABLE messageIdTable ADD fullContentOctets bigint ; cqlsh:apache_james> ALTER TABLE messageIdTable ADD headerContent text ; cqlsh:apache_james> ALTER TABLE imapUidTable ADD internalDate timestamp ; cqlsh:apache_james> ALTER TABLE imapUidTable ADD bodyStartOctet int ; cqlsh:apache_james> ALTER TABLE imapUidTable ADD fullContentOctets bigint ; cqlsh:apache_james> ALTER TABLE imapUidTable ADD headerContent text ; ``` That way we can easily resolve METADATA and HEADERS FetchGroups against both messageIdTable and imapUidTable, effectively limiting messageV3 reads to the FULL body reads. ## Expectations This will effectively reduce the Cassandra query load for both JMAP and IMAP, effectively speeding up James and allowing us to scale to larger workloads given the exact same infrastructure. A boost ranging from 25% to 33% is expected for both IMAP, JMAP and POP3 workloads. ## Migration strategy - 1. The admin ALTER the tables - 2. The admin deploys the new version of James. New written data is then fully denormalized... - 3. But old written data still needs reads to messagev3 to be served (if expected data is not in messageIdTable or in imapUidTable we know we need to read it from messagev3 table). - 4. We propose a migration task that effectively look up messagev3 to populate newly created rows for messageIdTable and imapUidTable - this way an admin can ensure to fully benefit from the enhancement given previously existing data. I think the classical migration strategy is not a good fit for this one as: - fallback mechanisms incurs performance degradations (double the amount of reads in the transition period) and message metadata query speed is critical. With the proposed strategy during the transition period at worst the previous behavior is applied. - Creating and deleting tables is messy, when simple in-place modification do not generate data model gardbage. - We can add a startup-check to ensure the rows are correctly here (and abort startup if not) ## Early results The following tests were conducted with a single server bundling all the James components, at quite low scale. Especially the latencies (unpredictable) of the object store screws up the `fetch line` yet massive enhancements are observed for the FetchAll line. Before: 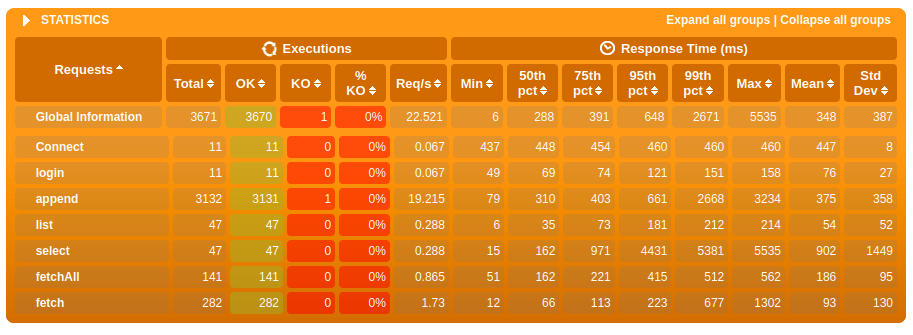 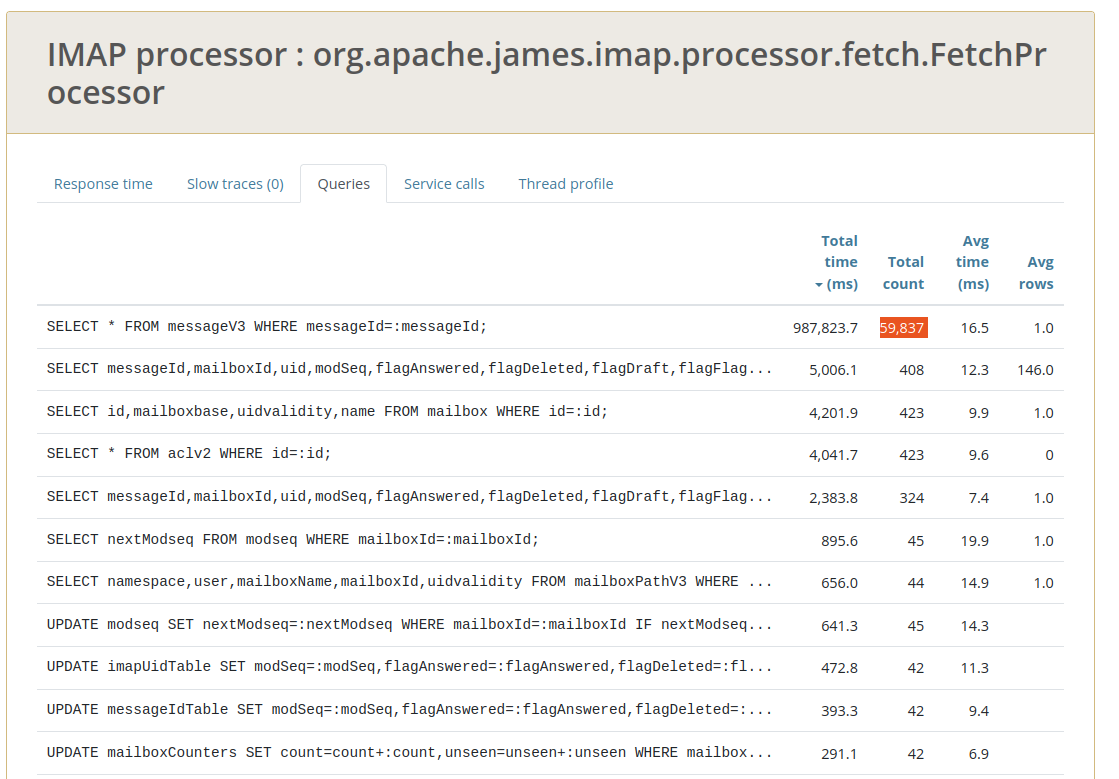 After: 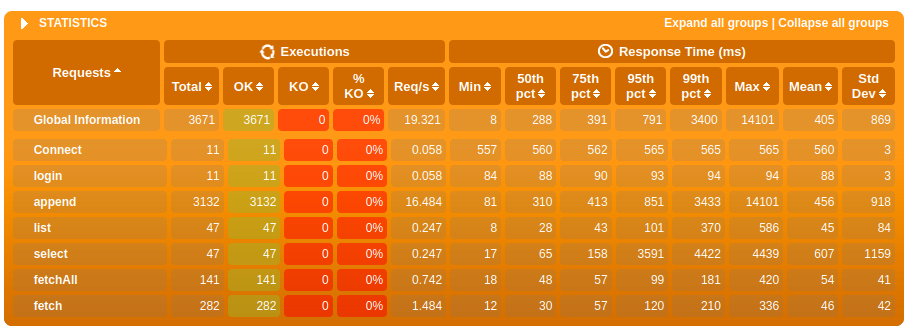 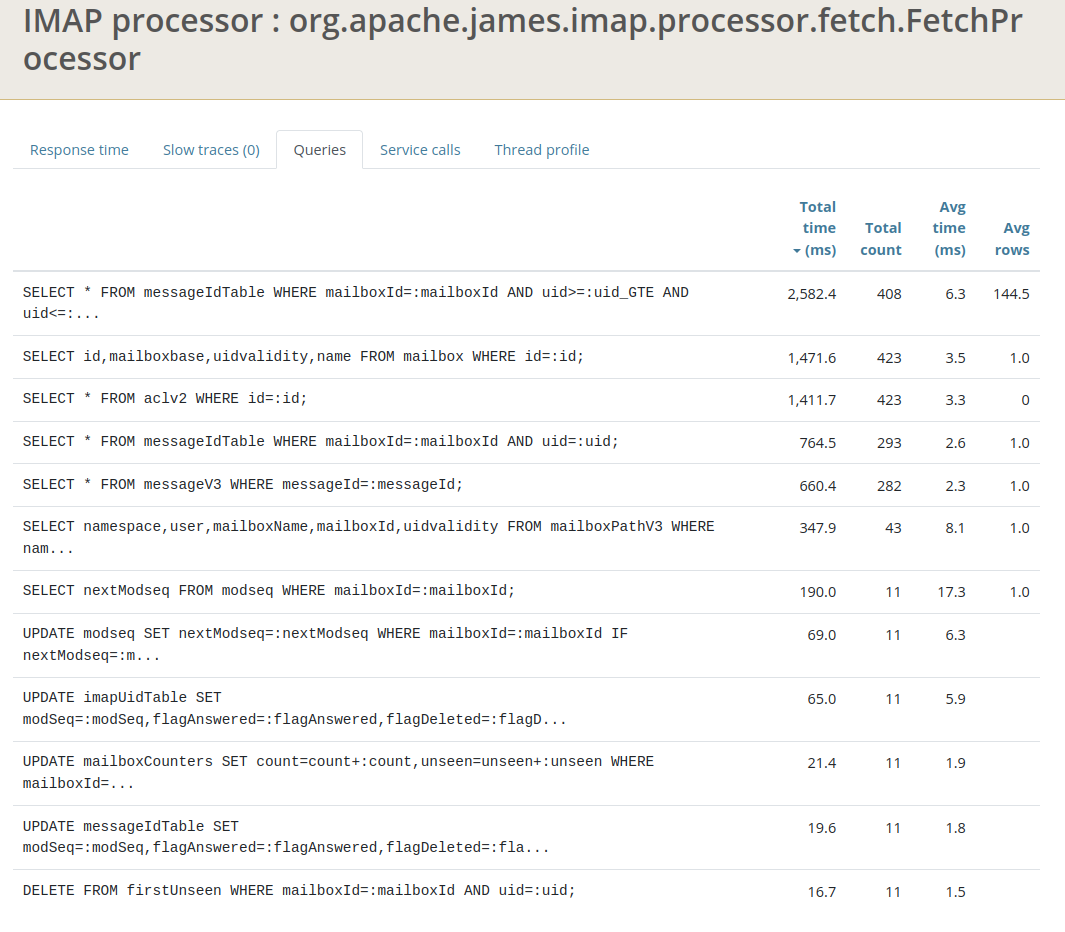 I want to conduct tests on a James cluster regarding JMAP performances before moving forward on this. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org --------------------------------------------------------------------- To unsubscribe, e-mail: notifications-unsubscr...@james.apache.org For additional commands, e-mail: notifications-h...@james.apache.org
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}