mbien opened a new pull request, #4095:
URL: https://github.com/apache/netbeans/pull/4095
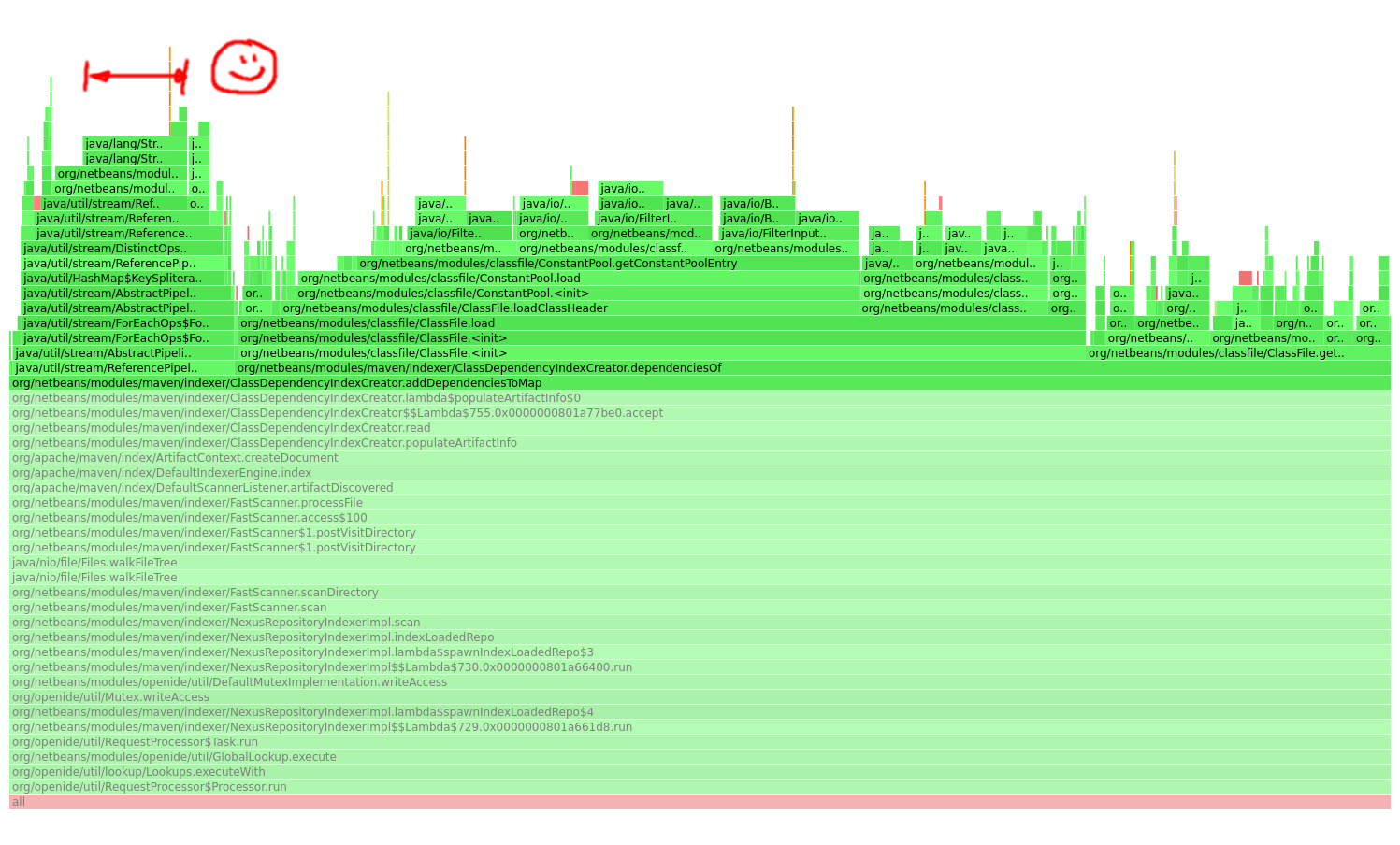
flamegraphs showed that ClassDependencyIndexCreator.addDependencyToMap
had some potential for optimizations.
- use stream instead of HashSet which gives a very small perf improvement
but also slightly more readable code IMO
- use simple startsWith() loop for prefix filtering instead of
stateful impl (MatchWords), the JVM is likely very good at
optimizing/vectorizing String intrinsics
benchmark showed ~20% speedup
full indexing takes on my system and with my current local maven repo ~53s
(down from ~66s)
@timboudreau what is your opinion on this? You wrote most of the original
optimizations (including the `MatchWords` class). I can't see you in the
reviewer list for some reason.
sidenote:
I did also write a parallel version using an `ExecutorService` which could
reduce it further to ~38s, but it made the code slightly more complex which is
probably not worth the trouble. Parallelizing on a higher level (outside of
`ClassDependencyIndexCreator`) might give better results (better scaling) since
this is only a small slice of the task.
flamegraphs:

--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: notifications-unsubscr...@netbeans.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
---------------------------------------------------------------------
To unsubscribe, e-mail: notifications-unsubscr...@netbeans.apache.org
For additional commands, e-mail: notifications-h...@netbeans.apache.org
For further information about the NetBeans mailing lists, visit:
https://cwiki.apache.org/confluence/display/NETBEANS/Mailing+lists
{kind=link}
{kind=link}