This is an automated email from the ASF dual-hosted git repository.
panjuan pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/shardingsphere.git
The following commit(s) were added to refs/heads/master by this push:
new cf3b50b Update result.en.md
new 609d897 Merge pull request #7133 from yang-7777/patch-9
cf3b50b is described below
commit cf3b50b8bf1e1f2a5d33820e700435af7cac5cf9
Author: yang-7777 <[email protected]>
AuthorDate: Fri Aug 28 19:29:46 2020 +0800
Update result.en.md
---
docs/blog/content/material/result.en.md | 117 +++++++++++++++++++++++++++++++-
1 file changed, 116 insertions(+), 1 deletion(-)
diff --git a/docs/blog/content/material/result.en.md
b/docs/blog/content/material/result.en.md
index ec9e17b..71e100d 100644
--- a/docs/blog/content/material/result.en.md
+++ b/docs/blog/content/material/result.en.md
@@ -4,4 +4,119 @@ weight = 11
chapter = true
+++
-## TODO
+## How to merge the child resultsets
+
+This series of articles is a hands-on introduction and analysis of SS's core
modules, the cutting-edge technologies used, and valuable lessons learned by
SS's core development members. This series of articles will take you into the
world of SS kernel, to gain new knowledge and inspire. We hope you will pay
attention to us, exchange ideas and go forward together.
+
+### Lecturers
+
+Liang Zhang, former head of Dangdang's architecture department. A passion for
open source, currently leading two open source projects Elastic-Job and
Sharding-Sphere (Sharding-JDBC). Specializing in java-based distributed
architecture and Kubernetes and Mesos-based cloud platform direction, advocate
for elegant code, more research on how to write expressive code.Joined BOF in
early 2018, now as the head of data research and development. Currently, the
main focus is on building Sharding-S [...]
+
+### Introduction
+
+Combining multiple data result sets from various data nodes into one result
set and returning it correctly to the requesting client is called result
imputation.
+
+The result merging supported by Sharding-Sphere is functionally categorized
into four types of traversal, sorting, grouping and paging, which are
combinations rather than mutually exclusive relationships. Structurally, it can
be divided into streaming, in-memory and decorator grouping. Streaming and
memory imputation are mutually exclusive, and decorator imputation can be
further processed on top of stream imputation and memory imputation.
+
+Since the result set returned from the database is returned one by one, it is
not necessary to load all the data into memory at once, therefore, when merging
the results, merging in the same way as the result set returned from the
database can greatly reduce memory consumption, and is the preferred method of
merging.
+
+Streaming merge means that each time the data is fetched from the result set,
the correct individual data can be returned by fetching it one by one, which is
most compatible with the way the database returns the result set natively.
Traversal, sorting, and Stream Group-by Merger are all types of stream
imputation.
+
+In-memory merging, on the other hand, requires that all data in the result set
be traversed and stored in memory, and then after unified grouping, sorting,
and aggregation calculations, it is encapsulated to return the result set of
data accessed one item at a time.
+The decorator merge is a unified functional enhancement of all the result set
merge, currently the decorator merge only paging this type of merge.
+
+
+### Categorization
+
+
+#### Iteration Merger
+It is the simplest form of aggregation. Simply merge multiple result sets into
a one-way chain table. After iterating through the current result set in the
chain table, move the chain table element back one place and continue to
iterate through the next result set.
+
+#### Order-by Merger
+
+Due to the existence of the ORDER BY statement in SQL, each data result set is
itself ordered, so only the data values that the current cursor of the data
result set points to need to be sorted. This is equivalent to sorting multiple
ordered arrays, and merge sorting is the most appropriate sorting algorithm for
this scenario.
+
+
+
+Sharding-Sphere compares the current data values of each result set (done by
implementing Java's Comparable interface) and places them in a priority queue
when the sorted queries are merged. Each time the next piece of data is
fetched, simply move the cursor of the result set at the top of the queue down
and find your place in the priority queue again based on the new cursor. To
illustrate Sharding-Sphere's sorting and merging with an example, the following
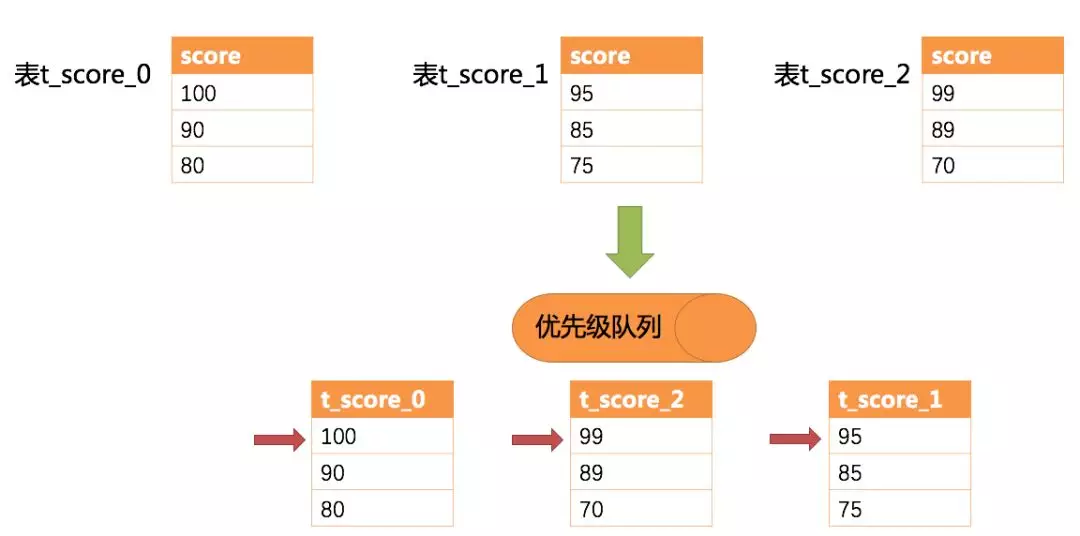
diagram shows an example of so [...]
+
+
+
+
+
+The example shows 3 tables returning data result sets, each of which is
already sorted according to score, but is unordered between the 3 data result
sets. The data values pointed to by the current cursor for each of the 3 result
sets are sorted and placed into a priority queue, with the first data value of
t_score_0 being the largest, the first data value of t_score_2 the next
largest, and the first data value of t_score_1 the smallest, so the priority
queue is based on the t_score_0, t [...]
+
+The following diagram shows how the sorting and merging is done when the next
call is made.
+
+
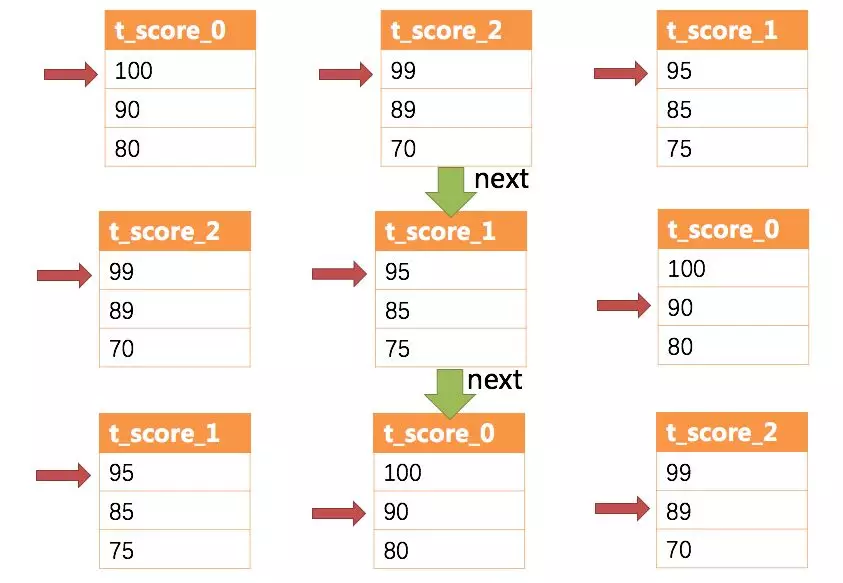
+
+
+As we can see from the diagram, when the first NEXT call is made, t_score_0,
which is at the top of the queue, is ejected from the queue and returns the
data value (i.e., 100) that the current cursor points to to the querying
client, and is placed back into the priority queue after moving the cursor down
one place. The priority queue is also ranked according to the data value (in
this case 90) that the current result set of t_score_0 points to for the
cursor, with t_score_0 ranked last i [...]
+
+For a second NEXT, simply eject the t_score_2 currently at the top of the
queue and return the value pointed to by its data result set cursor to the
client, and move the cursor down to continue to join the queue for queuing, and
so on.
+
+When there is no more data in a result set, there is no need to join the queue
again.
+
+As you can see, when the data in each result set is ordered, but the whole
result set is disordered, Sharding-Sphere can sort the data without adding all
the data to memory, it uses stream merge, each time only one correct data is
obtained by next, which greatly saves memory consumption.
+
+From another perspective, Sharding-Sphere's sorting and merging is maintaining
the orderliness of the two dimensions of the data result set, the vertical axis
and the horizontal axis. The vertical axis refers to each data result set
itself, which is naturally ordered and is fetched by the SQL containing ORDER
BY. The horizontal axis refers to the values pointed to by the current cursor
of each result set, which need to be maintained in the correct order by the
priority queue. Each time t [...]
+
+#### Group-by Merger
+
+Grouping by Merger is the most complex, and it is divided into Stream Group-by
Merger and in-memory grouping. Stream Group-by Merger requires that the fields
and sort type (ASC or DESC) of SQL's sorted and grouped items must be
identical, otherwise only in-memory grouping can ensure the correctness of its
data.
+
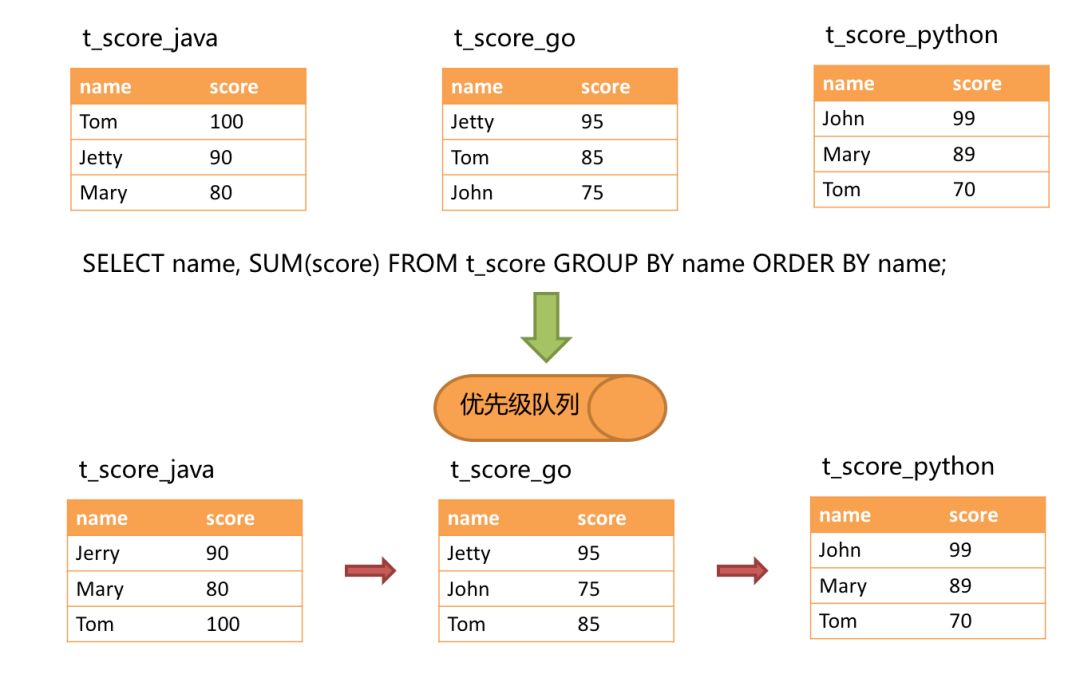
+To illustrate, suppose that the table structure contains the candidate's name
(disregarding renames for simplicity) and score based on subject slicing. The
total score for each candidate can be obtained via SQL as follows.
+
+ 
+
+In the case where the grouping item is identical to the sorting item, the data
obtained is continuous, and the full amount of data required for grouping
exists in the data values pointed to by the current cursor of each data result
set, so streamwise merging can be used. This is shown in the figure below.
+
+
+
+
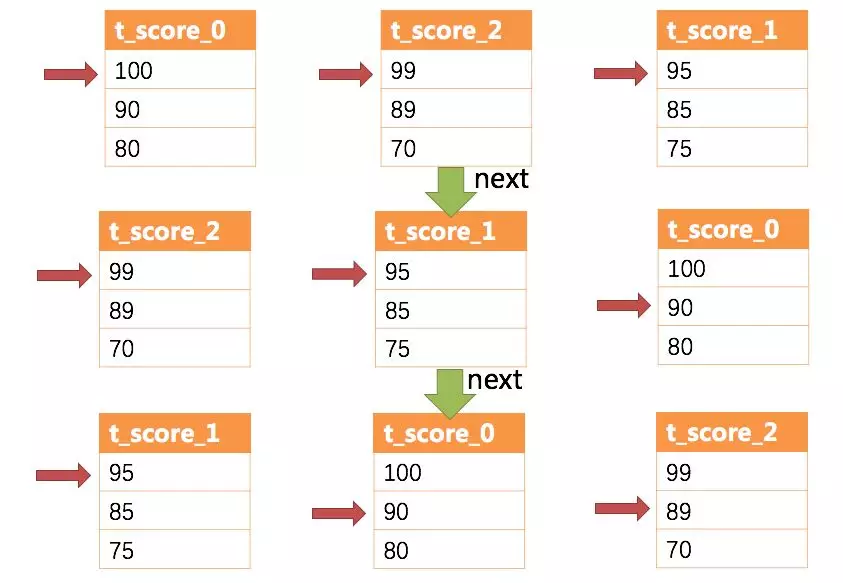
+When performing a merge, the logic is similar to a sorted merge. The following
diagram shows how stream group merging is performed when next call is made.
+
+
+
+
+As you can see in the diagram, when the first next call is made, the first
t_score_java is ejected from the queue, along with all other result sets with
the same value as "Jetty". After obtaining the scores of all students named
"Jetty" and adding them up, the result set is the sum of "Jetty's" scores at
the end of the first next call. At the same time, all cursors in the result set
are moved down to the next different value of "Jetty" and re-sorted according
to the value of the current [...]
+
+Stream Group-by Merger merging differs from sorted merging in just two ways.
+
+1. It will be a one-time multiple data result set of grouped items of the
same data out of all.
+2. It needs to be aggregated according to the type of aggregation function
to calculate.
+
+For cases where the grouped item does not match the sorted item, since the
data values associated with the grouping that needs to be obtained are not
continuous, stream merging cannot be used and all the result set data needs to
be loaded into memory for grouping and aggregation. For example, if the
following SQL is used to obtain the total score for each candidate and sort the
scores from highest to lowest.
+
+
+ 
+
+
+Then the data taken out of each data result set is consistent with the
original data in the table structure in the upper half of the sorting example
diagram for the scores, and it is not possible to perform streamwise summation.
+
+When the SQL contains only grouping statements, the order of sorting may not
be the same as the grouping order depending on the implementation of different
databases. However, the absence of the sorting statement means that this SQL
does not care about the sorting order. Therefore, Sharding-Sphere automatically
adds sorted items consistent with grouped items through SQL-optimized rewrites,
allowing it to convert from a memory-consuming in-memory grouped imputation
approach to a streaming [...]
+
+The handling of aggregation functions is the same for both stream grouping and
in-memory grouping. Aggregation functions can be categorized into three types:
comparison, accumulation and averaging.
+
+Comparison of the type of aggregate function refers to MAX and MIN. they need
to be compared with each group of the results of the set of data, and directly
return the maximum or minimum value can be.
+Sum and COUNT are aggregation functions that need to be added to the result
set for each cohort.
+
+It must be calculated by the SQL rewrite of SUM and COUNT, the relevant
content has been covered in the SQL rewrite, not to repeat.
+
+
+#### Pagination Merger
+
+Pagination is possible for all of the merge types described above. Pagination
is a decorator appended on top of other merge types, and Sharding-Sphere adds
the ability to paginate the result set of data through the decorator mode. The
Pagination imputation is responsible for filtering out data that does not need
to be fetched.
+
+Sharding-Sphere's Pagination capabilities are rather misleading to users, who
often think that paged merging takes up a lot of memory. In a distributed
scenario, it is necessary to rewrite LIMIT 10000000, 10 to LIMIT 0, 10000010 in
order to ensure that their data is correct. It is very easy for users to create
the illusion that Sharding-Sphere will load large amounts of meaningless data
into memory, creating a risk of memory overflow. In fact, through the principle
of stream merge, we ca [...]
+
+However, it is also important to note that a large amount of data still needs
to be transferred to Sharding-Sphere's memory space due to the sorting needs.
Therefore, it is not a best practice to use LIMIT for Pagination in this
manner. Since LIMIT does not query data by index, Pagination by ID is a better
solution if continuity of ID can be guaranteed, e.g..
+
+
+
+
+Or by recording the ID of the last record of the last query result for the
next page, for example.
+
+
+
+
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}