This is an automated email from the ASF dual-hosted git repository.
panjuan pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/shardingsphere.git
The following commit(s) were added to refs/heads/master by this push:
new 5cd00fb Update engine.en.md (#8229)
5cd00fb is described below
commit 5cd00fbbfa6a359a81cb92b3a82521f1516612d9
Author: yang-7777 <[email protected]>
AuthorDate: Fri Nov 20 10:49:27 2020 +0800
Update engine.en.md (#8229)
---
docs/blog/content/material/engine.en.md | 125 +++++++++++++++++++++++++++++++-
1 file changed, 124 insertions(+), 1 deletion(-)
diff --git a/docs/blog/content/material/engine.en.md
b/docs/blog/content/material/engine.en.md
index 448bbc3..defbd5b 100644
--- a/docs/blog/content/material/engine.en.md
+++ b/docs/blog/content/material/engine.en.md
@@ -4,4 +4,127 @@ weight = 10
chapter = true
+++
-## TODO
+## How automatic executor of ShardingSphere works
+
+Today「Analysis of Sharding-Sphere Series Articles」is brings you an
introduction to the Sharding-Sphere automated execution engine module in this
article. Since the boss prefers serious technical articles, I try my best to
use a serious and solemn narrative style to share with you the topic of
"Sharding-Sphere Automated Execution Engine Module".
+
+I just finished writing and sorting out the code of this module, so before I
forget, I would like to share this with you, hope this article will help you
all.
+
+「Analysis of Sharding-Sphere series articles」is conducted by the core
development members of Sharding-Sphere to introduce and analyze the core
modules of Sharding-Sphere, the cutting-edge technologies used, and valuable
experience summaries. This series of articles will take you into the core world
of Sharding-Sphere, gain new knowledge and inspire inspiration. I hope you will
follow us, communicate and discuss with us, and we will move forward together.
+
+### About the author
+
+Pan Juan, as a senior DBA worked at JD.com, the responsibility is to develop
the distributed database and middleware, and the automated management platform
for database clusters. As a PMC of Apache ShardingSphere, I am willing to
contribute to the OS community and explore the area of distributed databases
and NewSQL.
+
+### Concept introduction
+
+Q: What is "automated execution engine"?
+
+A: The life cycle of a SQL is: initiated from the client, processed by
Sharding-Sphere, and then executed and digested in the underlying database. In
Sharding-Sphere, the process is: SQL analysis-->SQL optimization-->SQL
routing-->SQL rewriting-->SQL execution-->result merging. The automatic
execution engine is for deal with the SQL execution problem, that is, how to
control and efficiently transmit the real SQL after the route rewriting to the
underlying database for execution. Doesn't [...]
+
+### Demand scenario
+
+Q: Why do we need an automated execution engine?
+
+A: In the concept introduction section, we introduced the protagonist-the
automated execution engine. It is also mentioned that its automation is to
balance the creation of database connections and the selection of results merge
mode. This is the fate of its birth, the choice of history. The following will
introduce these two issues that need to be balanced:
+
+1. Database connection creation
+
+As a DBA/Java coder, somehow I still consider the problem from the perspective
of the DBA. For example, from the perspective of resource control, the number
of connections for business parties to access the database should be limited,
which can effectively prevent a certain business operation from occupying too
much resources, thereby exhausting the resources of the database connection,
and thus affecting other business visit. Especially when there are many
sharding tables in a database [...]
+
+2. Results merge mode selection
+
+From the perspective of execution efficiency, maintaining an independent
database connection for each fragmented query can more effectively use
multithreading to improve execution efficiency. Opening independent threads for
each database connection can parallelize the consumption of IO. The independent
database connection can keep the reference of the query result set and the
cursor position, and the cursor can be moved when the corresponding data needs
to be obtained, avoiding the prema [...]
+
+Streaming merge: The method of merging results by moving the result set cursor
down is called streaming merge. It does not need to load all the result data
into memory, which can effectively save memory resources and reduce the
frequency of garbage collection.
+
+Memory merging: Perform data comparison and merging by reading the result set
loaded in the memory for merging. It needs to load all the result data into
memory.
+
+I believe everyone will definitely choose streaming merge to process the
result set. However, if there is no guarantee that each shard query holds an
independent database connection, then you need to load the current query result
set into memory before reusing the database connection and obtaining the query
result set of the next shard table. Therefore, even if stream merging can be
used, it has to use memory merging in this scenario.
+
+On the one hand, it is the control and protection of database connection
resources. On the other hand, it uses a better merge mode to save memory
resources. How to handle the relationship between the two is a problem that the
ShardingSphere execution engine needs to solve. Specifically, if a piece of SQL
needs to operate 200 tables under a certain database instance after it has been
sharding by ShardingSphere, should it choose to create 200 connections for
parallel execution, or choose t [...]
+
+### Evolutionary theory
+
+For the above scenario, ShardingSphere provided a solution before 3.0.0.M4,
which introduced the concept of Connection Mode and divided it into two modes:
MEMORY_STRICTLY and CONNECTION_STRICTLY.
+
+- MEMORY_STRICTLY: This mode is used on the premise that the database has no
limit on the number of connections it can consume in a single operation. If the
actual execution of SQL needs to do operations on 200 tables in a database
instance, a new database connection is created for each table and processed
concurrently in a multi-threaded manner to maximize execution efficiency.
Streaming is preferred if SQL satisfies the conditions to prevent memory
overflow or avoid frequent garbage co [...]
+
+- CONNECTION_STRICTLY: This mode is based on the premise that the database
strictly controls the number of connections it consumes in a single operation.
If the actual SQL execution requires an operation on 200 tables in a database
instance, only a unique database connection will be created and its 200 tables
will be processed serially. If the sharding is on different databases, it is
still multi-threaded to process the different libraries, but still only one
unique database connection i [...]
+
+MEMORY_STRICTLY is used for OLAP operations, where the system throughput can
be increased by relaxing the restrictions on database connections;
connection-limited mode is used for OLTP operations, where OLTP is often routed
to a single slice with a slice key, so it is wise to keep database connections
tightly controlled to ensure that the online system's database resources can be
used by more applications.
+
+ShardingSphere leaves the decision of which mode to use to the user, and
provides configuration of the connection mode, allowing the developer to choose
between MEMORY_STRICTLY or CONNECTION_STRICTLY.
+
+However, leaving the hard decision to the user makes it necessary for the user
to understand the pros and cons of the two modes and make choices based on the
needs of the business scenario. This obviously increases the user's cost of
learning and using, which is not an optimal solution.
+
+In addition, this processing scheme leaves the switching of the two modes to a
static initialization configuration, which lacks flexibility. In actual usage
scenarios, facing different SQL and placeholder parameters, each routing result
is different. This means that some operations may need to use memory merging,
and some operations may better choose streaming merging. They should not be
configured by the user before ShardingSphere is started, but should be based on
SQL and placeholder p [...]
+
+ShardingSphere always considers problems from the user's point of view and
keeps optimizing and diligent, must make relevant optimization adjustments, so
the automated execution engine has evolved.
+
+In order to reduce the using cost and connect dynamic mode, ShardingSphere has
refined the idea of an automated execution engine and digested the concept of
the connection mode inside. The user does not need to know what the so-called
memory limit mode and connection limit mode are, but the execution engine
automatically selects the optimal execution plan according to the current
scenario.
+
+At the same time, the automated execution engine refines the selection of the
connection mode to every SQL operation. For each SQL request, the automated
execution engine will perform real-time calculations and trade-offs based on
its routing results, and autonomously adopt the appropriate connection mode for
execution to achieve the optimal balance of resource control and efficiency.
For the automated execution engine, users only need to configure
maxConnectionSizePerQuery. This paramet [...]
+
+### Implementation analysis
+
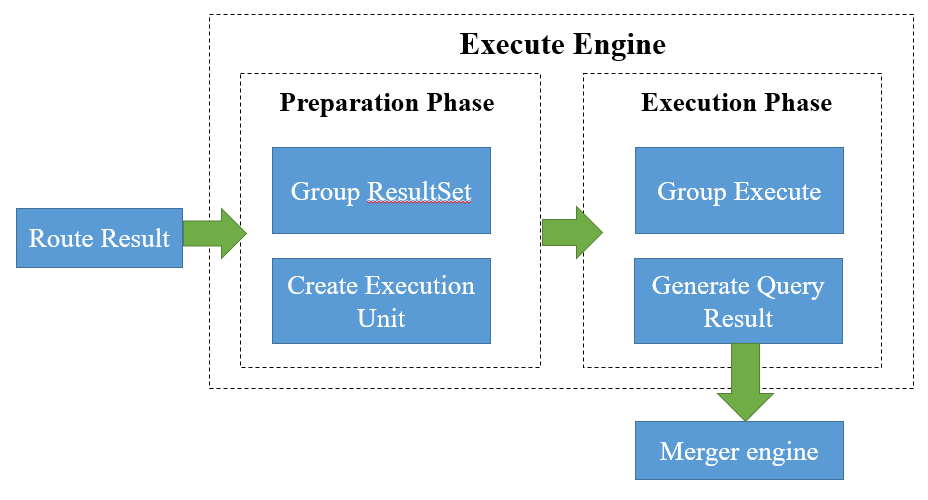
+The execution flow of the entire automated execution engine is shown below:
+
+
+
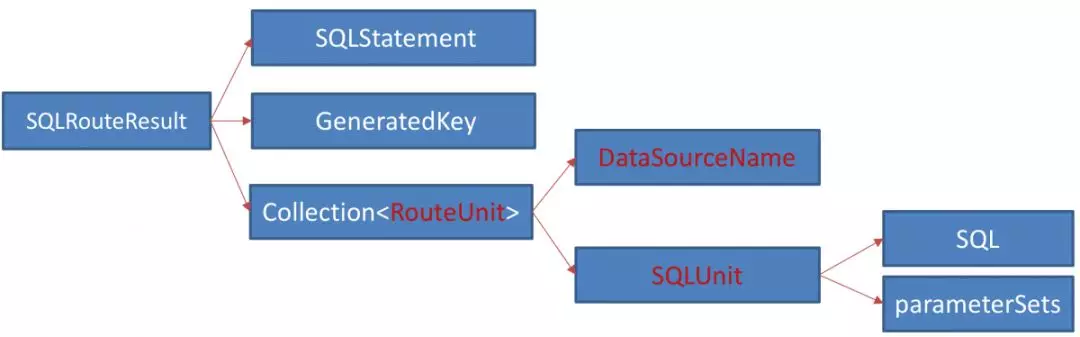
+After the route rewrite is complete, we get the route result, which is a
result set that contains mainly information about SQL, SQL's parameter set,
database, and so on. Its data structure is shown in the following figure.
+
+
+
+The execution process of the execution engine is divided into two phases:
preparation and execution.
+
+* Preparation phase
+
+As the name implies, this stage is used to prepare the data for execution. It
is divided into two steps: result set grouping and execution unit creation.
+
+ a. Result set grouping
+
+This step is key to implementing the concept of internalized connection
patterns. The execution engine automatically selects the appropriate connection
mode based on the maxConnectionSizePerQuery configuration item, combined with
the current routing results. The specific steps are as follows:
+
+- Group the SQL routing results according to the name of the database.
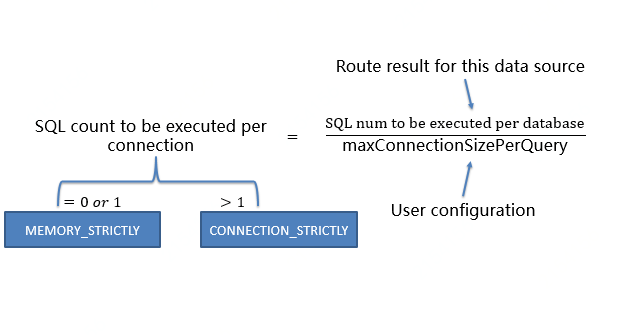
+- Obtain the set of SQL routing results that each database instance needs to
perform for each database connection within the allowable limits of
maxConnectionSizePerQuery by using the formula below and evolve the optimal
connection pattern for this request.
+
+
+
+Within the limits allowed by maxConnectionSizePerQuery, when the number of
requests to be executed for a connection is greater than 1, it means that the
current database connection cannot hold the corresponding data result set and
must use in-memory merging; conversely, when the number of requests to be
executed for a connection is equal to 1, it means that the current database
connection can hold the corresponding data result set and can use streaming
merging.
+
+The choice of the connection pattern is made for each physical database each
time. In other words, if routed to more than one database in the same query,
the connection patterns are not necessarily the same for each database; they
may be in mixed form.
+
+ b. Execution of unit creation
+
+This step creates units for execution through the route grouping results
obtained in the previous step. The execution unit is the unit that creates the
corresponding database connection for each route grouping result.
+
+When the database is limited to the number of connection resources and there
are a large number of concurrent operations in the online business, deadlocks
are likely to be sent if the concurrent acquisition of database connections is
not handled properly. When multiple requests are waiting for each other to
release database connection resources, there is a starvation wait, resulting in
cross deadlocks.
+
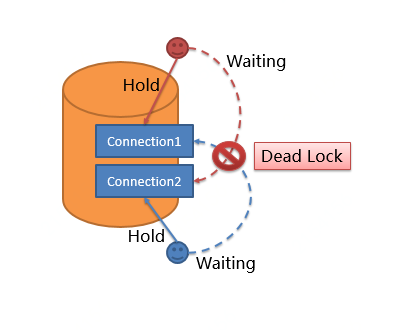
+For example, suppose that a single query needs to fetch 2 database connections
on a particular database for routing to 2 sub-table queries of a library. It is
possible that query A has already obtained 1 database connection on that
database and is waiting to obtain the other database connection, while query B
has also obtained 1 database connection on that database and is also waiting
for the other database connection to be obtained. If the maximum number of
connections allowed to the da [...]
+
+
+
+In order to avoid deadlock, ShardingSphere synchronizes the database
connection. When creating the execution unit, it obtains all the database
connections required by this SQL request in an atomic way, which eliminates the
possibility of obtaining some resources for each query request. This locking
method can solve the deadlock problem, but it will bring a certain degree of
concurrent performance loss. To show that we are different! What's the
difference?
+
+In view of this problem, we also carried out the following two aspects of
Optimization:
+
+1\. Avoid locking and only need to obtain one database connection at a
time. Because only one connection needs to be obtained at a time, there is no
need to lock two requests waiting for each other. For most OLTP operations, the
fragmentation key is used to route to the only data node. At this time, there
is no need to worry about cross deadlock and lock addition, so as to reduce the
impact on concurrent efficiency. In addition to routing to a single fragment,
read-write separation al [...]
+
+2\. Lock linked resources only for memory limited mode. When using the
connection restriction mode, the database connection resources are released
after all query result sets are loaded into memory, so it is not necessary to
consider deadlock waiting and locking processing.
+
+* Implementation phase
+
+This stage is used for real SQL execution. It is divided into two steps:
grouping execution and merging result set generation.
+
+ a. Group execution
+
+In this step, the execution units generated in the preparation phase are
distributed to the underlying concurrent execution engine, and events are sent
for each key step in the execution process. For example: execution start event,
execution success event and execution failure event. The execution engine only
cares about the sending of events, it doesn't care about the subscribers of the
events. Other ShardingSphere modules, such as distributed transactions and call
link tracing, subscri [...]
+
+ b. Merge result set generation
+
+ShardingSphere generates memory merge result set or stream merge result set
through connection mode acquired in execution preparation phase, and passes it
to result merging engine for further work. The core difference between memory
merge result set and stream merge result set is: stream merge result set gets
data of result set by cursor, while memory merge result set gets data from
memory. This is also the data base of memory merge and stream merge.
+
+Through all the above steps, the execution process of the automatic execution
engine is completed. Its core purpose is to automatically balance the database
connection creation and result merge mode selection, to achieve a fine-grained
balance between resource control and execution efficiency of each query, so as
to reduce the user's learning cost and worry about the change of business
scenarios.
+
+The article you reading is the result of my repeated modifications. I cannot
be rewarded, just hope that you can get something from reading, which is the
meaning of our coding and writing. In the future, there will be other articles
in the analysis of ShardingSphere series. Please pay attention~
{kind=link}
{kind=link}
{kind=link}
{kind=link}