danielzhou888 opened a new issue #8942: URL: https://github.com/apache/shardingsphere/issues/8942
## Why the performance of interface stress test used by shardingjdbc-4.0.1 is low obviously than not using sub-meter middleware! What we do wrong! Please help! We use shardingjdbc as the sub-table middleware of the shop product table, but when we were doing interface stress testing, we found that using sub-meter middleware is much weaker in performance than not using sub-meter middleware. **The specific instructions are as follows:** ### Application machine hardware parameter configuration |Index|Value|Remark| |:--|:--|:--| |CPU(s)|4|| |Model Name|Intel Xeon Processor (Skylake, IBRS)|| |Memory|8G|| |System|CentOS Linux release 7.6.1810 (Core) || |Linux Version|3.10.0-1062.el7.x86_64|| ### Interface pressure test preparation - 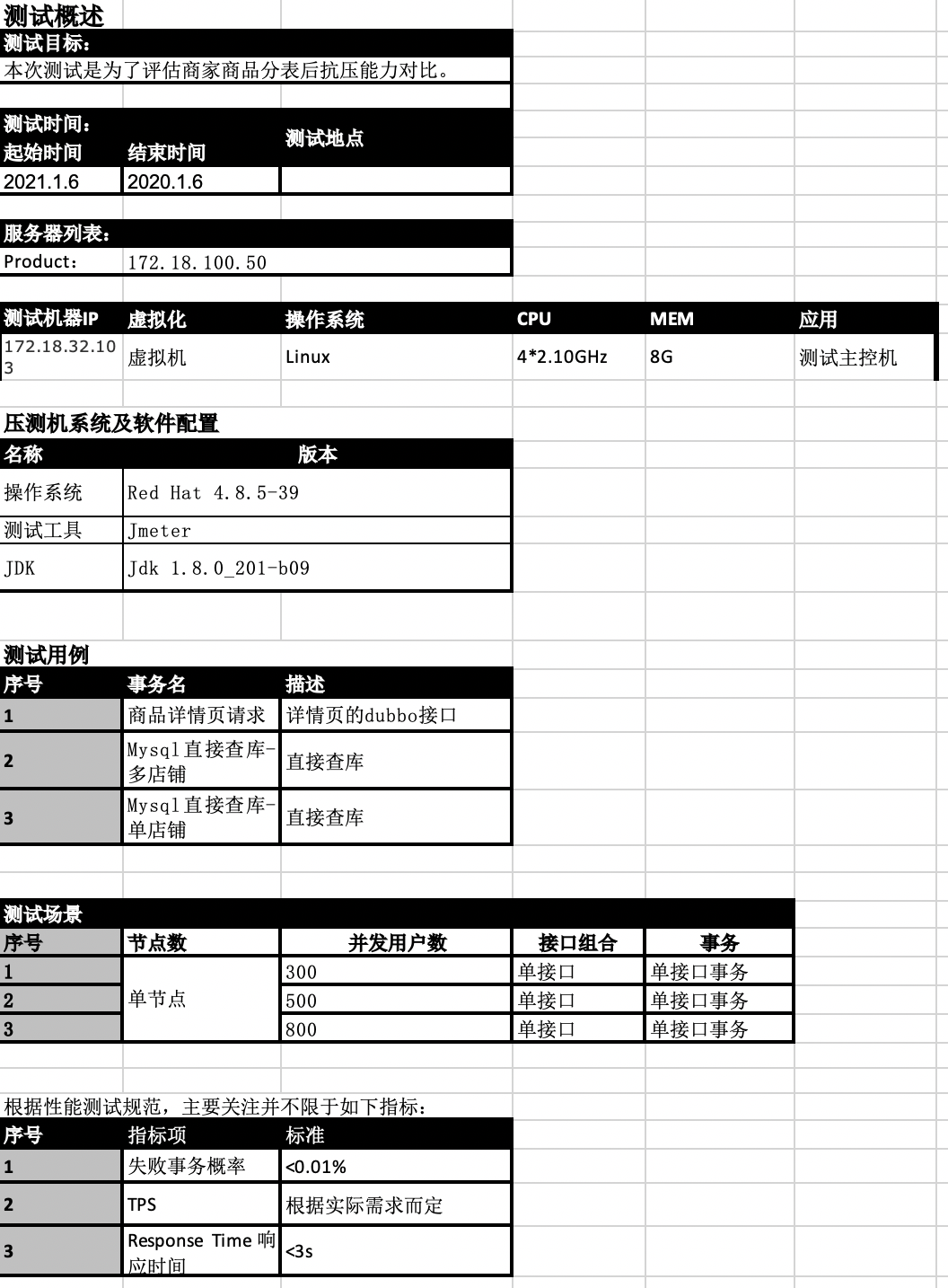 ### Result of Interface Stress Test Of Fixed Value Single Shard Key - 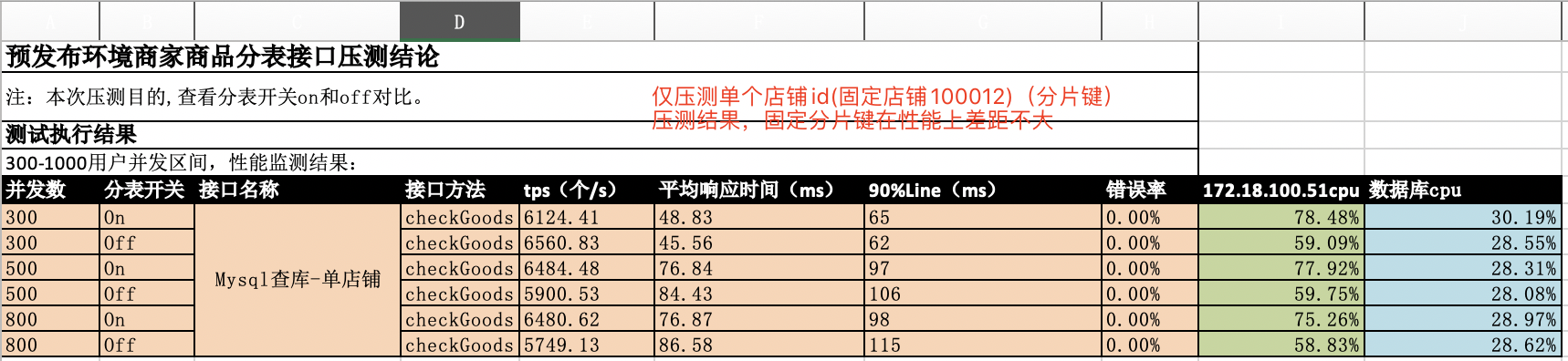 **In Conclusion:** From the above figure, we can see that when the shard value is fixed, the overall performance of using the table-sharing middleware and not using the table-sharing middleware is equivalent. **This result is expected!** ### Result of Interface Stress Test Of Random Value Single or Multi Shard Key - 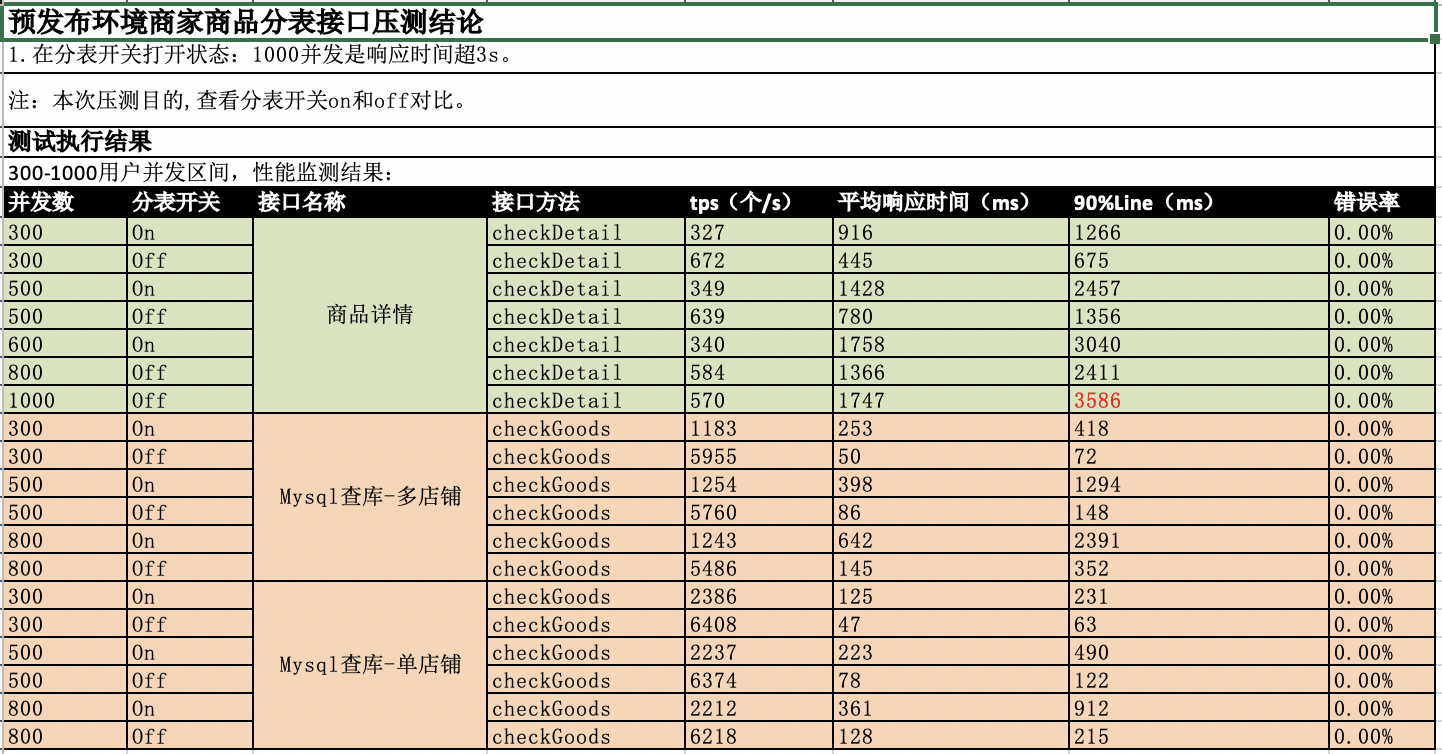 **In Conclusion:** 1. Single Random Shard Value: -  - We can see that under the same concurrency, the performance index throughput is 4 times that of using sub-table middleware without using sub-table middleware. - We can see that under the same concurrency, the average response time of performance indicators is 3 times that of using sub-table middleware without using sub-table middleware. 2. Multi Random Shard Value: -  - We can see that under the same concurrency, the performance index throughput is 5 times that of using sub-table middleware without using sub-table middleware. - We can see that under the same concurrency, the average response time of performance indicators is 5 times that of using sub-table middleware without using sub-table middleware. ### Database machine load - 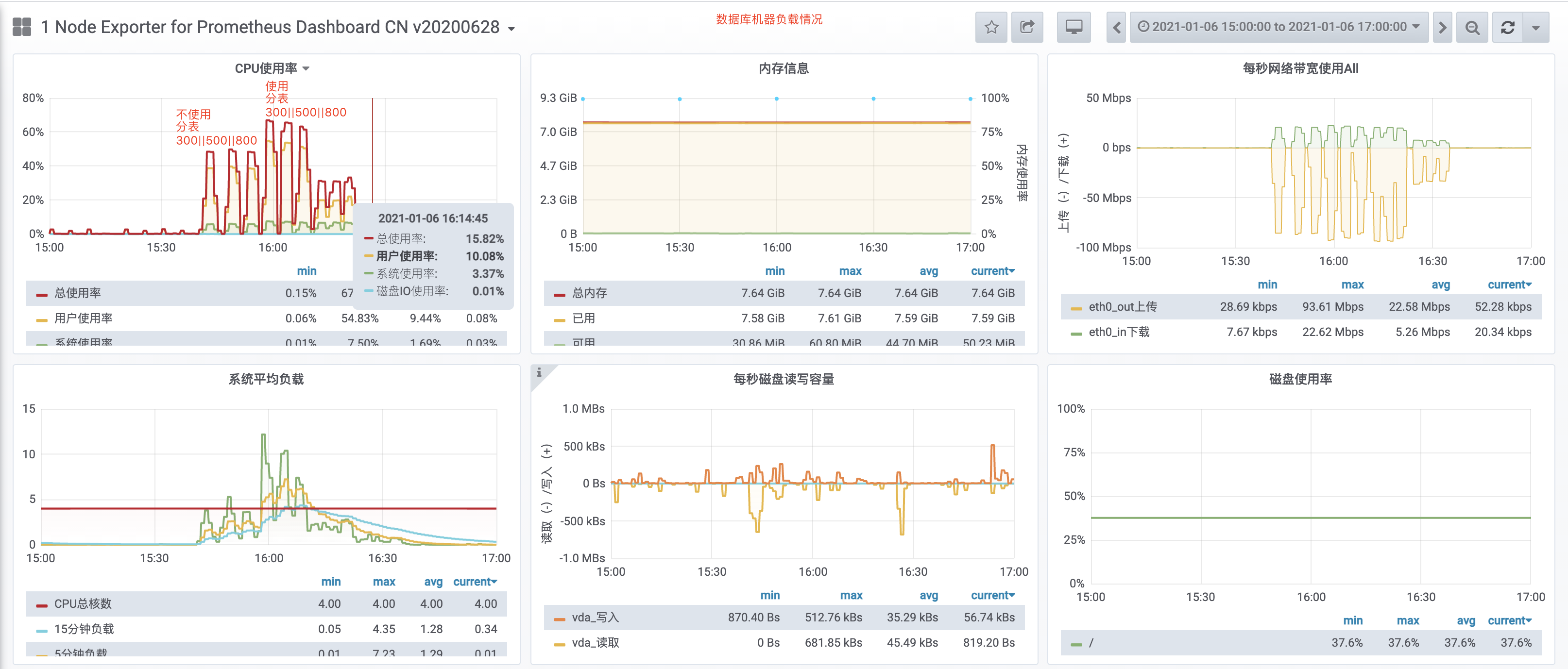 - 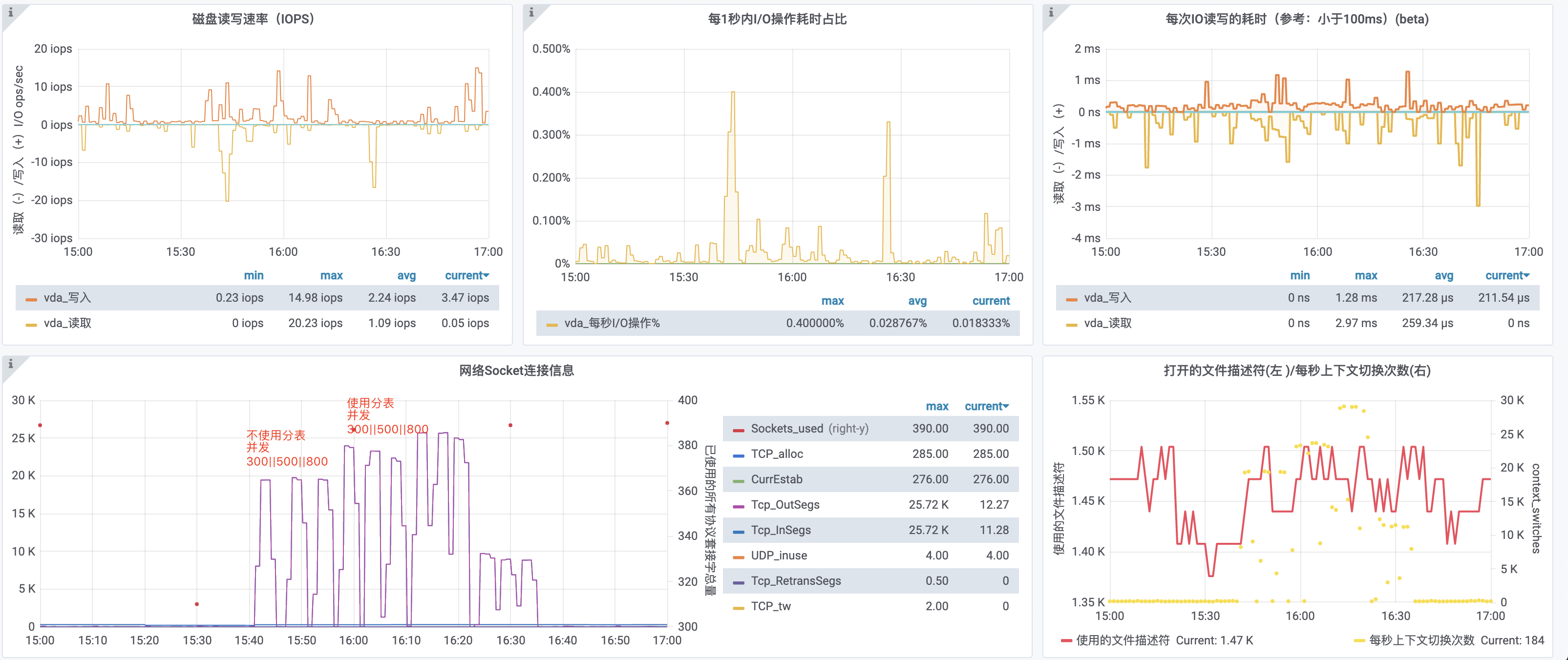 ### Our own guess - Fixed Value Single Shard Key:Shardingjdbc just does SQL analysis and routes all requests to a fixed sub-table. At this time, the main table and sub-table are cached in the system, and the pressure on the database level is quite. - Random Value Single Or Multi Shard Key:When concurrently stressing the random sharding key value, when the sharding table is not used, only the main table is requested. The database has a system cache that can hit the cache, so the response is fast; when the sharding table is turned on, different sharding key values are routed to different When the request arrives in the database, it cannot hit the system cache well, so it brings huge pressure to the database. As a result, the CPU soars, the overall application service encounters bottlenecks, the throughput is degraded, and the response slows. ### We need developers to help analyze We want to find out the specific reasons, whether we have made an error in the way of use and configuration, or where is the problem? ---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}