This is an automated email from the ASF dual-hosted git repository.
zhangliang pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/shardingsphere.git
The following commit(s) were added to refs/heads/master by this push:
new a42fd52982f modify the content of overview (#20563)
a42fd52982f is described below
commit a42fd52982f799afea9e6d8f6e62c75d462a9d64
Author: Mike0601 <[email protected]>
AuthorDate: Fri Aug 26 17:38:58 2022 +0800
modify the content of overview (#20563)
---
docs/document/content/overview/design.cn.md | 6 ++++--
docs/document/content/overview/design.en.md | 6 ++++--
docs/document/content/overview/intro.cn.md | 18 +++++++++---------
docs/document/content/overview/intro.en.md | 16 ++++++++--------
docs/document/static/img/design_cn.png | Bin 0 -> 267068 bytes
docs/document/static/img/design_en.png | Bin 0 -> 285763 bytes
.../img/{overview.cn_v2.png => overview_cn.png} | Bin
.../static/img/{overview.en.png => overview_en.png} | Bin
8 files changed, 25 insertions(+), 21 deletions(-)
diff --git a/docs/document/content/overview/design.cn.md
b/docs/document/content/overview/design.cn.md
index 5db77be4bee..5bec4b4e198 100644
--- a/docs/document/content/overview/design.cn.md
+++ b/docs/document/content/overview/design.cn.md
@@ -7,7 +7,7 @@ chapter = true
ShardingSphere 采用 Database Plus 设计哲学,该理念致力于构建数据库上层的标准和生态,在生态中补充数据库所缺失的能力。
-
+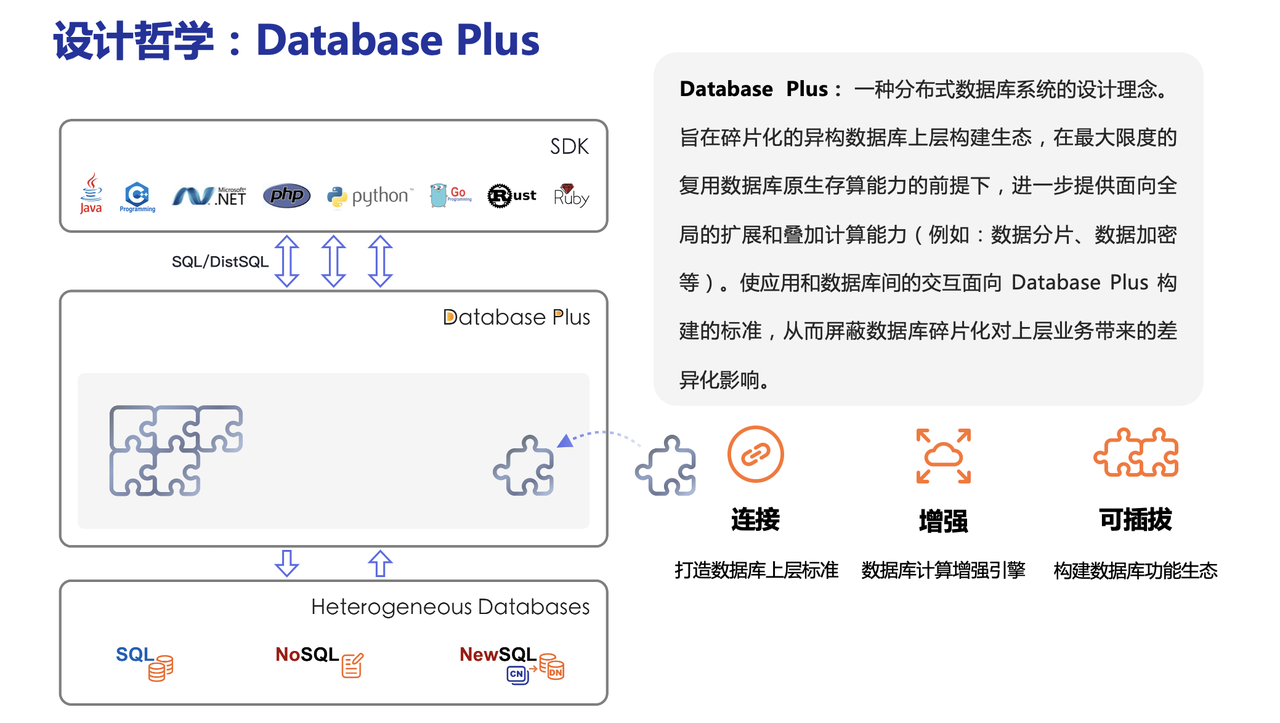
## 连接:打造数据库上层标准
@@ -15,10 +15,12 @@ ShardingSphere 采用 Database Plus 设计哲学,该理念致力于构建数
## 增强:数据库计算增强引擎
-获取数据库的访问流量,并提供流量重定向(数据分片、读写分离、影子库)、流量变形(数据加密、数据脱敏)、流量鉴权(安全、审计、权限)、流量治理(熔断、限流)以及流量分析(服务质量分析、可观察性)等透明化增量功能。
+在原生数据库基础能力之上,提供分布式及流量增强方面的能力。前者可突破底层数据库在计算与存储上的瓶颈,后者通过对流量的变形、重定向、治理、鉴权及分析能力提供更为丰富的数据应用增强能力。
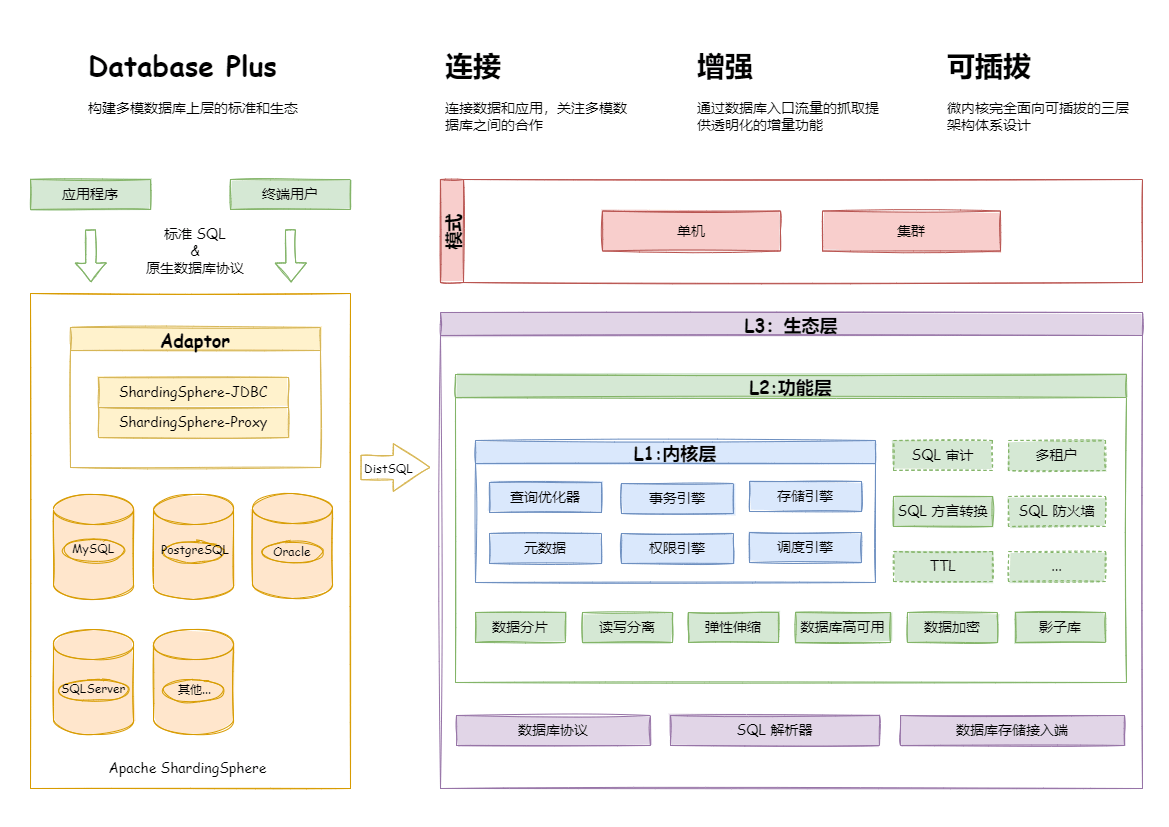
## 可插拔:构建数据库功能生态
+
+
Apache ShardingSphere 的可插拔架构划分为 3 层,它们是:L1 内核层、L2 功能层、L3 生态层。
### L1 内核层
diff --git a/docs/document/content/overview/design.en.md
b/docs/document/content/overview/design.en.md
index a79b28c1cee..4160c1596d7 100644
--- a/docs/document/content/overview/design.en.md
+++ b/docs/document/content/overview/design.en.md
@@ -7,7 +7,7 @@ chapter = true
ShardingSphere adopts the database plus design philosophy, which is committed
to building the standards and ecology of the upper layer of the database and
supplementing the missing capabilities of the database in the ecology.
-
+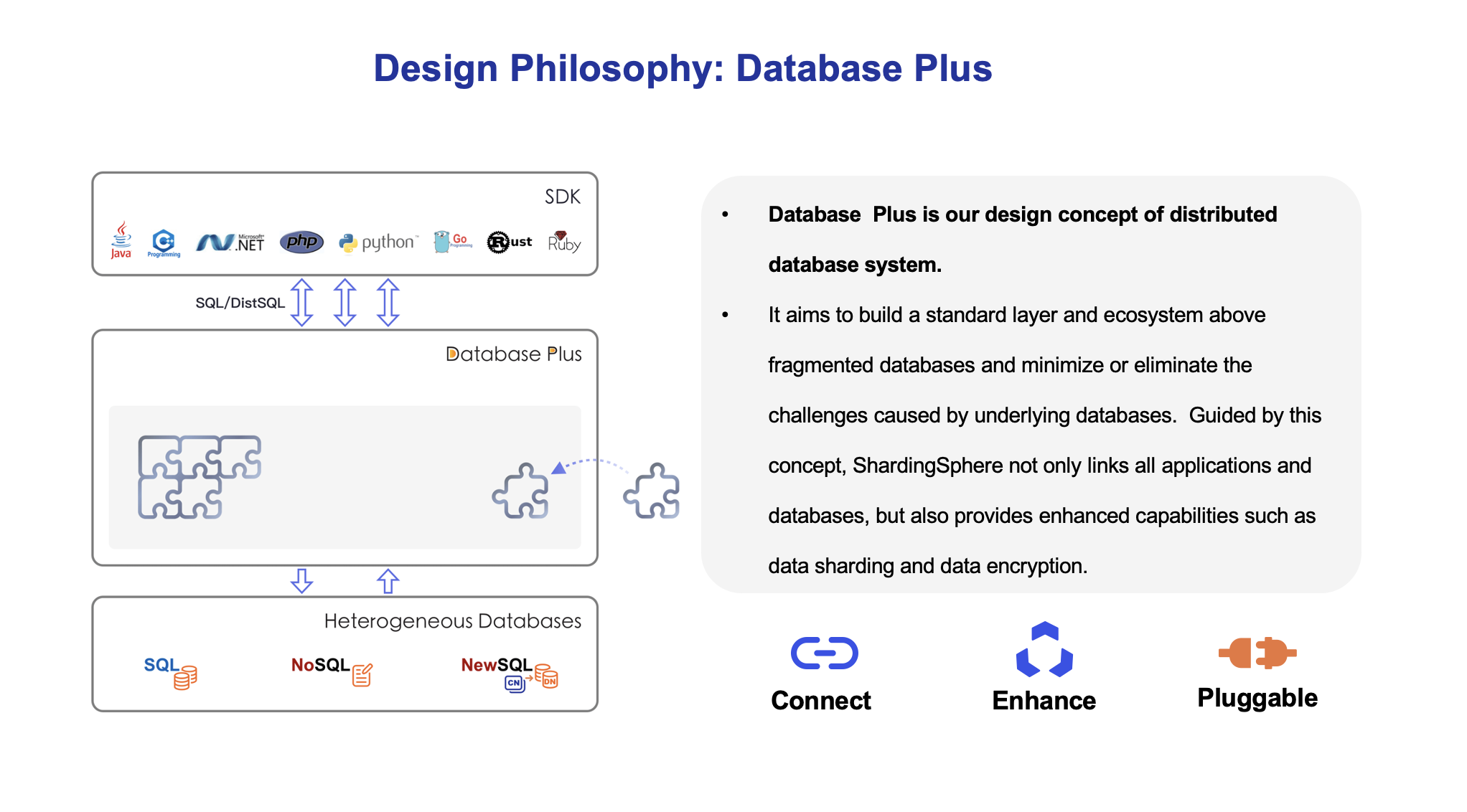
## Connect: Create database upper level standard
@@ -15,10 +15,12 @@ ShardingSphere adopts the database plus design philosophy,
which is committed to
## Enhance: Database computing enhancement engine
-Capture database access entry to provide additional features transparently,
such as: redirect (sharding, readwrite-splitting and shadow), transform (data
encrypt and mask), authentication (security, audit and authority), governance
(circuit breaker and access limitation and analyze, QoS and observability).
+It can further provide distributed capabilities and traffic enhancement
functions based on native database capabilities. The former can break through
the bottleneck of the underlying database in computing and storage, while the
latter provides more diversified data application enhancement capabilities
through traffic deformation, redirection, governance, authentication, and
analysis.
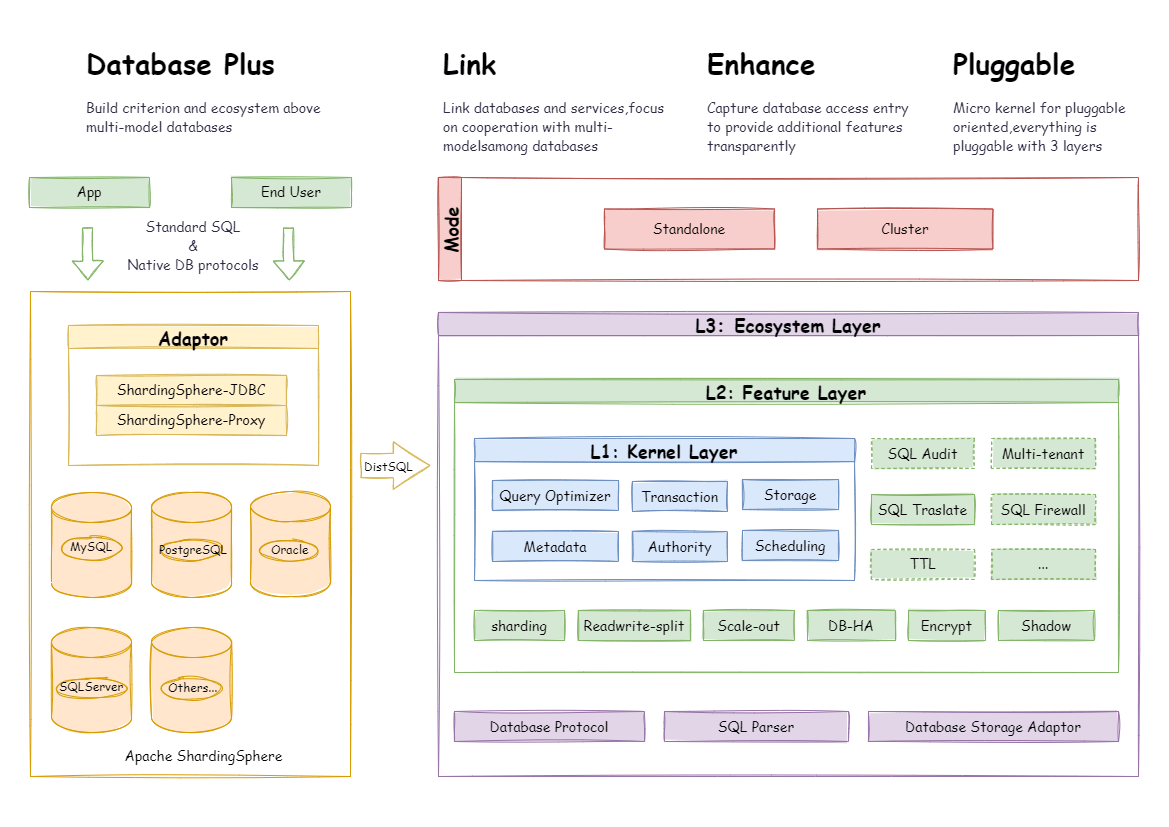
## Pluggable: Building database function ecology
+
+
The pluggable architecture of Apache ShardingSphere is composed of three
layers - L1 Kernel Layer, L2 Feature Layer and L3 Ecosystem Layer.
### L1 Kernel Layer
diff --git a/docs/document/content/overview/intro.cn.md
b/docs/document/content/overview/intro.cn.md
index 8a607fd2bd0..7e9c363f85a 100644
--- a/docs/document/content/overview/intro.cn.md
+++ b/docs/document/content/overview/intro.cn.md
@@ -32,15 +32,15 @@ ShardingSphere-Proxy 定位为透明化的数据库代理端,通过实现数
## 产品功能
| 特性 | 定义 |
-| --------- | ---- |
-| 数据分片 | 数据分片是一种数据库分布式技术,ShardingSphere
可将一个大的数据库(或表)以某种维度切分成多个小的数据库(或表),构建出可有效的应对海量数据存储及更密集请求的分布式数据库解决方案。 |
-| 分布式事务 | ShardingSphere 对外提供本地事务接口,通过 LOCAL,XA,BASE 三种模式提供了分布式事务的能力。 |
-| 读写分离 | 在读请求明显多于写请求的业务场景中,通过 ShardingSphere
读写分离技术可大幅度提升系统吞吐能力,即主库负责处理事务性的增删改请求,从库只负责处理查询请求。 |
-| 高可用 | ShardingSphere
自身提供计算节点,并通过数据库作为存储节点。它采用的高可用方案是利用数据库自身的高可用方案做存储节点高可用,并自动识别其变化。 |
-| 数据迁移 | ShardingSphere 为用户提供了基于数据全场景迁移能力,可应对业务数据量激增的场景。 |
-| 联邦查询 | ShardingSphere 联邦查询适合于跨越数据库之间的关联查询和子查询。 |
-| 数据加密 | ShardingSphere 根据业界对加密的需求及业务改造痛点,提供了一套完整、安全、透明化、低改造成本的数据加密整合解决方案。 |
-| 影子库 | 在全链路压测场景中,ShardingSphere
影子库用于存储压测数据,为复杂的全链路压测工作提供数据隔离支持,获得的测试结果能够准确地反应系统真实容量和性能水平。 |
+| --------- | ----- |
+| 数据分片 | 数据分片,是应对海量数据存储与计算的有效手段。ShardingSphere
提供基于底层数据库之上,可计算与存储水平扩展的分布式数据库解决方案。 |
+| 分布式事务 | 事务能力,是保障数据库完整、安全的关键技术,也是数据库的核心技术之一。ShardingSphere
提供在单机数据库之上的分布式事务能力,可实现跨底层数据源的数据安全。 |
+| 读写分离 | 读写分离,是应对高压力业务访问的手段之一。ShardingSphere
基于对SQL语义理解及底层数据库拓扑感知能力,提供灵活、安全的读写分离能力,且可实现读访问的负载均衡。 |
+| 高可用 | 高可用,是对数据存储计算平台的基本要求。ShardingSphere
基于无状态服务,提供高可用计算服务访问;同时可感知并利用底层数据库自身高可用实现整体的高可用能力。 |
+| 数据迁移 | 数据迁移,是打通数据生态的关键能力。SharingSphere 提供基于数据全场景的迁移能力,可应对业务数据量激增的场景。 |
+| 联邦查询 | 联邦查询,是面对复杂数据环境下利用数据的有效手段之一。ShardingSphere
提供跨数据源的复杂数据查询分析能力,简化并提升数据使用体验。 |
+| 数据加密 | 数据加密,是保证数据安全的基本手段。ShardingSphere 提供一套完整的、透明化、安全的、低改造成本的数据加密解决方案。 |
+| 影子库 | 在全链路压测场景下,ShardingSphere
通过影子库功能支持在复杂压测场景下数据隔离,压测获得测试结果可准确反应系统真实容量和性能水平。 |
## 产品优势
diff --git a/docs/document/content/overview/intro.en.md
b/docs/document/content/overview/intro.en.md
index 724c1818adc..4cc0c7e167a 100644
--- a/docs/document/content/overview/intro.en.md
+++ b/docs/document/content/overview/intro.en.md
@@ -34,14 +34,14 @@ ShardingSphere-Proxy is a transparent database proxy,
providing a database serve
| Feature | Definition |
| ----------------------- | ---------- |
-| Data Sharding | Data sharding is a distributed database
technology. ShardingSphere can split a large database (or table) into multiple
small databases (or tables), and create a distributed database solution that
can effectively cope with massive data storage and intensive requests. |
-| Distributed Transaction | ShardingSphere provides local transaction
interfaces and supports distributed transactions through LOCAL, XA, and BASE
modes. |
-| Read/write Splitting | In a scenario where the read requests greatly
outnumber write requests, ShardingSphere's read/write splitting feature can
significantly improve the system throughput. The primary database deals with
transactional addition, deletion, and modification requests while the secondary
database only deals with query requests. |
-| High Availability | ShardingSphere itself provides compute nodes and
serves as the storage node through databases. It leverages the database's HA
solutions to achieve high availability of the storage node, and automatically
identifies the changes. |
-| Data Migration | ShardingSphere provides full-scenario data
migration capability for users, which can cope with the surge of business data
volume. |
-| Federated Query | ShardingSphere federated query applies to
associated queries and sub-queries across databases. |
-| Data Encryption | Considering the industry's needs for encryption
and the pain points of business transformation, ShardingSphere provides a set
of integrated data encryption solutions that are complete, secure, transparent,
and with low transformation cost. |
-| Shadow Database | In the full-link stress testing scenario,
ShardingSphere shadow DB is used for storing stress testing data and providing
data isolation support for complex testing work. The obtained testing result
can accurately reflect the system's true capacity and performance. |
+| Data Sharding | Data sharding is an effective way to deal with
massive data storage and computing. ShardingSphere provides distributed
database solutions that can scale out computing and storage levels on top of
the underlying database. |
+| Distributed Transaction | Transactional capability is key to ensuring
database integrity and security and is also one of the databases' core
technologies. ShardingSphere provides distributed transaction capability on top
of a single database, which can achieve data security across underlying data
sources. |
+| Read/write Splitting | Read/write splitting can be used to cope with
business access with high stress. Based on its understanding of SQL semantics
and the topological awareness of the underlying database, ShardingSphere
provides flexible and secure read/write splitting capabilities and can achieve
load balancing for read access. |
+| High Availability | High availability is a basic requirement for a
data storage and computing platform. ShardingSphere provides access to
high-availability computing services based on stateless services. At the same
time, it can sense and use the underlying database's HA solution to achieve its
overall high availability. |
+| Data Migration | Data migration is the key to connecting data
ecosystems. ShardingSphere provides full-scenario data migration capability for
users, which can cope with the surge of business data volume. |
+| Federated Query | Federated queries are effective in utilizing data
in a complex data environment. ShardingSphere is capable of querying and
analyzing complex data across data sources, simplifying and improving the data
usage experience. |
+| Data Encryption | Data Encryption is a basic way to ensure data
security. ShardingSphere provides a set of data encryption solutions that are
complete, secure, transparent, and with low transformation costs. |
+| Shadow Database | In the full-link stress testing scenario,
ShardingSphere shadow DB is used for providing data isolation support for
complex testing work. The obtained testing result can accurately reflect the
system's true capacity and performance. |
## Advantages
diff --git a/docs/document/static/img/design_cn.png
b/docs/document/static/img/design_cn.png
new file mode 100644
index 00000000000..d4566054509
Binary files /dev/null and b/docs/document/static/img/design_cn.png differ
diff --git a/docs/document/static/img/design_en.png
b/docs/document/static/img/design_en.png
new file mode 100644
index 00000000000..c9e4b62194b
Binary files /dev/null and b/docs/document/static/img/design_en.png differ
diff --git a/docs/document/static/img/overview.cn_v2.png
b/docs/document/static/img/overview_cn.png
similarity index 100%
rename from docs/document/static/img/overview.cn_v2.png
rename to docs/document/static/img/overview_cn.png
diff --git a/docs/document/static/img/overview.en.png
b/docs/document/static/img/overview_en.png
similarity index 100%
rename from docs/document/static/img/overview.en.png
rename to docs/document/static/img/overview_en.png
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}