kimmking opened a new issue #4896: [DISCUSS]MetadataCenter Design 5.x URL: https://github.com/apache/incubator-shardingsphere/issues/4896 MetadataCenter Design5.x is a part of Orchestration 5.x Design(#4515). ## Metadata Center Design The purpose of this document is to illustrate the metadata center design of the Apache ShardingSphere governance module. [TOC] ### 1. Definition The word 'metadata' in this article is the metadata of the data source used by Sharding-JDBC / Sharding-Proxy. These metadata are the core data objects to ensure the correct operations of each component of ShardingSphere. Currently, they are scattered in each part of the system. They should be reorganized and managed in a unified manner using a new component such like 'metadata center', and coordinate changes when metadatas changes. ### 2. Types The current metadata object models are mainly defined in: > org.apache.shardingsphere.sql.parser.binder > > ├─column > │ ColumnMetaData.java > │ ColumnMetaDataLoader.java > ├─index > │ IndexMetaData.java > │ IndexMetaDataLoader.java > ├─schema > │ SchemaMetaData.java > │ SchemaMetaDataLoader.java > └─table > TableMetaData.java > TableMetaDataLoader.java > > > > Hierarchical relationship is `schema > table > column + index` > > At the same time, the scaling module also has a subset of models and loaders that need to be merged (#4866). One issue to further discuss is: > Question 1: Should sharding rules and so on be put in the metadata center uniformly? > > It is recommended to only process datasource metadatas right now, and rule datas should still be placed in config center. See if we want to adjust them later. ### 3. Current Metadata Loading The unified entry for loading metadatas in: > org.apache.shardingsphere.sql.parser.binder.metadata.schema.SchemaMetaDataLoader 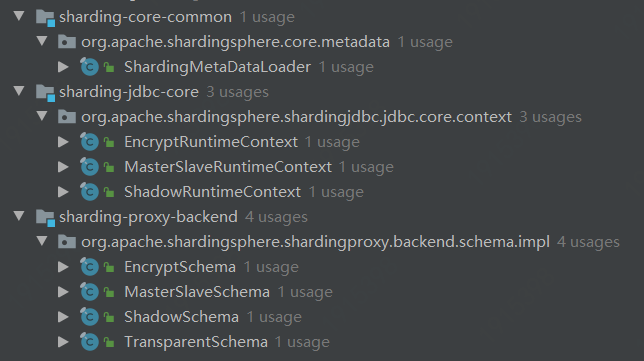 Metadatas are loaded in three places: 1、Sharding-JDBC 2、Sharding-Proxy > Bootstrap.startWithRegistryCenter->LogicSchemas.init/initSchemas->LogicSchemas.initSchemas(for) > > ->LogicSchemaFactory.newInstance->XXSchema->XXSchema.createMetaData/loadSchemaMetaData > > ->SchemaMetaDataLoader.load(dataSource, maxConnectionsSizePerQuery) Each XXSchema class implements guava's @ Subscribe's renew method, which can execute the corresponding rules to refresh them(rules, not metadatas) when an event is received. ShardingSchema and MasterSlaveSchema can additionally support the disableEvent to disable the data source. (This section have a lot codes those can be optimized.) sharding table metadatas loading: > org.apache.shardingsphere.core.metadata.ShardingMetaDataLoader Load the logic part and the default part separately, and then call SchemaMetaDataLoader to load according to the hierarchy. 3、Sharding-scaling There are an independent TableMetaDataLoader/ColumnMetaDataLoader here, used to load its own TableMetaData/ColumnMetaData. ### 4. Metadata Usage **Route Module** * If it is SelectStatementContext, where condition exists, it will participate in obtaining ShadingConditions * If it is DDLStatement, DCLStatement, it will get the table data from it. **Rewrite Module** - Determine if the column exists in metadata. - EncryptPredicateParameterRewriter - EncryptPredicateColumnTokenGenerator - EncryptPredicateRightValueTokenGenerator **Execute Module** * If it is the following types, it will refresh metaData. ```java if (sqlStatementContext instanceof CreateTableStatementContext) { refreshTableMetaData(runtimeContext, ((CreateTableStatementContext) sqlStatementContext).getSqlStatement()); } else if (sqlStatementContext instanceof AlterTableStatementContext) { refreshTableMetaData(runtimeContext, ((AlterTableStatementContext) sqlStatementContext).getSqlStatement()); } else if (sqlStatementContext instanceof DropTableStatementContext) { refreshTableMetaData(runtimeContext, ((DropTableStatementContext) sqlStatementContext).getSqlStatement()); } else if (sqlStatementContext instanceof CreateIndexStatementContext) { refreshTableMetaData(runtimeContext, ((CreateIndexStatementContext) sqlStatementContext).getSqlStatement()); } else if (sqlStatementContext instanceof DropIndexStatementContext) { refreshTableMetaData(runtimeContext, ((DropIndexStatementContext) sqlStatementContext).getSqlStatement()); } ``` **Merge Module** * Not used, use SQL directly to return MetaData from ResultSet ### 5. Metadata Changes Currently, metadatas are loaded and managed by each started sharding-JDBC or proxy node. If a DDL is executed through one node, the following refresh method is directly called to refresh the metadata of the current node. JDBC: > org.apache.shardingsphere.shardingjdbc.executor.AbstractStatementExecutor.refreshMetaDataIfNeeded Proxy: > org.apache.shardingsphere.shardingproxy.backend.schema.impl.ShardingSchema.refreshTableMetaData A tip: The codes in these two places are also heavily duplicated. ### 6. Metadata Center Design From the above sections, we know that there are some points that need improvement: Improvement 1: If there are multiple nodes started at the same time, a large number of metadatas will be repeatedly loaded from the DB, and maybe lead to a performance issue. Improvement 2: Once a node executed a DDL, other nodes don't know that the metadatas had changed, and lead to a consistency issue. We hope to solve these two problems via metadata center design. #### 6.1 Definition The metadata center is a mechanism for unified loading of metadatas, change notifications, and data synchronization through the unified management of all metadatas. #### 6.2 Feature It is planned to sort out the existing metadata loading and all usage scenarios, uniformly manage the metadata to be persisted to the CenterRepository since the metadatas are loaded for the first time, and subsequent nodes will start to obtain metadatas from the metadata center (Improvement 1). When a node performs a DDL operation, the node's metadatas is refreshed and synchronized to CenterRepository, and then all other nodes are notified to synchronize new datas from the metadata center (Improvement 2). #### 6.3 API On the basis of clearing up, the existing metadata loading logic will be restructured, and some loader code will be migrated to the new metadata center module: > sharding-orchestration-center-metadata And the following new API:: 1. MetadataCenter 2. MetadataLoader 3. MetadataNode 4. MetadataListener 5. MetadataChangeEvent #### 6.4 Data Structure The current metadata memory structure is as follows: 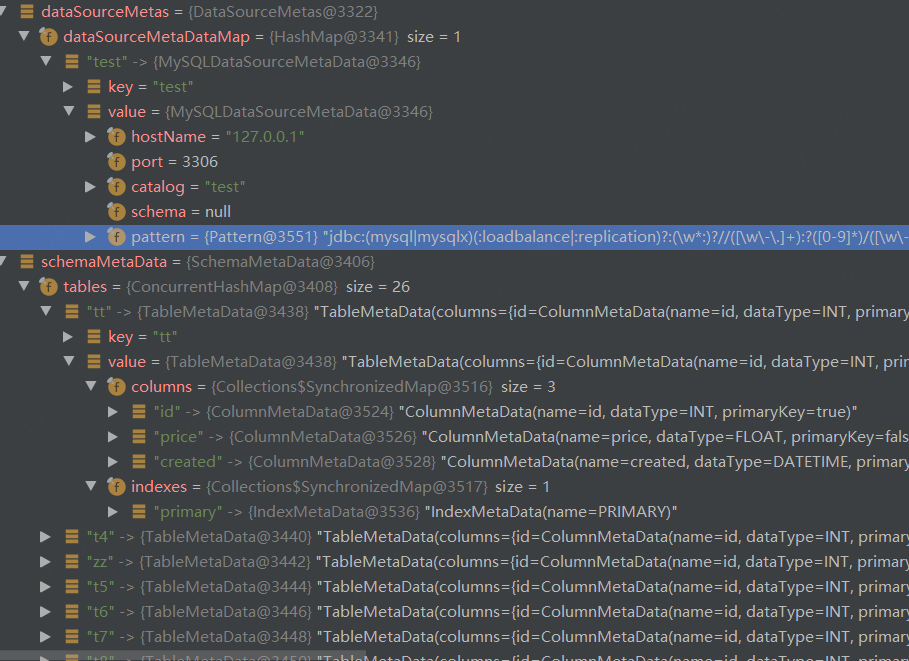 There are two style available metadata structure configurations. CenterRepository metadata structure configuration style one: > ``` > ├─orchestration-namespace > ├─orchestration-name > │ ├─metadata > │ │ ├─ip1:port/catalog/schema > │ │ │ ├─table1 > │ │ │ │ ├─columns > │ │ │ │ └─indexs > │ │ │ ├─table2 > │ │ │ │ ├─columns > │ │ │ │ └─indexs > │ │ ├─ip2:port/catalog/schema > │ │ │ ├─table3 > │ │ │ │ ├─columns > │ │ │ │ └─indexs > │ │ │ ├─table4 > │ │ │ │ ├─columns > │ │ │ │ └─indexs > ``` CenterRepository metadata structure configuration style two: > ``` > ├─orchestration-namespace > ├─orchestration-name > │ ├─metadata > │ │ ├─ip1:port/catalog/schema > │ │ │ ├─ [json/yaml text contents] > ``` Style one: It is intuitive and fine-grained. Style two: It is simpler and easier to manage. (It is recommended to use style 2.) One question: > Question 2: Will the logic table be displayed here? > > I think the answer is no. > > Only the actual real tables metadatas here, logic table is not a part of metadata. #### 6.5 Loading Current loading process: > Load sharding tables first, then load default tables, and check whether the metadatas of all tables is consistent according to the check.metadata.enable parameter. New loading process: > After loading metadata, write to CenterRepository, then trigger global notification. > Question 3: Are the metadatas of this step written to CenterRepository after each group or datasource is loaded, or after all metadatas loaded and written them once (related to triggering one or more events). > > Consider to implement a full synchronizing at first, and then see if it can be persisted and notified in batches, based on loading speed. #### 6.6 Synchronization After DDL is executed in one node, the metadatas of this node is refreshed through the Event mechanism(instead of local method calling), synchronized to CenterRepository, and then a global change notification is triggered to other nodes. > Question 4: Do we need to hold the loading process of other nodes to prevent concurrency. > > Do not consider concurrency at first, implement the load and notify function, and finally solve this problem, maybe involving distributed locks. 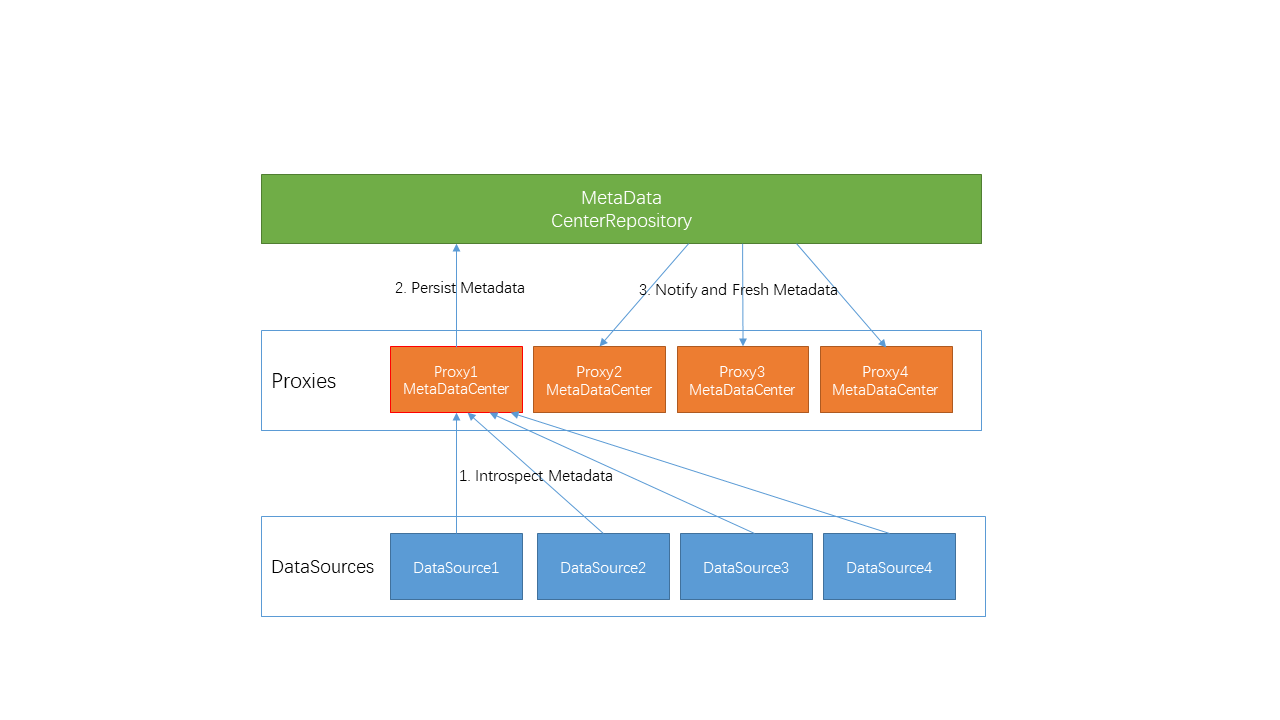 #### 6.7 Notification Through the Event mechanism, other nodes are notified and then update metadatas from CenterRepository. 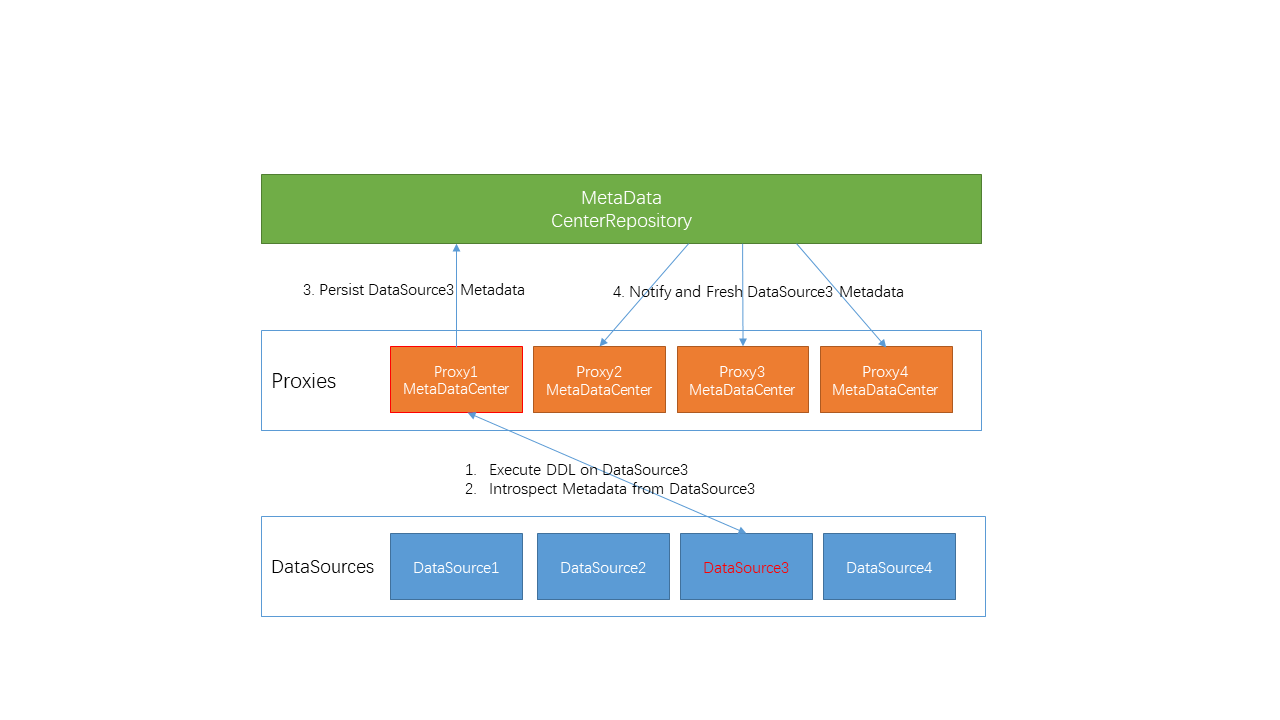 ### 7. Task list - [ ] 7.1 metadata carding - [ ] 7.2 metadata refactoring (code abstraction and cleanup) - [ ] 7.3 Add center-metadata related project structure - [ ] 7.4 Implementing metadata persistence - [ ] 7.5 Migrating some loader codes - [ ] 7.6 Implementing the event notification mechanism - [ ] 7.7 Implementing Global Synchronization - [ ] 7.8 Optimize loading and usage - [ ] 7.9 Improve Unittests - [ ] 7.10 Implementing examples - [ ] 7.11 Implementing documents
{kind=link}
{kind=link}
{kind=link}
{kind=link}
---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected] With regards, Apache Git Services