RedRed228 edited a comment on issue #2038: URL: https://github.com/apache/shardingsphere-elasticjob/issues/2038#issuecomment-1013025677
The issue sometimes looks like: when we triggered the job, no shard was triggered at all. I didn’t get the dump file but checked the zookeeper node directly when the problem occurred. From the zookeeper data I saw the resharding necessary flag was set and the leader was elected, but the leader didn’t do resharding. The leader instance has many debug logs:  The ip server node is a server that have been deleted by us. We deleted the node and this is the cause of the issue, I will discuss of the reason why we delete the server node later. The follower instances have many debug logs:  With the debug logs, we can infer that the leader didn’t do resharding. So I dumped the leader’s stack: 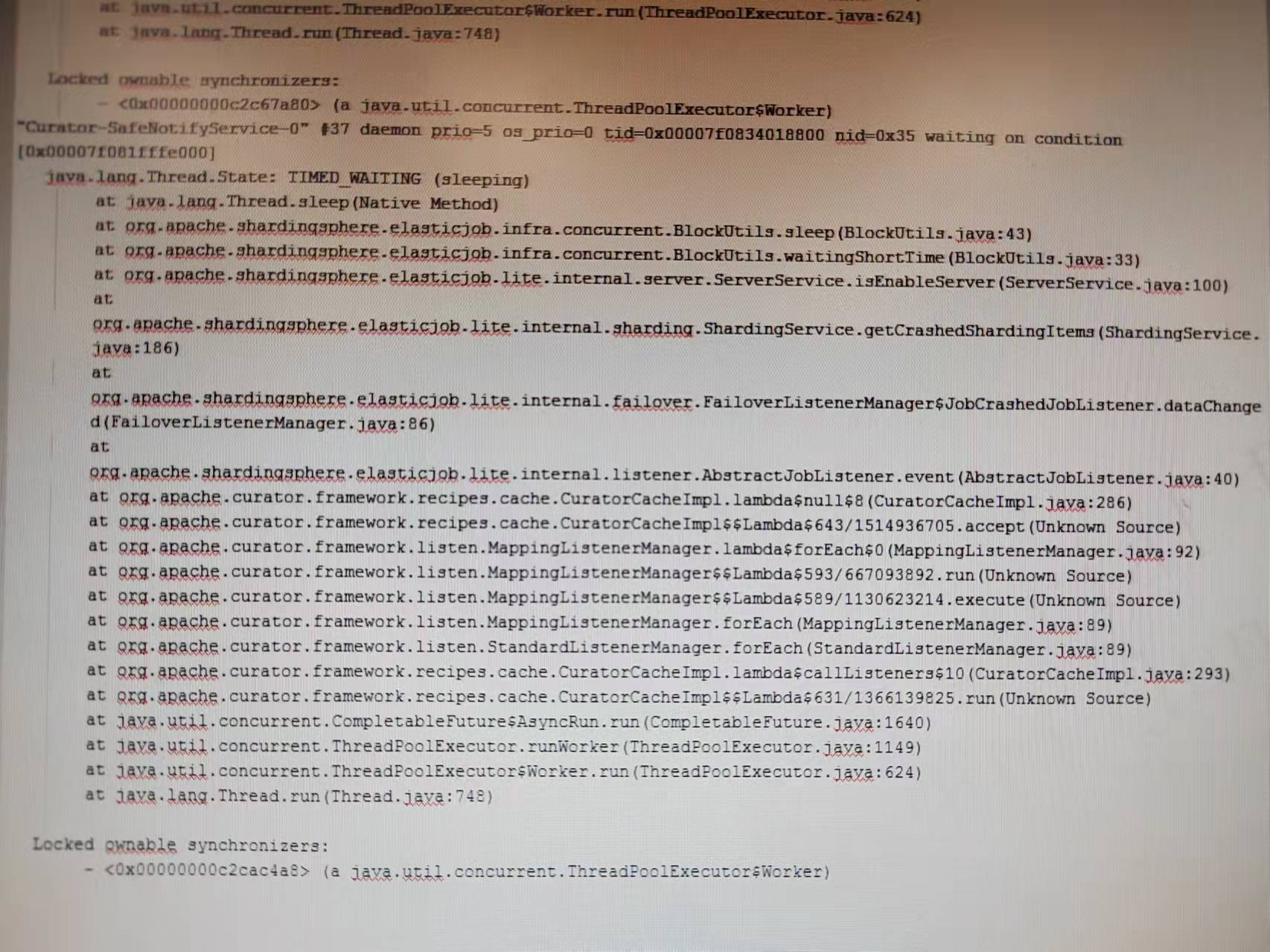 I found that the "Curator-SafeNotifyService-0" thread always stuck here, falling into endless loop at ServerService.isEnableServer(): public boolean isEnableServer(final String ip) { String serverStatus = jobNodeStorage.getJobNodeData(serverNode.getServerNode(ip)); **//Endless loop happend! while (Strings.isNullOrEmpty(serverStatus)) { BlockUtils.waitingShortTime(); serverStatus = jobNodeStorage.getJobNodeData(serverNode.getServerNode(ip)); }** return !ServerStatus.DISABLED.name().equals(serverStatus); } Reason found: It's because our application was runing on cloud-native architechture, and we found that the servers node's children become more and more with the container(pod) being destroyed and created again and again. So I registered a shutdownHook when the container is created, which would remove the instance's server node under servers node from zookeeper when the container is destroyed by calling JobOperateAPI's remove method. It caused this issue because when container was destroyed, the instance gone down and JobCrashedJobListener will be triggered, and the listener will fall into the endless loop as mentioned above if the instance’s server node was deleted. All shards would not be triggered if the leader node‘s "Curator-SafeNotifyService-0" thread fall into the endless loop because only the leader node can do resharding, and all the listeners are triggered by the same thread(This maybe another issue.). But if the leader node didn’t fall into the endless loop, resharding will success and we would see that some shards are trigged successfully but those whose instance fell into the endless loop are not, just like the issue. But we do need to solve the problem of server nodes becoming more and more under servers node, so before delete the server node, we sleep some time longer than sessionTimeout to ensure that all the alive instances have finished JobCrashedJobListener to avoid "Curator-SafeNotifyService-0" thread falling into the endless loop. And I’m not sure if we can call addListener(listener, executor) instead of addListener(listener) to register listeners in JobNodeStorage’s addDataListener method: public void addDataListener(final CuratorCacheListener listener) { CuratorCache cache = (CuratorCache) regCenter.getRawCache("/" + jobName); **//Maybe we can call addListener(listener, executor) instead of addListener(listener) at here? cache.listenable().addListener(listener);** } -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}
{kind=link}