This is an automated email from the ASF dual-hosted git repository.
zhangliang pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/shardingsphere.git
The following commit(s) were added to refs/heads/master by this push:
new 02f077f Improve unreasonable formatting in documents (#16223)
02f077f is described below
commit 02f077f2d7c4b99c345fbf35947235330fcd0646
Author: 龙台 Long Tai <[email protected]>
AuthorDate: Mon Mar 21 00:45:18 2022 +0800
Improve unreasonable formatting in documents (#16223)
---
.../document/content/concepts/adaptor/_index.cn.md | 4 +--
docs/document/content/dev-manual/scaling.cn.md | 2 +-
docs/document/content/features/ha/use-norms.cn.md | 4 +--
.../content/features/observability/concept.cn.md | 2 +-
.../content/features/transaction/_index.cn.md | 2 +-
.../shardingsphere-jdbc/yaml-configuration.cn.md | 6 ++--
.../content/reference/encrypt/_index.cn.md | 32 +++++++++++-----------
.../content/reference/management/_index.cn.md | 2 +-
.../content/reference/sharding/execute.cn.md | 2 +-
.../content/reference/sharding/parse.cn.md | 2 +-
.../content/reference/sharding/route.cn.md | 2 +-
.../reference/test/integration-test/_index.cn.md | 8 +++---
.../reference/test/module-test/parser-test.cn.md | 4 +--
.../reference/test/module-test/rewrite-test.cn.md | 8 +++---
.../test/performance-test/performance-test.cn.md | 8 +++---
.../shardingsphere-jdbc/java-api/rules/ha.cn.md | 2 +-
.../observability/apm-integration.cn.md | 2 +-
.../special-api/sharding/hint.cn.md | 6 ++--
.../special-api/transaction/_index.cn.md | 2 +-
.../special-api/transaction/atomikos.cn.md | 4 +--
.../special-api/transaction/seata.cn.md | 2 +-
.../spring-boot-starter/rules/ha.cn.md | 2 +-
.../spring-boot-starter/rules/mix.cn.md | 2 +-
.../rules/readwrite-splitting.cn.md | 2 +-
.../spring-namespace/rules/ha.cn.md | 2 +-
.../shardingsphere-jdbc/yaml-config/rules/ha.cn.md | 2 +-
.../yaml-config/rules/readwrite-splitting.cn.md | 2 +-
.../yaml-config/rules/sharding.cn.md | 2 +-
.../user-manual/shardingsphere-scaling/build.cn.md | 2 +-
.../user-manual/shardingsphere-scaling/usage.cn.md | 4 +--
.../shardingsphere-sidecar/_index.cn.md | 4 +--
31 files changed, 65 insertions(+), 65 deletions(-)
diff --git a/docs/document/content/concepts/adaptor/_index.cn.md
b/docs/document/content/concepts/adaptor/_index.cn.md
index a6834e0..632058a 100644
--- a/docs/document/content/concepts/adaptor/_index.cn.md
+++ b/docs/document/content/concepts/adaptor/_index.cn.md
@@ -24,7 +24,7 @@ ShardingSphere-JDBC 是 Apache ShardingSphere 的第一个产品,也是 Apache
| --------- | --------------------- | ---------------------- |
| 数据库 | `任意` | MySQL/PostgreSQL |
| 连接消耗数 | `高` | 低 |
-| 异构语言 | `仅Java` | 任意 |
+| 异构语言 | `仅 Java` | 任意 |
| 性能 | `损耗低` | 损耗略高 |
| 无中心化 | `是` | 否 |
| 静态入口 | `无` | 有 |
@@ -46,7 +46,7 @@ ShardingSphere-Proxy 是 Apache ShardingSphere 的第二个产品。
| --------- | --------------------- | ----------------------- |
| 数据库 | 任意 | `MySQL/PostgreSQL` |
| 连接消耗数 | 高 | `低` |
-| 异构语言 | 仅Java | `任意` |
+| 异构语言 | 仅 Java | `任意` |
| 性能 | 损耗低 | `损耗略高` |
| 无中心化 | 是 | `否` |
| 静态入口 | 无 | `有` |
diff --git a/docs/document/content/dev-manual/scaling.cn.md
b/docs/document/content/dev-manual/scaling.cn.md
index c14f8da..74e2ee4 100644
--- a/docs/document/content/dev-manual/scaling.cn.md
+++ b/docs/document/content/dev-manual/scaling.cn.md
@@ -47,4 +47,4 @@ chapter = true
| *已知实现类* | *详细说明*
|
| ------------------------------------------- |
---------------------------------------------------------------------- |
| DataMatchSingleTableDataCalculator | 给 DATA_MATCH
数据一致性校验算法使用的单表数据计算算法。适用于所有数据库。 |
-| CRC32MatchMySQLSingleTableDataCalculator | 给 CRC32_MATCH
数据一致性校验算法使用的单表数据计算算法。适用于MySQL。 |
+| CRC32MatchMySQLSingleTableDataCalculator | 给 CRC32_MATCH
数据一致性校验算法使用的单表数据计算算法。适用于 MySQL。 |
diff --git a/docs/document/content/features/ha/use-norms.cn.md
b/docs/document/content/features/ha/use-norms.cn.md
index f892b0e..c06b372 100644
--- a/docs/document/content/features/ha/use-norms.cn.md
+++ b/docs/document/content/features/ha/use-norms.cn.md
@@ -5,9 +5,9 @@ weight = 2
## 支持项
-* MySQL MGR 单主模式.
+* MySQL MGR 单主模式。
## 不支持项
-* MySQL MGR 多主模式.
+* MySQL MGR 多主模式。
diff --git a/docs/document/content/features/observability/concept.cn.md
b/docs/document/content/features/observability/concept.cn.md
index 71f2668..6ce6d27 100644
--- a/docs/document/content/features/observability/concept.cn.md
+++ b/docs/document/content/features/observability/concept.cn.md
@@ -5,7 +5,7 @@ weight = 1
## 代理
-基于字节码增强和插件化设计,以提供 tracing 和 metrics 埋点,以及日志输出功能。
+基于字节码增强和插件化设计,以提供 Tracing 和 Metrics 埋点,以及日志输出功能。
需要开启代理的插件功能后,才能将监控指标数据输出至第三方 APM 中展示。
## APM
diff --git a/docs/document/content/features/transaction/_index.cn.md
b/docs/document/content/features/transaction/_index.cn.md
index a8867e7..af60659 100644
--- a/docs/document/content/features/transaction/_index.cn.md
+++ b/docs/document/content/features/transaction/_index.cn.md
@@ -30,7 +30,7 @@ chapter = true
### 两阶段提交
-XA协议最早的分布式事务模型是由 `X/Open` 国际联盟提出的 `X/Open Distributed Transaction Processing
(DTP)` 模型,简称 XA 协议。
+XA 协议最早的分布式事务模型是由 `X/Open` 国际联盟提出的 `X/Open Distributed Transaction Processing
(DTP)` 模型,简称 XA 协议。
基于 XA 协议实现的分布式事务对业务侵入很小。
它最大的优势就是对使用方透明,用户可以像使用本地事务一样使用基于XA协议的分布式事务。
diff --git
a/docs/document/content/reference/api-change-history/shardingsphere-jdbc/yaml-configuration.cn.md
b/docs/document/content/reference/api-change-history/shardingsphere-jdbc/yaml-configuration.cn.md
index a0a862c..268eec7 100644
---
a/docs/document/content/reference/api-change-history/shardingsphere-jdbc/yaml-configuration.cn.md
+++
b/docs/document/content/reference/api-change-history/shardingsphere-jdbc/yaml-configuration.cn.md
@@ -16,7 +16,7 @@ rules:
- !SHARDING
tables: # 数据分片规则配置
<logic-table-name> (+): # 逻辑表名称
- actualDataNodes (?): # 由数据源名 + 表名组成(参考Inline语法规则)
+ actualDataNodes (?): # 由数据源名 + 表名组成(参考 Inline 语法规则)
databaseStrategy (?): # 分库策略,缺省表示使用默认分库策略,以下的分片策略只能选其一
standard: # 用于单分片键的标准分片场景
shardingColumn: # 分片列名称
@@ -210,7 +210,7 @@ shardingRule:
defaultDataSourceName: # 未配置分片规则的表将通过默认数据源定位
defaultDatabaseStrategy: # 默认数据库分片策略,同分库策略
defaultTableStrategy: # 默认表分片策略,同分库策略
- defaultKeyGenerator: # 默认的主键生成算法 如果没有设置,默认为 SNOWFLAKE 算法
+ defaultKeyGenerator: # 默认的主键生成算法 如果没有设置,默认为 SNOWFLAKE 算法
type: # 默认自增列值生成器类型,缺省将使用
org.apache.shardingsphere.core.keygen.generator.impl.SnowflakeKeyGenerator。可使用用户自定义的列值生成器或选择内置类型:SNOWFLAKE/UUID
props:
<property-name>: # 自增列值生成器属性配置, 比如 SNOWFLAKE 算法的
max.tolerate.time.difference.milliseconds
@@ -388,7 +388,7 @@ shardingRule: # sharding 的配置
preciseShardingAlgorithm: # preciseShardingAlgorithm 接口的实现类
rangeShardingAlgorithm: # rangeShardingAlgorithm 接口的实现类
defaultTableStrategy: # 配置参考 defaultDatabaseShardingStrategy,区别在于,inline
算法的配置中,algorithmExpression 的配置算法结果需要是实际的物理表名称,而非数据源名称
- defaultKeyGenerator: # 默认的主键生成算法 如果没有设置,默认为 SNOWFLAKE 算法
+ defaultKeyGenerator: # 默认的主键生成算法 如果没有设置,默认为 SNOWFLAKE 算法
column: # 自增键对应的列名称
type: # 自增键的类型,主要用于调用内置的主键生成算法有三个可用值:SNOWFLAKE(时间戳 +worker id+ 自增
id),UUID(java.util.UUID 类生成的随机 UUID),LEAF,其中 Snowflake 算法与 UUID 算法已经实现,LEAF
目前(2018-01-14)尚未实现
className: # 非内置的其他实现了 KeyGenerator 接口的类,需要注意,如果设置这个,就不能设置 type,否则 type
的设置会覆盖 class 的设置
diff --git a/docs/document/content/reference/encrypt/_index.cn.md
b/docs/document/content/reference/encrypt/_index.cn.md
index df2b768..94f1bfb 100644
--- a/docs/document/content/reference/encrypt/_index.cn.md
+++ b/docs/document/content/reference/encrypt/_index.cn.md
@@ -31,7 +31,7 @@ Apache ShardingSphere 会将用户请求的明文进行加密后存储到底层
**加密表配置**:用于告诉 ShardingSphere
数据表里哪个列用于存储密文数据(cipherColumn)、哪个列用于存储明文数据(plainColumn)以及用户想使用哪个列进行 SQL
编写(logicColumn)。
-> 如何理解`用户想使用哪个列进行SQL编写(logicColumn)`?
+> 如何理解 `用户想使用哪个列进行 SQL 编写(logicColumn)`?
>
> 我们可以从加密模块存在的意义来理解。加密模块最终目的是希望屏蔽底层对数据的加密处理,也就是说我们不希望用户知道数据是如何被加解密的、如何将明文数据存储到
> plainColumn,将密文数据存储到 cipherColumn。
换句话说,我们不希望用户知道 plainColumn 和 cipherColumn 的存在和使用。
@@ -136,7 +136,7 @@ Apache ShardingSphere 接收到该 SQL,通过用户提供的加密配置,发
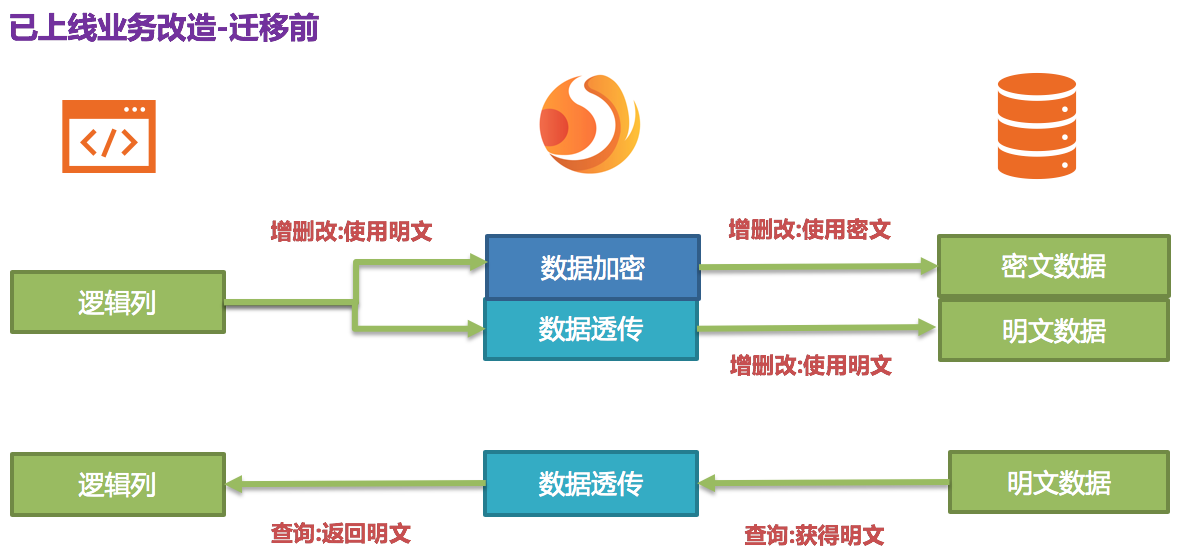
新增数据在插入时,就通过 Apache ShardingSphere 加密为密文数据,并被存储到了
cipherColumn。而现在就需要处理历史明文存量数据。
-**由于Apache ShardingSphere 目前并未提供相关迁移洗数工具,此时需要业务方自行将 `pwd` 中的明文数据进行加密处理存储到
`pwd_cipher`。**
+**由于 Apache ShardingSphere 目前并未提供相关迁移洗数工具,此时需要业务方自行将 `pwd` 中的明文数据进行加密处理存储到
`pwd_cipher`。**
2. 系统迁移中
@@ -157,7 +157,7 @@ Apache ShardingSphere 接收到该 SQL,通过用户提供的加密配置,发
3. 系统迁移后
由于安全审计部门要求,业务系统一般不可能让数据库的明文列和密文列永久同步保留,我们需要在系统稳定后将明文列数据删除。
-即我们需要在系统迁移后将 plainColumn,即pwd进行删除。那问题来了,现在业务代码都是面向pwd进行编写 SQL 的,把底层数据表中的存放明文的
pwd 删除了,
+即我们需要在系统迁移后将 plainColumn,即 pwd 进行删除。那问题来了,现在业务代码都是面向pwd进行编写 SQL
的,把底层数据表中的存放明文的 pwd 删除了,
换用 pwd_cipher 进行解密得到原文数据,那岂不是意味着业务方需要整改所有 SQL,从而不使用即将要被删除的 pwd 列?还记得我们 Apache
ShardingSphere 的核心意义所在吗?
> 这也正是 Apache ShardingSphere 核心意义所在,即依据用户提供的加密规则,将用户 SQL
> 与底层数据库表结构割裂开来,使得用户的SQL编写不再依赖于真实的数据库表结构。
@@ -190,7 +190,7 @@ Apache ShardingSphere 接收到该 SQL,通过用户提供的加密配置,发
## 中间件加密服务优势
1. 自动化&透明化数据加密过程,用户无需关注加密中间实现细节。
-2. 提供多种内置、第三方(AKS)的加密算法,用户仅需简单配置即可使用。
+2. 提供多种内置、第三方(AKS)的加密算法,用户仅需简单配置即可使用。
3. 提供加密算法 API 接口,用户可实现接口,从而使用自定义加密算法进行数据加密。
4. 支持切换不同的加密算法。
5. 针对已上线业务,可实现明文数据与密文数据同步存储,并通过配置决定使用明文列还是密文列进行查询。可实现在不改变业务查询 SQL
前提下,已上线系统对加密前后数据进行安全、透明化迁移。
@@ -205,26 +205,26 @@ Apache ShardingSphere 提供了两种加密算法用于数据加密,这两种
### EncryptAlgorithm
-该解决方案通过提供`encrypt()`, `decrypt()`两种方法对需要加密的数据进行加解密。
-在用户进行`INSERT`, `DELETE`,
`UPDATE`时,ShardingSphere会按照用户配置,对SQL进行解析、改写、路由,并调用`encrypt()`将数据加密后存储到数据库,
-而在`SELECT`时,则调用`decrypt()`方法将从数据库中取出的加密数据进行逆向解密,最终将原始数据返回给用户。
+该解决方案通过提供 `encrypt()`, `decrypt()` 两种方法对需要加密的数据进行加解密。
+在用户进行 `INSERT`, `DELETE`, `UPDATE` 时,ShardingSphere会按照用户配置,对SQL进行解析、改写、路由,并调用
`encrypt()` 将数据加密后存储到数据库,
+而在 `SELECT` 时,则调用 `decrypt()` 方法将从数据库中取出的加密数据进行逆向解密,最终将原始数据返回给用户。
-当前,Apache ShardingSphere 针对这种类型的加密解决方案提供了三种具体实现类,分别是
MD5(不可逆),AES(可逆),RC4(可逆),用户只需配置即可使用这三种内置的方案。
+当前,Apache ShardingSphere 针对这种类型的加密解决方案提供了三种具体实现类,分别是
MD5(不可逆),AES(可逆),RC4(可逆),用户只需配置即可使用这三种内置的方案。
### QueryAssistedEncryptAlgorithm
相比较于第一种加密方案,该方案更为安全和复杂。它的理念是:即使是相同的数据,如两个用户的密码相同,它们在数据库里存储的加密数据也应当是不一样的。这种理念更有利于保护用户信息,防止撞库成功。
-它提供三种函数进行实现,分别是`encrypt()`, `decrypt()`,
`queryAssistedEncrypt()`。在`encrypt()`阶段,用户通过设置某个变动种子,例如时间戳。
-针对原始数据+变动种子组合的内容进行加密,就能保证即使原始数据相同,也因为有变动种子的存在,致使加密后的加密数据是不一样的。在`decrypt()`可依据之前规定的加密算法,利用种子数据进行解密。
+它提供三种函数进行实现,分别是 `encrypt()`, `decrypt()`, `queryAssistedEncrypt()`。在
`encrypt()` 阶段,用户通过设置某个变动种子,例如时间戳。
+针对原始数据+变动种子组合的内容进行加密,就能保证即使原始数据相同,也因为有变动种子的存在,致使加密后的加密数据是不一样的。在 `decrypt()`
可依据之前规定的加密算法,利用种子数据进行解密。
-虽然这种方式确实可以增加数据的保密性,但是另一个问题却随之出现:相同的数据在数据库里存储的内容是不一样的,那么当用户按照这个加密列进行等值查询(`SELECT
FROM table WHERE encryptedColumnn = ?`)时会发现无法将所有相同的原始数据查询出来。
+虽然这种方式确实可以增加数据的保密性,但是另一个问题却随之出现:相同的数据在数据库里存储的内容是不一样的,那么当用户按照这个加密列进行等值查询(`SELECT
FROM table WHERE encryptedColumnn = ?`)时会发现无法将所有相同的原始数据查询出来。
为此,我们提出了辅助查询列的概念。
-该辅助查询列通过`queryAssistedEncrypt()`生成,与`decrypt()`不同的是,该方法通过对原始数据进行另一种方式的加密,但是针对原始数据相同的数据,这种加密方式产生的加密数据是一致的。
-将`queryAssistedEncrypt()`后的数据存储到数据中用于辅助查询真实数据。因此,数据库表中多出这一个辅助查询列。
+该辅助查询列通过 `queryAssistedEncrypt()` 生成,与 `decrypt()`
不同的是,该方法通过对原始数据进行另一种方式的加密,但是针对原始数据相同的数据,这种加密方式产生的加密数据是一致的。
+将 `queryAssistedEncrypt()` 后的数据存储到数据中用于辅助查询真实数据。因此,数据库表中多出这一个辅助查询列。
-由于`queryAssistedEncrypt()`和`encrypt()`产生不同加密数据进行存储,而`decrypt()`可逆,`queryAssistedEncrypt()`不可逆。
-在查询原始数据的时候,我们会自动对SQL进行解析、改写、路由,利用辅助查询列进行`WHERE`条件的查询,却利用
`decrypt()`对`encrypt()`加密后的数据进行解密,并将原始数据返回给用户。
+由于 `queryAssistedEncrypt()` 和 `encrypt()` 产生不同加密数据进行存储,而 `decrypt()`
可逆,`queryAssistedEncrypt()` 不可逆。
+在查询原始数据的时候,我们会自动对SQL进行解析、改写、路由,利用辅助查询列进行 `WHERE` 条件的查询,却利用 `decrypt()` 对
`encrypt()` 加密后的数据进行解密,并将原始数据返回给用户。
这一切都是对用户透明化的。
-当前,Apache ShardingSphere
针对这种类型的加密解决方案并没有提供具体实现类,却将该理念抽象成接口,提供给用户自行实现。ShardingSphere将调用用户提供的该方案的具体实现类进行数据加密。
+当前,Apache ShardingSphere
针对这种类型的加密解决方案并没有提供具体实现类,却将该理念抽象成接口,提供给用户自行实现。ShardingSphere
将调用用户提供的该方案的具体实现类进行数据加密。
diff --git a/docs/document/content/reference/management/_index.cn.md
b/docs/document/content/reference/management/_index.cn.md
index 3b1a8e9..bea04fe 100644
--- a/docs/document/content/reference/management/_index.cn.md
+++ b/docs/document/content/reference/management/_index.cn.md
@@ -76,7 +76,7 @@ sql-show: true
### /metadata/${schemaName}/dataSources
-多个数据库连接池的集合,不同数据库连接池属性自适配(例如:DBCP,C3P0,Druid, HikariCP)。
+多个数据库连接池的集合,不同数据库连接池属性自适配(例如:DBCP,C3P0,Druid,HikariCP)。
```yaml
ds_0:
diff --git a/docs/document/content/reference/sharding/execute.cn.md
b/docs/document/content/reference/sharding/execute.cn.md
index 03e9b5b..6cb859f 100644
--- a/docs/document/content/reference/sharding/execute.cn.md
+++ b/docs/document/content/reference/sharding/execute.cn.md
@@ -95,7 +95,7 @@ ShardingSphere 为了避免死锁的出现,在获取数据库连接时进行
它在创建执行单元时,以原子性的方式一次性获取本次 SQL 请求所需的全部数据库连接,杜绝了每次查询请求获取到部分资源的可能。
由于对数据库的操作非常频繁,每次获取数据库连接时时都进行锁定,会降低 ShardingSphere 的并发。因此,ShardingSphere 在这里进行了
2 点优化:
-1. 避免锁定一次性只需要获取1个数据库连接的操作。因为每次仅需要获取 1 个连接,则不会发生两个请求相互等待的场景,无需锁定。
+1. 避免锁定一次性只需要获取 1 个数据库连接的操作。因为每次仅需要获取 1 个连接,则不会发生两个请求相互等待的场景,无需锁定。
对于大部分 OLTP 的操作,都是使用分片键路由至唯一的数据节点,这会使得系统变为完全无锁的状态,进一步提升了并发效率。
除了路由至单分片的情况,读写分离也在此范畴之内。
diff --git a/docs/document/content/reference/sharding/parse.cn.md
b/docs/document/content/reference/sharding/parse.cn.md
index f466f28..28e645d 100644
--- a/docs/document/content/reference/sharding/parse.cn.md
+++ b/docs/document/content/reference/sharding/parse.cn.md
@@ -42,7 +42,7 @@ ShardingSphere 的 SQL 解析器经历了 3 代产品的更新迭代。
由于目的不同,ShardingSphere 并不需要将 SQL 转为一颗完全的抽象语法树,也无需通过访问器模式进行二次遍历。它采用对 SQL
`半理解`的方式,仅提炼数据分片需要关注的上下文,因此 SQL 解析的性能和兼容性得到了进一步的提高。
第三代 SQL 解析器从 3.0.x 版本开始,尝试使用 ANTLR 作为 SQL 解析引擎的生成器,并采用 Visit 的方式从 AST 中获取 SQL
Statement。从 5.0.x 版本开始,解析引擎的架构已完成重构调整,
-同时通过将第一次解析得到的 AST 放入缓存,方便下次直接获取相同 SQL的解析结果,来提高解析效率。 因此我们建议用户采用
`PreparedStatement` 这种 SQL 预编译的方式来提升性能。
+同时通过将第一次解析得到的 AST 放入缓存,方便下次直接获取相同 SQL 的解析结果,来提高解析效率。因此我们建议用户采用
`PreparedStatement` 这种 SQL 预编译的方式来提升性能。
### 功能点
diff --git a/docs/document/content/reference/sharding/route.cn.md
b/docs/document/content/reference/sharding/route.cn.md
index 70700aa..b73afad 100644
--- a/docs/document/content/reference/sharding/route.cn.md
+++ b/docs/document/content/reference/sharding/route.cn.md
@@ -4,7 +4,7 @@ weight = 2
+++
根据解析上下文匹配数据库和表的分片策略,并生成路由路径。
-对于携带分片键的 SQL,根据分片键的不同可以划分为单片路由(分片键的操作符是等号)、多片路由(分片键的操作符是 IN)和范围路由(分片键的操作符是
BETWEEN)。
+对于携带分片键的 SQL,根据分片键的不同可以划分为单片路由(分片键的操作符是等号)、多片路由(分片键的操作符是 IN)和范围路由(分片键的操作符是
BETWEEN)。
不携带分片键的 SQL 则采用广播路由。
分片策略通常可以采用由数据库内置或由用户方配置。
diff --git a/docs/document/content/reference/test/integration-test/_index.cn.md
b/docs/document/content/reference/test/integration-test/_index.cn.md
index c964d33..31d9dc3 100644
--- a/docs/document/content/reference/test/integration-test/_index.cn.md
+++ b/docs/document/content/reference/test/integration-test/_index.cn.md
@@ -37,15 +37,15 @@ weight = 1
测试引擎通过将用例和环境进行排列组合,以达到用最少的用例测试尽可能多场景的目的。
-每条 SQL 会以`数据库类型 * 接入端类型 * SQL 执行模式 * JDBC 执行模式 * 场景`的组合方式生成测试报告,目前各个维度的支持情况如下:
+每条 SQL 会以 `数据库类型 * 接入端类型 * SQL 执行模式 * JDBC 执行模式 * 场景`
的组合方式生成测试报告,目前各个维度的支持情况如下:
- 数据库类型:H2、MySQL、PostgreSQL、SQLServer 和 Oracle;
- 接入端类型:ShardingSphere-JDBC 和 ShardingSphere-Proxy;
- SQL 执行模式:Statement 和 PreparedStatement;
- - JDBC 执行模式:execute 和 executeQuery (查询) / executeUpdate (更新);
+ - JDBC 执行模式:execute 和 executeQuery(查询) / executeUpdate(更新);
- 场景:分库、分表、读写分离和分库分表 + 读写分离。
-因此,1 条 SQL 会驱动:`数据库类型(5) * 接入端类型(2) * SQL 执行模式(2) * JDBC 执行模式(2) * 场景(4) =
160` 个测试用例运行,以达到项目对于高质量的追求。
+因此,1 条 SQL 会驱动:`数据库类型(5) * 接入端类型(2) * SQL 执行模式(2) * JDBC 执行模式(2) * 场景(4) =
160` 个测试用例运行,以达到项目对于高质量的追求。
## 使用指南
@@ -113,7 +113,7 @@ SQL 用例在
`resources/cases/${SQL-TYPE}/${SQL-TYPE}-integration-test-cases.xm
- `docker-compose.yml`: Docker-Compose 配置文件,用于 Docker 环境启动
- `proxy/conf/config-${SCENARIO-TYPE}.yaml`: 规则配置
-**Docker 环境配置为 ShardingSphere-Proxy 提供了远程调试端口,可以在 `docker-compose.yml` 文件的
`shardingsphere-proxy`中找到第 2 个暴露的端口用于远程调试。**
+**Docker 环境配置为 ShardingSphere-Proxy 提供了远程调试端口,可以在 `docker-compose.yml` 文件的
`shardingsphere-proxy` 中找到第 2 个暴露的端口用于远程调试。**
### 运行测试引擎
diff --git a/docs/document/content/reference/test/module-test/parser-test.cn.md
b/docs/document/content/reference/test/module-test/parser-test.cn.md
index 4175db7..c657857 100644
--- a/docs/document/content/reference/test/module-test/parser-test.cn.md
+++ b/docs/document/content/reference/test/module-test/parser-test.cn.md
@@ -9,12 +9,12 @@ SQL 解析无需真实的测试环境,开发者只需定义好待测试的 SQL
### SQL数据
-在集成测试的部分提到过`sql-case-id`,其对应的SQL,可以在不同模块共享。开发者只需要在`shardingsphere-sql-parser/shardingsphere-sql-parser-test/src/main/resources/sql/supported/${SQL-TYPE}/*.xml`
添加待测试的 SQL 即可。
+在集成测试的部分提到过 `sql-case-id`,其对应的 SQL,可以在不同模块共享。开发者只需要在
`shardingsphere-sql-parser/shardingsphere-sql-parser-test/src/main/resources/sql/supported/${SQL-TYPE}/*.xml`
添加待测试的 SQL 即可。
### 断言数据
断言的解析数据保存在
`shardingsphere-sql-parser/shardingsphere-sql-parser-test/src/main/resources/case/${SQL-TYPE}/*.xml`
-在`xml`文件中,可以针对表名,token,SQL条件等进行断言,例如如下的配置:
+在 `xml` 文件中,可以针对表名,token,SQL 条件等进行断言,例如如下的配置:
```xml
<parser-result-sets>
diff --git
a/docs/document/content/reference/test/module-test/rewrite-test.cn.md
b/docs/document/content/reference/test/module-test/rewrite-test.cn.md
index 73778f1..9515cb4 100644
--- a/docs/document/content/reference/test/module-test/rewrite-test.cn.md
+++ b/docs/document/content/reference/test/module-test/rewrite-test.cn.md
@@ -5,7 +5,7 @@ weight = 2
## 目标
-面向逻辑库与逻辑表书写的SQL,并不能够直接在真实的数据库中执行,SQL 改写用于将逻辑 SQL 改写为在真实数据库中可以正确执行的 SQL。
它包括正确性改写和优化改写两部分,所以 SQL 改写的测试都是基于这些改写方向进行校验的。
+面向逻辑库与逻辑表书写的 SQL,并不能够直接在真实的数据库中执行,SQL 改写用于将逻辑 SQL 改写为在真实数据库中可以正确执行的
SQL。它包括正确性改写和优化改写两部分,所以 SQL 改写的测试都是基于这些改写方向进行校验的。
### 测试
@@ -17,7 +17,7 @@ SQL 改写测试用例位于 `sharding-core/sharding-core-rewrite` 下的 test
测试引擎是 SQL 改写测试的入口,跟其他引擎一样,通过 Junit 的
[Parameterized](https://github.com/junit-team/junit4/wiki/Parameterized-tests)
逐条读取 `test\resources` 目录中测试类型下对应的 xml 文件,然后按读取顺序一一进行验证。
-环境配置存放在 `test\resources\yaml` 路径中测试类型下对应的 yaml
中。配置了dataSources,shardingRule,encryptRule 等信息,例子如下:
+环境配置存放在 `test\resources\yaml` 路径中测试类型下对应的 yaml 中。配置了
dataSources,shardingRule,encryptRule 等信息,例子如下:
```yaml
dataSources:
@@ -62,8 +62,8 @@ rules:
type: SNOWFLAKE
```
-验证数据存放在 `test\resources` 路径中测试类型下对应的 xml 文件中。验证数据中, `yaml-rule` 指定了环境以及 rule
的配置文件,`input` 指定了待测试的 SQL 以及参数,`output` 指定了期待的 SQL 以及参数。
-其中 `db-type` 决定了 SQL 解析的类型,默认为 `SQL92`, 例如:
+验证数据存放在 `test\resources` 路径中测试类型下对应的 xml 文件中。验证数据中,`yaml-rule` 指定了环境以及 rule
的配置文件,`input` 指定了待测试的 SQL 以及参数,`output` 指定了期待的 SQL 以及参数。
+其中 `db-type` 决定了 SQL 解析的类型,默认为 `SQL92`,例如:
```xml
<rewrite-assertions yaml-rule="yaml/sharding/sharding-rule.yaml">
diff --git
a/docs/document/content/reference/test/performance-test/performance-test.cn.md
b/docs/document/content/reference/test/performance-test/performance-test.cn.md
index feea12d..0010e57 100644
---
a/docs/document/content/reference/test/performance-test/performance-test.cn.md
+++
b/docs/document/content/reference/test/performance-test/performance-test.cn.md
@@ -12,7 +12,7 @@ weight = 1
### 单路由
-在1000数据量的基础上分库分表,根据`id`分为4个库,部署在同一台机器上,根据`k`分为 1024 个表,查询操作路由到单库单表;
+在 1000 数据量的基础上分库分表,根据 `id` 分为 4 个库,部署在同一台机器上,根据 `k` 分为 1024 个表,查询操作路由到单库单表;
作为对比,MySQL 运行在 1000 数据量的基础上,使用 INSERT+UPDATE+DELETE 和单路由查询语句。
### 主从
@@ -22,12 +22,12 @@ weight = 1
### 主从+加密+分库分表
-在1000数据量的基础上,根据`id`分为4个库,部署在四台不同的机器上,根据 `k` 分为1024个表,`c` 使用 aes 加密,`pad` 使用
md5 加密,查询操作路由到单库单表;
-作为对比,MySQL 运行在1000数据量的基础上,使用 INSERT+UPDATE+DELETE 和单路由查询语句。
+在 1000 数据量的基础上,根据 `id` 分为 4 个库,部署在四台不同的机器上,根据 `k` 分为 1024 个表,`c` 使用 aes
加密,`pad` 使用 md5 加密,查询操作路由到单库单表;
+作为对比,MySQL 运行在 1000 数据量的基础上,使用 INSERT+UPDATE+DELETE 和单路由查询语句。
### 全路由
-在1000数据量的基础上,分库分表,根据`id`分为4个库,部署在四台不同的机器上,根据`k`分为1个表,查询操作使用全路由。
+在 1000 数据量的基础上,分库分表,根据 `id` 分为 4 个库,部署在四台不同的机器上,根据 `k` 分为 1 个表,查询操作使用全路由。
作为对比,MySQL 运行在 1000 数据量的基础上,使用 INSERT+UPDATE+DELETE 和全路由查询语句。
## 测试环境搭建
diff --git
a/docs/document/content/user-manual/shardingsphere-jdbc/java-api/rules/ha.cn.md
b/docs/document/content/user-manual/shardingsphere-jdbc/java-api/rules/ha.cn.md
index 0779cd1..d005cd1 100644
---
a/docs/document/content/user-manual/shardingsphere-jdbc/java-api/rules/ha.cn.md
+++
b/docs/document/content/user-manual/shardingsphere-jdbc/java-api/rules/ha.cn.md
@@ -44,5 +44,5 @@ weight = 3
| *名称* | *数据类型* | *说明*
| *默认值* |
| -------------------------- | -------------------- |
---------------------------------------------------------------------- |
------------- |
-| type (+) | String | 数据库发现类型,如: MGR、openGauss
| - |
+| type (+) | String | 数据库发现类型,如:MGR、openGauss
| - |
| props (?) | Properties | 数据库发现类型配置,如 MGR 的
group-name 属性配置 | - |
diff --git
a/docs/document/content/user-manual/shardingsphere-jdbc/special-api/observability/apm-integration.cn.md
b/docs/document/content/user-manual/shardingsphere-jdbc/special-api/observability/apm-integration.cn.md
index 3f2cbb4..ac6a8b1 100644
---
a/docs/document/content/user-manual/shardingsphere-jdbc/special-api/observability/apm-integration.cn.md
+++
b/docs/document/content/user-manual/shardingsphere-jdbc/special-api/observability/apm-integration.cn.md
@@ -35,7 +35,7 @@ ShardingTracer.init(new SkywalkingTracer());
### 使用 OpenTelemetry
-在agent.yaml中填写好配置即可,例如将 Traces 数据导出到 Zipkin。
+在 agent.yaml 中填写好配置即可,例如将 Traces 数据导出到 Zipkin。
```yaml
OpenTelemetry:
diff --git
a/docs/document/content/user-manual/shardingsphere-jdbc/special-api/sharding/hint.cn.md
b/docs/document/content/user-manual/shardingsphere-jdbc/special-api/sharding/hint.cn.md
index dadceee..1f8cdb8 100644
---
a/docs/document/content/user-manual/shardingsphere-jdbc/special-api/sharding/hint.cn.md
+++
b/docs/document/content/user-manual/shardingsphere-jdbc/special-api/sharding/hint.cn.md
@@ -135,7 +135,7 @@ try (HintManager hintManager = HintManager.getInstance();
##### 使用规范
SQL Hint 功能需要用户提前开启解析注释的配置,设置 `sqlCommentParseEnabled` 为 `true`。
-注释格式暂时只支持`/* */`,内容需要以`ShardingSphere hint:`开始,属性名为 `writeRouteOnly`。
+注释格式暂时只支持`/* */`,内容需要以 `ShardingSphere hint:`开始,属性名为 `writeRouteOnly`。
##### 完整示例
```sql
@@ -176,10 +176,10 @@ try (HintManager hintManager = HintManager.getInstance();
##### 使用规范
SQL Hint 功能需要用户提前开启解析注释的配置,设置 `sqlCommentParseEnabled` 为 `true`,目前只支持路由至一个数据源。
-注释格式暂时只支持`/* */`,内容需要以`ShardingSphere hint:`开始,属性名为 `dataSourceName`。
+注释格式暂时只支持`/* */`,内容需要以 `ShardingSphere hint:`开始,属性名为 `dataSourceName`。
##### 完整示例
```sql
/* ShardingSphere hint: dataSourceName=ds_0 */
SELECT * FROM t_order;
-```
\ No newline at end of file
+```
diff --git
a/docs/document/content/user-manual/shardingsphere-jdbc/special-api/transaction/_index.cn.md
b/docs/document/content/user-manual/shardingsphere-jdbc/special-api/transaction/_index.cn.md
index 9ba46f5..81a0b2a 100644
---
a/docs/document/content/user-manual/shardingsphere-jdbc/special-api/transaction/_index.cn.md
+++
b/docs/document/content/user-manual/shardingsphere-jdbc/special-api/transaction/_index.cn.md
@@ -6,4 +6,4 @@ chapter = true
通过 Apache ShardingSphere 使用分布式事务,与本地事务并无区别。
除了透明化分布式事务的使用之外,Apache ShardingSphere 还能够在每次数据库访问时切换分布式事务类型。
-支持的事务类型包括 本地事务、XA 事务 和 柔性事务。可在创建数据库连接之前设置,缺省为 Apache ShardingSphere 启动时的默认事务类型。
+支持的事务类型包括:本地事务、XA 事务和柔性事务。可在创建数据库连接之前设置,缺省为 Apache ShardingSphere 启动时的默认事务类型。
diff --git
a/docs/document/content/user-manual/shardingsphere-jdbc/special-api/transaction/atomikos.cn.md
b/docs/document/content/user-manual/shardingsphere-jdbc/special-api/transaction/atomikos.cn.md
index 23aa144..84539d8 100644
---
a/docs/document/content/user-manual/shardingsphere-jdbc/special-api/transaction/atomikos.cn.md
+++
b/docs/document/content/user-manual/shardingsphere-jdbc/special-api/transaction/atomikos.cn.md
@@ -7,10 +7,10 @@ Apache ShardingSphere 默认的 XA 事务管理器为 Atomikos。
## 数据恢复
-在项目的 `logs` 目录中会生成`xa_tx.log`, 这是 XA 崩溃恢复时所需的日志,请勿删除。
+在项目的 `logs` 目录中会生成 `xa_tx.log`, 这是 XA 崩溃恢复时所需的日志,请勿删除。
## 修改配置
可以通过在项目的 classpath 中添加 `jta.properties` 来定制化 Atomikos 配置项。
-详情请参见[Atomikos官方文档](https://www.atomikos.com/Documentation/JtaProperties)。
+详情请参见 [Atomikos 官方文档](https://www.atomikos.com/Documentation/JtaProperties)。
diff --git
a/docs/document/content/user-manual/shardingsphere-jdbc/special-api/transaction/seata.cn.md
b/docs/document/content/user-manual/shardingsphere-jdbc/special-api/transaction/seata.cn.md
index cb26d16..d2e7118 100644
---
a/docs/document/content/user-manual/shardingsphere-jdbc/special-api/transaction/seata.cn.md
+++
b/docs/document/content/user-manual/shardingsphere-jdbc/special-api/transaction/seata.cn.md
@@ -9,7 +9,7 @@ weight = 7
## 创建日志表
-在每一个分片数据库实例中执创建 `undo_log`表(以 MySQL 为例)。
+在每一个分片数据库实例中执创建 `undo_log` 表(以 MySQL 为例)。
```sql
CREATE TABLE IF NOT EXISTS `undo_log`
diff --git
a/docs/document/content/user-manual/shardingsphere-jdbc/spring-boot-starter/rules/ha.cn.md
b/docs/document/content/user-manual/shardingsphere-jdbc/spring-boot-starter/rules/ha.cn.md
index 8b43570..9a0c655 100644
---
a/docs/document/content/user-manual/shardingsphere-jdbc/spring-boot-starter/rules/ha.cn.md
+++
b/docs/document/content/user-manual/shardingsphere-jdbc/spring-boot-starter/rules/ha.cn.md
@@ -14,6 +14,6 @@
spring.shardingsphere.rules.database-discovery.data-sources.<database-discovery-
spring.shardingsphere.rules.database-discovery.discovery-heartbeats.<discovery-heartbeat-name>.props.keep-alive-cron=
# cron 表达式,如:'0/5 * * * * ?'
-spring.shardingsphere.rules.database-discovery.discovery-types.<discovery-type-name>.type=
# 数据库发现类型,如: MGR、openGauss
+spring.shardingsphere.rules.database-discovery.discovery-types.<discovery-type-name>.type=
# 数据库发现类型,如:MGR、openGauss
spring.shardingsphere.rules.database-discovery.discovery-types.<discovery-type-name>.props.group-name=
# 数据库发现类型必要参数,如 MGR 的 group-name
```
diff --git
a/docs/document/content/user-manual/shardingsphere-jdbc/spring-boot-starter/rules/mix.cn.md
b/docs/document/content/user-manual/shardingsphere-jdbc/spring-boot-starter/rules/mix.cn.md
index 908d6bc..b00c3ff 100644
---
a/docs/document/content/user-manual/shardingsphere-jdbc/spring-boot-starter/rules/mix.cn.md
+++
b/docs/document/content/user-manual/shardingsphere-jdbc/spring-boot-starter/rules/mix.cn.md
@@ -70,7 +70,7 @@
spring.shardingsphere.rules.sharding.tables.t_user.key-generate-strategy.key-gen
# 分片算法配置
spring.shardingsphere.rules.sharding.sharding-algorithms.default-database-strategy-inline.type=INLINE
-# 表达式`ds_$->{user_id % 2}` 枚举的数据源为读写分离配置的逻辑数据源名称
+# 表达式 `ds_$->{user_id % 2}` 枚举的数据源为读写分离配置的逻辑数据源名称
spring.shardingsphere.rules.sharding.sharding-algorithms.default-database-strategy-inline.algorithm-expression=ds_$->{user_id
% 2}
spring.shardingsphere.rules.sharding.sharding-algorithms.user-table-strategy-inline.type=INLINE
spring.shardingsphere.rules.sharding.sharding-algorithms.user-table-strategy-inline.algorithm-expression=t_user_$->{user_id
% 2}
diff --git
a/docs/document/content/user-manual/shardingsphere-jdbc/spring-boot-starter/rules/readwrite-splitting.cn.md
b/docs/document/content/user-manual/shardingsphere-jdbc/spring-boot-starter/rules/readwrite-splitting.cn.md
index 17bdee5..c63e2b7 100644
---
a/docs/document/content/user-manual/shardingsphere-jdbc/spring-boot-starter/rules/readwrite-splitting.cn.md
+++
b/docs/document/content/user-manual/shardingsphere-jdbc/spring-boot-starter/rules/readwrite-splitting.cn.md
@@ -9,7 +9,7 @@ weight = 2
spring.shardingsphere.datasource.names= # 省略数据源配置,请参考使用手册
spring.shardingsphere.rules.readwrite-splitting.data-sources.<readwrite-splitting-data-source-name>.type=
# 读写分离类型,如: Static,Dynamic
-spring.shardingsphere.rules.readwrite-splitting.data-sources.<readwrite-splitting-data-source-name>.props.auto-aware-data-source-name=
# 自动发现数据源名称(与数据库发现配合使用)
+spring.shardingsphere.rules.readwrite-splitting.data-sources.<readwrite-splitting-data-source-name>.props.auto-aware-data-source-name=
# 自动发现数据源名称(与数据库发现配合使用)
spring.shardingsphere.rules.readwrite-splitting.data-sources.<readwrite-splitting-data-source-name>.props.write-data-source-name=
# 写数据源名称
spring.shardingsphere.rules.readwrite-splitting.data-sources.<readwrite-splitting-data-source-name>.props.read-data-source-names=
# 读数据源名称,多个从数据源用逗号分隔
spring.shardingsphere.rules.readwrite-splitting.data-sources.<readwrite-splitting-data-source-name>.load-balancer-name=
# 负载均衡算法名称
diff --git
a/docs/document/content/user-manual/shardingsphere-jdbc/spring-namespace/rules/ha.cn.md
b/docs/document/content/user-manual/shardingsphere-jdbc/spring-namespace/rules/ha.cn.md
index f111f6f..0f068a7 100644
---
a/docs/document/content/user-manual/shardingsphere-jdbc/spring-namespace/rules/ha.cn.md
+++
b/docs/document/content/user-manual/shardingsphere-jdbc/spring-namespace/rules/ha.cn.md
@@ -36,5 +36,5 @@ weight = 3
| *名称* | *类型* | *说明* |
| --------- | ----- | ----------------------------------------- |
| id | 属性 | 数据库发现类型名称 |
-| type | 属性 | 数据库发现类型,如: MGR、openGauss |
+| type | 属性 | 数据库发现类型,如:MGR、openGauss |
| props (?) | 标签 | 数据库发现类型配置,如 MGR 的 group-name 属性配置 |
diff --git
a/docs/document/content/user-manual/shardingsphere-jdbc/yaml-config/rules/ha.cn.md
b/docs/document/content/user-manual/shardingsphere-jdbc/yaml-config/rules/ha.cn.md
index 1eaf563..9411895 100644
---
a/docs/document/content/user-manual/shardingsphere-jdbc/yaml-config/rules/ha.cn.md
+++
b/docs/document/content/user-manual/shardingsphere-jdbc/yaml-config/rules/ha.cn.md
@@ -25,7 +25,7 @@ rules:
# 数据库发现类型配置
discoveryTypes:
<discovery-type-name> (+): # 数据库发现类型名称
- type: # 数据库发现类型,如: MGR、openGauss
+ type: # 数据库发现类型,如:MGR、openGauss
props (?):
group-name: 92504d5b-6dec-11e8-91ea-246e9612aaf1 # 数据库发现类型必要参数,如 MGR 的
group-name
```
diff --git
a/docs/document/content/user-manual/shardingsphere-jdbc/yaml-config/rules/readwrite-splitting.cn.md
b/docs/document/content/user-manual/shardingsphere-jdbc/yaml-config/rules/readwrite-splitting.cn.md
index d08c3c5..1d7a71f 100644
---
a/docs/document/content/user-manual/shardingsphere-jdbc/yaml-config/rules/readwrite-splitting.cn.md
+++
b/docs/document/content/user-manual/shardingsphere-jdbc/yaml-config/rules/readwrite-splitting.cn.md
@@ -12,7 +12,7 @@ rules:
<data-source-name> (+): # 读写分离逻辑数据源名称
type: # 读写分离类型,比如:Static,Dynamic
props:
- auto-aware-data-source-name: # 自动发现数据源名称(与数据库发现配合使用)
+ auto-aware-data-source-name: # 自动发现数据源名称(与数据库发现配合使用)
write-data-source-name: # 写库数据源名称
read-data-source-names: # 读库数据源名称,多个从数据源用逗号分隔
loadBalancerName: # 负载均衡算法名称
diff --git
a/docs/document/content/user-manual/shardingsphere-jdbc/yaml-config/rules/sharding.cn.md
b/docs/document/content/user-manual/shardingsphere-jdbc/yaml-config/rules/sharding.cn.md
index d0b9dfd..0053c24 100644
---
a/docs/document/content/user-manual/shardingsphere-jdbc/yaml-config/rules/sharding.cn.md
+++
b/docs/document/content/user-manual/shardingsphere-jdbc/yaml-config/rules/sharding.cn.md
@@ -10,7 +10,7 @@ rules:
- !SHARDING
tables: # 数据分片规则配置
<logic-table-name> (+): # 逻辑表名称
- actualDataNodes (?): # 由数据源名 + 表名组成(参考Inline语法规则)
+ actualDataNodes (?): # 由数据源名 + 表名组成(参考 Inline 语法规则)
databaseStrategy (?): # 分库策略,缺省表示使用默认分库策略,以下的分片策略只能选其一
standard: # 用于单分片键的标准分片场景
shardingColumn: # 分片列名称
diff --git
a/docs/document/content/user-manual/shardingsphere-scaling/build.cn.md
b/docs/document/content/user-manual/shardingsphere-scaling/build.cn.md
index 6858084..444763d 100644
--- a/docs/document/content/user-manual/shardingsphere-scaling/build.cn.md
+++ b/docs/document/content/user-manual/shardingsphere-scaling/build.cn.md
@@ -20,7 +20,7 @@ mvn clean install -Dmaven.javadoc.skip=true
-Dcheckstyle.skip=true -Drat.skip=tr
> Scaling还是实验性质的功能,建议使用master分支最新版本,点击此处[下载每日构建版本](
> https://github.com/apache/shardingsphere#nightly-builds )
-2. 解压缩 proxy
发布包,修改配置文件`conf/config-sharding.yaml`。详情请参见[proxy启动手册](/cn/user-manual/shardingsphere-proxy/startup/bin/)。
+2. 解压缩 proxy 发布包,修改配置文件 `conf/config-sharding.yaml`。详情请参见 [proxy
启动手册](/cn/user-manual/shardingsphere-proxy/startup/bin/)。
3. 修改配置文件
`conf/server.yaml`,详情请参见[模式配置](/cn/user-manual/shardingsphere-jdbc/yaml-config/mode/)。
diff --git
a/docs/document/content/user-manual/shardingsphere-scaling/usage.cn.md
b/docs/document/content/user-manual/shardingsphere-scaling/usage.cn.md
index 459ec8c..32e3011 100644
--- a/docs/document/content/user-manual/shardingsphere-scaling/usage.cn.md
+++ b/docs/document/content/user-manual/shardingsphere-scaling/usage.cn.md
@@ -38,7 +38,7 @@ weight = 2
**注意**:
-还没开启`自动建表`的数据库需要手动创建分表。
+还没开启 `自动建表` 的数据库需要手动创建分表。
### 权限要求
#### MySQL
@@ -159,7 +159,7 @@ ADD RESOURCE ds_2 (
详情请参见 [RDL
#数据分片](/cn/user-manual/shardingsphere-proxy/distsql/syntax/rdl/rule-definition/sharding/)。
-`SHARDING TABLE RULE`支持 2 种类型:`TableRule`和`AutoTableRule`。以下是两种分片规则的对比:
+`SHARDING TABLE RULE` 支持 2 种类型:`TableRule`和`AutoTableRule`。以下是两种分片规则的对比:
| 类型 | AutoTableRule(自动分片) |
TableRule(自定义分片) |
| ----------- | ------------------------------------------------------------ |
------------------------------------------------------------ |
diff --git
a/docs/document/content/user-manual/shardingsphere-sidecar/_index.cn.md
b/docs/document/content/user-manual/shardingsphere-sidecar/_index.cn.md
index 32eb4b6..f010491 100644
--- a/docs/document/content/user-manual/shardingsphere-sidecar/_index.cn.md
+++ b/docs/document/content/user-manual/shardingsphere-sidecar/_index.cn.md
@@ -7,7 +7,7 @@ chapter = true
## 简介
-ShardingSphere-Sidecar 是 ShardingSphere 的第三个产品,目前仍然在`规划中`。
+ShardingSphere-Sidecar 是 ShardingSphere 的第三个产品,目前仍然在 `规划中`。
定位为 Kubernetes 或 Mesos 的云原生数据库代理,以 DaemonSet 的形式代理所有对数据库的访问。
通过无中心、零侵入的方案提供与数据库交互的的啮合层,即 Database Mesh,又可称数据网格。
@@ -21,7 +21,7 @@ Database Mesh 的关注重点在于如何将分布式的数据访问应用与数
| -------- | --------------------- | ---------------------- |
------------------------ |
| 数据库 | 任意 | MySQL/PostgreSQL | `MySQL/PostgreSQL`
|
| 连接消耗数 | 高 | 低 | `高`
|
-| 异构语言 | 仅Java | 任意 | `任意`
|
+| 异构语言 | 仅 Java | 任意 | `任意`
|
| 性能 | 损耗低 | 损耗略高 | `损耗低`
|
| 无中心化 | 是 | 否 | `是`
|
| 静态入口 | 无 | 有 | `无`
|
{kind=link}