This is an automated email from the ASF dual-hosted git repository.
wuweijie pushed a commit to branch master
in repository https://gitbox.apache.org/repos/asf/shardingsphere.git
The following commit(s) were added to refs/heads/master by this push:
new aff01a06f14 feat(blog): add new articles and images (#19801)
aff01a06f14 is described below
commit aff01a06f14e9f653d3ff2dce6cc2ba2eb62eed0
Author: Yumeiya <[email protected]>
AuthorDate: Thu Aug 4 15:41:03 2022 +0800
feat(blog): add new articles and images (#19801)
* add new blogs
* add new images
* Update
2022_05_24_Your_Guide_to_DistSQL_Cluster_Governance_Capability_Apache_ShardingSphere_Feature_Update.en.md
* delete images
* Revert "delete images"
This reverts commit dc5cc370c3210eb5adb817c74fd6630c6324a12d.
* Delete images
* Update
2022_05_17_How_does_Apache_ShardingSphere_implement_distributed_transactions.en.md
* Update
2022_05_24_Your_Guide_to_DistSQL_Cluster_Governance_Capability_Apache_ShardingSphere_Feature_Update.en.md
---
...concept_and_what_challenges_can_it_solve.en.md" | 175 ++++++++
...Sphere_implement_distributed_transactions.en.md | 277 +++++++++++++
...Transaction_Middle_Platform_Architecture.en.md" | 146 +++++++
...lity_Apache_ShardingSphere_Feature_Update.en.md | 449 +++++++++++++++++++++
4 files changed, 1047 insertions(+)
diff --git
"a/docs/blog/content/material/2022_05_10_What\342\200\231s_the_Database_Plus_concept_and_what_challenges_can_it_solve.en.md"
"b/docs/blog/content/material/2022_05_10_What\342\200\231s_the_Database_Plus_concept_and_what_challenges_can_it_solve.en.md"
new file mode 100644
index 00000000000..3176a55cc73
--- /dev/null
+++
"b/docs/blog/content/material/2022_05_10_What\342\200\231s_the_Database_Plus_concept_and_what_challenges_can_it_solve.en.md"
@@ -0,0 +1,175 @@
++++
+title = "What’s the Database Plus concept and what challenges can it solve?"
+weight = 54
+chapter = true
++++
+
+## Background
+
+For a long time, unification or fragmentation were the two most popular
predictions for the future of databases. With the advance of digitization, a
single scenario cannot meet the needs of diversified applications — making
database fragmentation an irreversible trend. While
[Oracle](https://www.oracle.com/index.html), the commercial database with the
largest market share, has no obvious weaknesses, all sorts of new databases are
still entering the market. Today, over [300 databases are [...]
+
+An increasing number of application scenarios has exacerbated database
fragmentation, making database architecture, protocols, functions, and
application scenarios increasingly diversified. In terms of database
architecture, the centralized database which is evolved from a single-machine
system coexists with the new generation of native distributed databases. In
terms of database protocols, [MySQL](https://www.mysql.com) and
[PostgreSQL](https://www.postgresql.org), two major open source [...]
+
+Today, it is normal for enterprises to leverage diversified databases. In my
market of expertise, China, in the Internet industry, MySQL together with data
sharding middleware is the go to architecture, with
[GreenPlum](https://greenplum.org), [HBase](https://hbase.apache.org),
[Elasticsearch](https://www.elastic.co/cn/),
[Clickhouse](https://clickhouse.com) and other big data ecosystems being
auxiliary computing engine for analytical data. At the same time, some legacy
systems (such as [...]
+
+When i claim that fragmentation is an irreversible trend for the database
field, i base my assumptions on the above trends. A single type of database can
only be applied to a certain (or a few scenarios at best)in which it excels.
+
+## Problems with database fragmentation
+
+With the increasing variety of databases used by enterprises, various problems
and pain points also arise.
+
+### 1. Difficulties in architecture selection
+
+To meet flexible business requirements, the application architecture can be
transformed from monolithic to service-oriented and then to
microservice-oriented. In this case, the database used to store the core data
becomes the focus of the distributed system.
+
+Compared with stateless applications, it is all the more difficult to design a
stateful database. Divide-and-conquer is the best practice for distributed
systems. Obviously, database systems cannot respond to all service requests
with a single product and an integrated cluster.
+
+**First of all, a single database category is unable to meet all kinds of
business application needs, while maintaining high throughput, low latency,
strong consistency, operation and maintenance efficiency, and even stability.**
It is less likely that a single application requires the coexistence of
multiple databases, but the likelihood of multiple applications requiring
multiple databases is much higher.
+
+
+
+**Secondly, no matter if we’re talking about standalone databases or
All-in-One distributed database clusters, it is difficult to become the only
storage support for the backend of many micro-service applications.**
Standalone databases cannot carry the increasing amount of data and traffic, so
more and more applications choose to adopt distributed solutions. However, if
multiple applications use a unified database cluster, the load on CPU, memory,
disks, and network cannot be completely [...]
+
+Today, most distributed databases are expensive to build, requiring backup and
redundant standalone servers at the compute node, storage node, and governance
nodes. Building an independent distributed database for each micro-service will
inevitably lead to unnecessary resource consumption and ultimately become
unsustainable for enterprises.
+
+
+
+**Finally, a large number of enterprises adopt a unitized architecture.**
Based on the data sharding solution, the split and unification of databases are
completed on the application side. As the number of databases increases, the
complexity of the architectural design increases exponentially. In the long
run, the dev team will be unable to focus on R&D, but will have to dedicate a
lot of energy to the maintenance of the underlying components. Although the
data sharding feature of [Apach [...]
+
+
+
+### 2. Numerous technical challenges
+
+When the coexistence of fragmented databases becomes the norm, the development
costs and learning curve for R&D teams will inevitably increase constantly.
Although most databases support SQL operation, there are still a lot of
differences between databases in terms of SQL dialects.
+
+If each database needs to be refined, it will take up a lot of energy of R&D
teams, and the accumulated knowledge and experience are hard to be passed on.
If we use the heterogeneous database with a coarse-grained standard model, it
will annihilate the characteristics of the database itself.
+
+### 3. High operation & maintenance complexity
+
+It takes a lot of time and practical experience to master the characteristics
of various databases and formulate effective operation and maintenance
specifications. In addition to the most basic operation and maintenance work,
the database peripheral supporting tools are also very different. Monitoring,
backup, and other automated operation and maintenance work composed of
peripheral supporting tools will incur substantial operation and maintenance
costs.
+
+### 4. Lack of collaboration and unified management among databases
+
+From the perspective of a database, its primary goal is to improve its own
capability instead of improving the online compatibility with other databases.
Features such as correlated queries and distributed transactions across
heterogeneous databases cannot be achieved within the database itself.
+
+Unlike the relatively standard SQL, the protocol of the database itself and
the peripheral ecosystem tools lack a unified standard. Increasing attention
has been dedicated to the unified management and control of heterogeneous
databases. Unfortunately, databases lack upper-level standards, so it is
difficult to effectively promote collaboration and unified management between
databases.
+
+## What is Database Plus?
+
+[Database Plus](https://shardingsphere.apache.org) is a design concept for
distributed database systems, designed to build an ecosystem on top of
fragmented heterogeneous databases. The goal is to provide globally scalable
and enhanced computing capabilities, while maximizing the original database
computing capabilities. The interaction between applications and databases
becomes oriented towards the Database Plus standard, therefore minimizing the
impact of database fragmentation on uppe [...]
+
+**Connect, Enhance and Pluggable** are the three keywords that define the core
values of Database Plus.
+
+### 1. Connect: building upper-level standards for databases
+Rather than providing an entirely new standard, Database Plus provides an
intermediate layer that can be adapted to a variety of SQL dialects and
database access protocols, providing an open interface to connect to various
databases.
+
+Thanks to the implementation of the Database access protocol, Database Plus
provides the same experience as a database and can support any development
language, and database access client.
+
+Moreover, Database Plus supports maximum conversion between SQL dialects. An
AST (abstract syntax tree) that parses SQL can be used to regenerate SQL
according to the rules of other database dialects. The SQL dialect conversion
makes it possible for heterogeneous databases to access each other. This way,
users can use any SQL dialect to access heterogeneous underlying databases.
+
+**Database gateway is the best interpretation of Connect. **It is the
prerequisite for Database Plus providing a solution for database fragmentation.
This is done by building a common open docking layer positioned in the upper
layer of the database, to pool all the access traffic of the fragmented
databases.
+
+### 2. Enhance: database computing enhancement engine
+Following decades of development, databases now boast their own query
optimizer, transaction engine, storage engine, and other time-tested storage
and computing capabilities and design models. With the advent of the
distributed and cloud native era, original computing and storage capabilities
of the database will be scattered and woven into a distributed and cloud native
level of new capabilities.
+
+Database Plus adopts a design philosophy that emphasizes traditional database
practices, while at the same time adapting to the new generation of distributed
databases. Whether centralized or distributed, Database Plus can repurpose and
enhance the storage and native computing capabilities of a database.
+The capabilities enhancement mainly refers to three aspects: distributed, data
control, and traffic control.
+
+Data fragmentation, elastic scaling, high availability, read/write spliting,
distributed transactions, and heterogeneous database federated queries based on
the vertical split are all capabilities that Database Plus can provide at the
global level for distributed heterogeneous databases. It doesn’t focus on the
database itself, but on the top of the fragmented database, focusing on the
global collaboration between multiple databases.
+
+In addition to distributed enhancement, data control and traffic control
enhancements are both in the silo structure. Incremental capabilities for data
control include data encryption, data desensitization, data watermarking, data
traceability, SQL audit etc.
+
+Incremental capabilities for traffic control include shadow library, gray
release, SQL firewall, blacklist and whitelist, circuit-breaker and
rate-limiting and so on. They are all provided by the database ecosystem layer.
However, owing to database fragmentation, it is a huge amount of work to
provide full enhancement capability for each database, and there is no unified
standard. Database Plus provides users like you with the permutation and
combination of supported database types and e [...]
+
+### 3. Pluggable: building a database-oriented functional ecosystem
+
+The Database Plus common layer could become bloated due to docking with an
increasing number of database types, and additional enhancement capability. The
pluggability borne out of Connect and Enhance is not only the foundation of
Database Plus’ common layer, but also the effective guarantee of infinite
ecosystem expansion possibilities.
+
+The pluggable architecture enables Database Plus to truly build a
database-oriented functional ecosystem, unifying and managing the global
capabilities of heterogeneous databases. It is not only for the distribution of
centralized databases, but also for the silo function integration of
distributed databases.
+
+Microkernel design and pluggable architecture are core values of the Database
Plus concept, which is oriented towards a common platform layer rather than a
specific function.
+
+
+
+## ShardingSphere’s exploration of Database Plus
+The Apache ShardingSphere project has a long history. From being an open
source database sharding middleware to being the Database Plus concept
initiator. Currently, Apache ShardingSphere follows the Database Plus
development concept and has completed most of its foundations according to the
three core values of Database Plus.
+
+### 1. Connect layers
+ShardingSphere supports database protocols such as MySQL, PostgreSQL,
[openGauss](https://opengauss.org/en/), and MySQL, PostgreSQL, openGauss, SQL
Server, Oracle, and all SQL dialects that support the SQL 92 standard.
+The abstract top-level interface of the connect layers is open for other
databases to interconnect, including database protocols, SQL parsing, and
database access.
+
+### 2. Enhance layers
+The function enhancement of ShardingSphere is divided into the kernel layer
and the optional function layer.
+The kernel layer contains query optimizers, distributed transactions,
execution engine, permission engine, and other functions heavily related to the
database kernel, as well as scheduling engine, distributed governance, and
other functions heavily related to the distribution.
+Each module of kernel function must exist, but it can be switched to a
different implementation type. Take the query optimizer as an example. If the
SQL to be executed can be perfectly pushed down to the backend database, a
computational pushdown engine based on the interaction between the original SQL
and the database is used. If the SQL to be executed requires correlated queries
across multiple data sources, a federated query engine based on the interaction
between the query plan tree [...]
+In addition to the most typical data sharding and read/write splitting, the
functional modules such as high availability, elastic scaling, data encryption,
and shadow library are being gradually improved.
+
+### 3. Pluggable layers
+The project has been completely transformed from the original architecture
model centered on MySQL plus data fragmentation to the current microkernel plus
pluggable architecture. ShardingSphere is completely pluggable from the
database types and enhancements that provide connectivity, to its kernel
capabilities.
+
+The core and periphery of ShardingSphere architecture are composed of three
layers of models realized by microkernel, pluggable interface, and plugins. A
single dependence is realized between layers, which means that the microkernel
does not need to perceive plug-ins at all and plug-ins do not need to depend on
each other. For a large-scale project with 200+ modules, the decoupling and
isolation of the architecture is an effective guarantee of open collaboration
between communities to mi [...]
+
+### Summary
+Database Plus is the development concept driving ShardingSphere, and
ShardingSphere is the best practitioner of the Database Plus concept. As
ShardingSphere becomes increasingly mature, the Database Plus puzzle will have
found a prime example.
+
+
+
+## The advantages of Database Plus
+Database Plus brings too many benefits for us to be able to list them all in
this article. This article will only illustrate its impact on system
architecture design and technology selection.
+
+### 1. Adaptability to flexible application scenarios
+You can fully customize features according to your needs. Data sharding is no
longer indispensable when using ShardingSphere, and there are many
ShardingSphere users who use the data encryption function independently. The
pluggable capability of ShardingSphere is not only limited to the database
access layer and the function enhancement module itself.
+Take data sharding as an example. As a pluggable part of the data sharding
module, the sharding algorithm can be fully customized. Whether it is the
standard `hash`, `range`, `time` and other sharding algorithms, or custom
sharding algorithms, they all can be configured freely and flexibly according
to your needs in a bid to achieve optimal performance.
+
+### 2. Microservice backend support capability for architects
+Apache ShardingSphere is the best solution for database unitization at the
backend of microservices. As mentioned above, different microservices share a
set of distributed database clusters, which cannot be viewed as a perfect and
elegant solution in terms of architecture design asymetry or uncontrollable
resource isolation. Building a distributed database cluster for each set of
microservices would cause unnecessary resources waste.
+
+Compared with the heavyweight distributed database cluster,
ShardingSphere-Proxy saves a lot of resources, laying a good foundation for
each microservice cluster to have an independent set of database clusters.
However, even if the microservice splitting is refined, it still takes a lot of
resources to build a set of
[Shardingsphere-Proxy](https://shardingsphere.apache.org/document/current/en/overview/#shardingsphere-proxy)
for each set of microservices. In this case, the less resource-i [...]
+
+ShardingSphere-Proxy and ShardingSphere-JDBC can be used in a hybrid
deployment to meet needs such as user-friendliness, cross-language adaptation,
high-performance, and resource management. Additionally, ShardingSphere-Proxy
and ShardingSphere-JDBC can be routed to each other in SQL requests with
different characteristics through `Traffic Rule` to minimize the impact of
application resource usage.
+
+`Traffic Rule` can send the requests consuming more computing resources to
ShardingSphere-Proxy which has exclusive resources according to user-defined
SQL characteristics (such as aggregate calculation and full-route queries
without sharding keys), while reserving transactional lightweight operations at
the microservice application end. This coincides with the concept of edge
computing, which means the computing capability of ShardingSphere-JDBC in
microservice applications is similar t [...]
+
+
+
+The flexible use of ShardingSphere-Proxy, ShardingSphere-JDBC, and `Traffic
Rule` will continue to support architects’ design inspiration and creativity.
As a joke, the proper use of ShardingSphere for elegant system design can be
regarded as the threshold for a good architect.
+
+### 3. DistSQL brings a native database operation experience to DBAs
+Whille enhancing functions such as data sharding and data encryption, the
previous version of Apache ShardingSphere mainly adopted `YAML` configuration.
For developers, the flexible `YAML` configuration is convenient to use, but
`YAML` configuration is actually inconvenient for DBAs. Apart from changing the
SQL operating habits of DBAs, it is unable to connect with third-party systems
such as permission, security, work order, monitoring, and audit.
+
+The new version of Apache ShardingSphere adds DistSQL operation mode. This
allows you to use the enhanced features through SQL at any database terminal
such as MySQL, Cli, or Navicat. DistSQL matches all of the powerful functions
such as data sharding, data encryption, and read/write splitting. You can
configure all functions using SQL syntax such as `CREATE`, `ALTER`, `DROP`, or
`SHOW` that the DBA is familiar with. DistSQL also supports the management and
control of authorized statemen [...]
+
+The database table structure is the metadata of theDatabase, and enhancement
function configuration is the metadata of Database Plus. DistSQL not only
improves the user-friendliness, but also completes the final puzzle for the
release, operation and maintenance of Apache ShardingSphere.
+
+### 4. Proxyless model contributes to optimal performance
+In the field of Service Mesh, Istio plus Envoy is the most widespread
architecture. It manages Envoy through Sidecar deployment while remaining
non-intrusive to applications — giving what is called Proxy Service Mesh. It
reduces development, use, and upgrade costs but its performance is lowered due
to the addition of the Proxy/Sidecar layer in access links.
+
+Proxyless Service Mesh adopts another design model, which derives from the
implementation of xDS protocol by gRPC. The new version of Istio allows the
application code to pass directly through the SDK provided by Istio Agent
through gRPC plus xDS programming, notably improving communication efficiency.
+
+In the field of distributed databases, the architecture design of
storage/computing splitting has been widely accepted. The design of splitting
compute and storage nodes is somewhat similar to the architectural model of
Proxy Service Mesh. ShardingSphere-Proxy is also designed with the
aforementioned model. It can effectively reduce development, use, and upgrade
costs for users, but its performance is inevitably lowered.
+
+For performance-sensitive applications, ShardingSphere-JDBC, which coincides
with the design concept of Proxyless Service Mesh, is undoubtedly more
applicable and can be used to maximize system performance. A recent performance
test with 16 servers to the [TPC-C model using ShardingSphere plus openGauss
achieved over 10 million transactions per minute (tpmC), breaking performance
records.](https://medium.com/codex/apache-shardingsphere-opengauss-breaking-the-distributed-database-performa
[...]
+
+### Summary
+The gRPC’s Proxyless design concept was born recently, while the
ShardingSphere-JDBC project has been around since the open source project began
in 2016. Therefore, ShardingSphere-JDBC did not refer to the design concept of
Proxyless. It was born based on the demand Internet focused businesses from
Asia, for maximum performance including high concurrency and low latency.
+
+The same is true for the design of the Database Plus concept, borne out of to
solve real world enterprise bottlenecks. ShardingSphere is the best example
Database Plus, as its design is derived from real business scenarios. The
Chinese Internet vertical where i spent most of my professional experience, is
undoubtedly one of the most comprehensive scenarios in the world. Thus, a
design concept born in such scenarios must also have extensive room for
development.
+
+## Future plan
+Although the Database Plus concept has witnessed more and more iterations,
Apache ShardingSphere still has a long way to go. The database gateway and
heterogeneous federated query are the important functional pieces of the puzzle
to complete the Database Plus concept.
+
+### 1. Database gateway
+Although Apache ShardingSphere supports the interconnection of heterogeneous
databases, it cannot achieve the conversion of dialects between databases. In
ShardingSphere’s route planning, SQL dialect conversion is an important
function to achieve database gateway. It is no longer a difficult task for
users to access MongoDB in MySQL dialect via PostgreSQL’s database protocol.
+
+### 2. Heterogeneous federated query
+Apache ShardingSphere currently only supports federated queries between
homogeneous databases. In ShardingSphere’s route planning, federated query
between heterogeneous databases will also be put on the agenda. It will no
longer be far away for users to query MySQL and HBase with one SQL.
+
+## Conclusion
+The Apache ShardingSphere community has been active in open source for 7
years. Through perseverance, the community has become mature we’d like to
extend our sincere welcome to any devs or contributors who are enthusiastic
about open source and coding to collaborate with us.
+
+Among our recent achievements we’re particulary proud of, Apache
ShardingSphere’s pluggable architecture and data sharding philosophy have been
recognized by the academic community. [The paper, Apache ShardingSphere: A
Holistic and Pluggable Platform for Data Sharding, has been published at this
year’s ICDE, a top conference in the database
field.](https://faun.pub/a-holistic-pluggable-platform-for-data-sharding-icde-2022-understanding-apache-shardingsphere-55779cfde16)
+
+## Author
+
+Zhang Liang, the founder & CEO of [SphereEx](https://www.sphere-ex.com),
served as the head of the architecture and database team of many large
well-known Internet enterprises. He is enthusiastic about open source and is
the founder and PMC chair of Apache ShardingSphere, ElasticJob, and other
well-known open source projects.
+He is now a member of the [Apache Software
Foundation](https://www.apache.org), a [Microsoft
MVP](https://mvp.microsoft.com), [Tencent Cloud
TVP](https://cloud.tencent.com/tvp), and [Huawei Cloud
MVP](https://developer.huaweicloud.com/mvp) and has more than 10 years of
experience in the field of architecture and database. He advocates for elegant
code, and has made great achievements in distributed database technology and
academic research. He has served as a producer and speaker at doze [...]
\ No newline at end of file
diff --git
a/docs/blog/content/material/2022_05_17_How_does_Apache_ShardingSphere_implement_distributed_transactions.en.md
b/docs/blog/content/material/2022_05_17_How_does_Apache_ShardingSphere_implement_distributed_transactions.en.md
new file mode 100644
index 00000000000..384ee9d9859
--- /dev/null
+++
b/docs/blog/content/material/2022_05_17_How_does_Apache_ShardingSphere_implement_distributed_transactions.en.md
@@ -0,0 +1,277 @@
++++
+title = "How does Apache ShardingSphere implement distributed transactions?"
+weight = 55
+chapter = true
++++
+
+With increasing amounts of data and increasing traffic load, business systems
are facing significant challenges, and a strong demand for the scalability of
database systems has emerged. Problems in online scaling of traditional
standalone databases such as [Oracle](https://www.oracle.com/),
[MySQL](https://www.mysql.com/), [SQL
Server](https://www.microsoft.com/en-us/sql-server/sql-server-downloads), and
[PostgreSQL](https://www.postgresql.org/) is now more evident than ever. In
such cas [...]
+
+In this context, ShardingSphere provides a distributed database computing
enhancement engine that can support distributed transactions with an ecosystem
that is easily expandable thanks to a plugin oriented architecture.
+
+## Transaction processing
+**Transaction properties**
+Three properties define transactions: atomicity, durability, consistency, and
isolation.
+
+**Atomicity**
+
+In a distributed scenario, the operations of a transaction may be distributed
on multiple physical nodes, ensuring that all operations on multiple nodes
succeed or fail.
+
+**Durability**
+
+The operation of a transaction committed is valid even if the power is cut off.
+
+**Consistency**
+
+**Tip:** Here “Consistency” is different from the C in CAP theorem. The C in
CAP refers to the data consistency between multiple copies, but here it refers
to an abstract concept between different levels.
+
+From a user’s persperctive, data transfers from one state to another and both
states are confined to a certain degree. For example:
+
+Bank account A has 500$ and account B has 500$, totalling 1,000$. After A and
B perform the transfer operation in a transaction, their total amount is still
1,000$.
+
+**Isolation**
+
+When transactions are executed concurrently, data correctness is ensured. For
example, two transactions modify the same data at the same time to ensure that
the two transactions are executed in a certain order to keep the data correct.
+
+**Challenges**
+Compared to standalone transactions, distributed transactions face the
following challenges:
+
+1. Atomicity. For standalone transactions, using undo log and redo log
guarantees full commit or full roll-back. However, distributed transactions
involve multiple physical nodes, each of which is different. Some node logs can
be written successfully, while others fail.
+2. Network instability. Communication is stable for a standalone machine and
any operation can be answered whether successful or not. However, in a
distributed scenario, the network is unstable, and an operation may not be
answered. Thus, how to ensure the availability of distributed transactions
(clearing and recovery of abnormal transactions etc.) is a problem.
+3. Concurrency control. With the advent of MVCC, linearizable operation has
become a rigid demand. Globally increasing transaction numbers can easily be
done in a standalone database, but not in a distributed scenario.
+
+**Solutions**
+**Atomic commit**
+
+The mainstream solution to atomicity and network instability problems is [2PC
(two-phase commit
protocol)](https://en.wikipedia.org/wiki/Two-phase_commit_protocol), which
defines two roles, that is TM (Transaction Manager) and RM (Resource Manager).
+
+In distributed scenarios, the operations of a transaction can be distributed
in multiple nodes. And the transaction includes two phases.
+
+**Phase One:** RM locks related resources and performs specific operations and
then returns success or failure to TM.
+
+**Phase Two:** according to the results returned by RM in the first phase, TM
will execute the final commit operations (transaction state change, lock state
deletion, etc.) if all the operations are successful, and roll back if any
fails.
+
+**Note:** There are, of course, some things that need to be optimized, such as
converting transactions that do not involve multiple nodes to one-phase commit
etc.
+
+**Note:** The two-phase commit protocol only addresses the commit issue.
Either the commit succeeds or fails. There is no intermediate state of partial
success.It’s not necessarily related to the transaction isolation level.
+
+**Concurrency control**
+
+Concurrency control is a strategy ensuring that concurrent transactions are
executed at a certain isolation level. Since the advent of Multiversion
Concurrency Control (MVCC), mainstream databases have largely abandoned the
previous two-phase locking model.
+
+Concurrency control essentially controls the concurrency of data read and
write. The concurrency control stratigies determine the isolation level, and
concurrency control addresses the following two problems:
+
+1. Determining the granularity of concurrency. For example, MySQL has row
locks (lock granularity is one row) and table locks (lock granularity is one
table) and so on.
+2. Three concurrency scenarios:
+a. Read concurrency. No special processing is required because no data changes
are involved.
+b. Write concurrency. Do not write concurrently., otherwise data corruption
will occur.
+c. Read/write concurrency. Performance optimization is mainly completed in
this scenario. There are a variety of concurrency control mechanisms, among
which Multiversion Concurrency Control is the most popular one.
+
+**MVCC Model**
+Two mainstream implementation modes:
+
+1. Based on transaction ID and ReadView
+The transaction ID is obtained for each transaction to identify the sequence
in which the transaction is started. Snapshots are obtained through the active
list to store multiple versions of data with the transaction ID, to achieve the
effect of concurrency control. MySQL and
[Postgres-XL](https://www.postgres-xl.org/) both take this approach.
+
+2. Based on timestamp
+By introducing timestamp, the visibility can be determined by adding
timestamp-related attributes to data and comparing commits (commit timestamp)
and Snapshot timestamp of data, to achieve the linearized concurrency control.
That’s what [Spanner](https://research.google/pubs/pub39966/) did.
+
+The above two modes are dependent on the generation of global transaction
numbers. The common generation mechanisms include TrueTime (used by Spanner),
HLC ([CockroachDB](https://www.cockroachlabs.com/) uses HLC with errors), and
TSO (Timestamp Oracle).
+
+## ShardingSphere’s transaction design
+ShardingSphere’s transaction feature is built on the local transaction of the
storage DB, providing three transaction modes: `LOCAL`, `XA` and `BASE`. You’d
only need to use the native transaction mode (`begin`/`commit`/`roll-back`) to
use the three modes and make appropriate trade-offs between consistency and
performance.
+
+**LOCAL**
+
+`LOCAL` mode is directly built on the local transaction of thestorage DB. It
has the highest performance, although there’s a problem with atomicity. If you
can tolerate this problem, it’s a good choice.
+
+**XA**
+
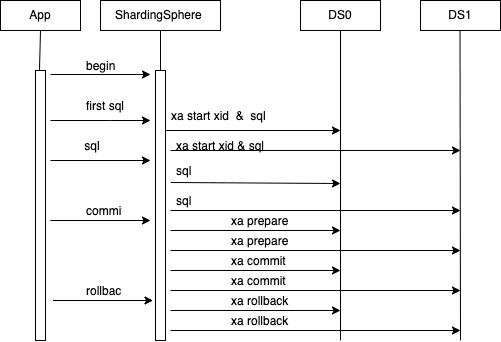
+In XA mode, the XA protocol is based on a set of interaction protocols defined
by 2PC. It defines the `xa start/prepare/end/commit/rollback` interface. The
commonly-used implementations have Narayana, Atomics, and ShardingSphere
integrate the XA implementation of Narayana and Atomics.
+
+1. The app connects to the Proxy, and the Proxy creates a session object bound
to the connection.
+2. The app executes `begin`. Proxy creates a logical transaction through
Narayana TM, and binds it to the current session.
+3. The app executes specific SQL. Session establishes a connection to storage
DB, and connection can be registered to transaction through
`Transaction.enlistResource ()` interface. Then execute`XA START {XID}` to
start the transaction and execute the SQL overwritten by routing.
+4. The app runs the `commit` command, executes `xa prepare` for each
connection registered in the transaction database, updates the transaction
status to `prepared`, and performs `xa commit` for each connection. If the
system returns ok, updates the transaction status to `Committed`, and the
transaction is committed successfully. If the `prepare` process fails, you can
run the `rollback` command to roll back the data. If not, a background process
will clear the data.
+5. The app runs the `rollback` command, and the connection registered in the
transaction that connects the storage DB executes `xa rollback` respectively.
+
+
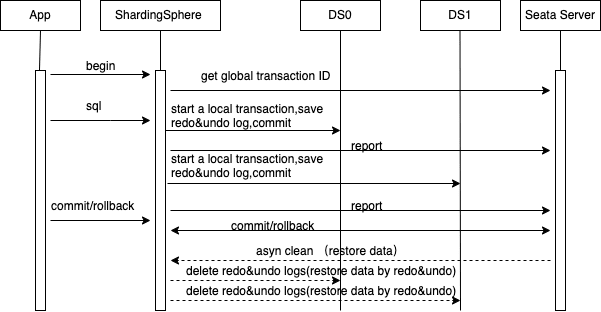
+**BASE**
+
+[BASE (Basically Available, Soft State, Eventually Consistent)
](https://phoenixnap.com/kb/acid-vs-base)mode. BASE transaction is the result
of balance between C and A in CAP theorem. The AT mode of
[Seata](https://seata.io/en-us/) is an implementation of BASE transaction, and
ShardingSphere integrates the AT implementation of Seata.
+
+1. The app connects to the Proxy, and the Proxy creates a session object bound
to the connection.
+2. The app executes `begin`. Proxy creates a logical transaction through Seata
TM, binds it to the current session and registers it with Seata Server.
+3. The app executes logical SQL. Session establishes a connection to the
storage DB. Each connection is a `ConnectionProxy` instance of Seata. And then
parse the `actual sql` overwritten by routing and execute interceptions. For
example, if it is a modification operation, execute `begin` to obtain the local
lock, execute an `SQL` query, execute `commit` to release the local lock, and
report the branch transaction results to Seata Server.
+4. After the app runs the `commit` command, the Seata TM in Proxy notifies the
Seata Server and directly returns to the app. The Seata Server asynchronously
interacts with the Proxy to delete transaction logs.
+5. The app runs the `rollback` command. After the Seata TM in the Proxy
notifies the Seata Server, the Proxy directly returns to the app. The Seata
Server asynchronously interacts with the Proxy, performs compensation
operations, and deletes transaction logs.
+
+
+
+## Examples
+**Installation package preparation**
+Take an XA with good supporting capability integrated with Narayana
implementation as an example. Due to the Narayana License issue, it cannot be
packaged directly into the installation package, and additional dependencies
need to be added.
+
+Download the installation package from the official website, decompress it to
the directory `${ShardingSphere}` , and add the following `jar` packages to the
directory `${ShardingSphere}/lib`.
+
+(Download:https://mvnrepository.com/)
+
+```
+jta-5.12.4.Final.jar
+arjuna-5.12.4.Final.jar
+common-5.12.4.Final.jar
+jboss-connector-api_1.7_spec-1.0.0.Final.jar
|
------------------------------------------------------------------------------------------------------------------------------------
+jboss-logging-3.2.1.Final.jar
|
------------------------------------------------------------------------------------------------------------------------------------
+jboss-transaction-api_1.2_spec-1.0.0.Alpha3.jar
|
------------------------------------------------------------------------------------------------------------------------------------
+jboss-transaction-spi-7.6.0.Final.jar
+mysql-connector-java-5.1.47.jar
|
------------------------------------------------------------------------------------------------------------------------------------
+narayana-jts-integration-5.12.4.Final.jar
+shardingsphere-transaction-xa-narayana-5.1.1-SNAPSHOT.jar
+```
+**MySQL instance preparation**
+Prepare two MySQL instances: 127.0.0.1:3306 and 127.0.0.1:3307.
+Create user root with password 12345678 for each MySQL instance.
+Create a test library for each MySQL instance.
+
+**ShardingSphere-Proxy configuration**
+Modify the transaction configuration of `server.yaml`
+
+```
+rules:
+ - !AUTHORITY
+ users:
+ - root@%:root
+ - sharding@:sharding
+ provider:
+ type: ALL_PRIVILEGES_PERMITTED
+ - !TRANSACTION
+ defaultType: XA
+ providerType: Narayana
+```
+Modify `conf/conf-sharding.yaml`
+
+```yaml
+dataSources:
+ ds_0:
+ url:
jdbc:mysql://127.0.0.1:3306/test?serverTimezone=UTC&allowPublicKeyRetrieval=true&useSSL=false
+ username: root
+ password: 12345678
+ connectionTimeoutMilliseconds: 30000
+ idleTimeoutMilliseconds: 60000
+ maxLifetimeMilliseconds: 1800000
+ maxPoolSize: 50
+ minPoolSize: 1
+ ds_1:
+ url:
jdbc:mysql://127.0.0.1:3307/test?serverTimezone=UTC&allowPublicKeyRetrieval=true&useSSL=false
+ username: root
+ password: 12345678
+ connectionTimeoutMilliseconds: 30000
+ idleTimeoutMilliseconds: 60000
+ maxLifetimeMilliseconds: 1800000
+ maxPoolSize: 50
+ minPoolSize: 1
+
+rules:
+ - !SHARDING
+ tables:
+ account:
+ actualDataNodes: ds_${0..1}.account${0..1}
+ tableStrategy:
+ standard:
+ shardingColumn: id
+ shardingAlgorithmName: account_inline
+ keyGenerateStrategy:
+ column: id
+ keyGeneratorName: snowflake
+ defaultDatabaseStrategy:
+ standard:
+ shardingColumn: id
+ shardingAlgorithmName: database_inline
+ defaultTableStrategy:
+ none:
+
+ shardingAlgorithms:
+ database_inline:
+ type: INLINE
+ props:
+ algorithm-expression: ds_${id % 2}
+ account_inline:
+ type: INLINE
+ props:
+ algorithm-expression: account${id % 2}
+
+ keyGenerators:
+ snowflake:
+ type: SNOWFLAKE
+ props:
+ worker-id: 123
+```
+**Start ShardingSphere-Proxy**
+Start the Proxy by running the following command:
+
+```bash
+cd ${ShardingSphere}
+./bin/start.sh
+```
+**Use ShardingSphere-Proxy**
+Use MySQL Client to connect shardingSphere-Proxy for testing, refer to the
following command.
+
+```
+mysql -h127.0.0.1 -P3307 -uroot -proot
+mysql> use sharding_db;
+Database changed
+mysql> create table account(id int, balance float ,transaction_id int);
+Query OK, 0 rows affected (0.12 sec)
+
+mysql> select * from account;
+Empty set (0.02 sec)
+
+mysql> begin;
+Query OK, 0 rows affected (0.09 sec)
+
+mysql> insert into account(id, balance, transaction_id) values(1,1,1),(2,2,2);
+Query OK, 2 rows affected (0.53 sec)
+
+mysql> select * from account;
++------+---------+----------------+
+| id | balance | transaction_id |
++------+---------+----------------+
+| 2 | 2.0 | 2 |
+| 1 | 1.0 | 1 |
++------+---------+----------------+
+2 rows in set (0.03 sec)
+
+mysql> commit;
+Query OK, 0 rows affected (0.05 sec)
+
+mysql> select * from account;
++------+---------+----------------+
+| id | balance | transaction_id |
++------+---------+----------------+
+| 2 | 2.0 | 2 |
+| 1 | 1.0 | 1 |
++------+---------+----------------+
+2 rows in set (0.02 sec)
+```
+
+## Future plan
+Currently, ShardingSphere’s distributed transaction integrates the 2PC
implementation scheme of the 3rd party to guarantee atomicity. Isolation
depends on the isolation guarantee of the storage DB, providing available
transaction functions.
+
+The future implementation of MVCC based on global Timestamp and combined with
2PC, will provide better support for transaction isolation semantics.
+
+**Apache ShardingSphere Project Links:**
+[ShardingSphere
Github](https://github.com/apache/shardingsphere/issues?page=1&q=is%3Aopen+is%3Aissue+label%3A%22project%3A+OpenForce+2022%22)
+
+[ShardingSphere Twitter](https://twitter.com/ShardingSphere)
+
+[ShardingSphere
Slack](https://join.slack.com/t/apacheshardingsphere/shared_invite/zt-sbdde7ie-SjDqo9~I4rYcR18bq0SYTg)
+
+[Contributor Guide](https://shardingsphere.apache.org/community/cn/contribute/)
+
+## Author
+
+Lu Jingshang
+
+> [Apache ShardingSphere](https://shardingsphere.apache.org/) Committer &
Infrastructure R&D Engineer at [SphereEx](https://www.sphere-ex.com/).
+> Enthusiastic about open source and database technology.
+> Focus on developing Apache ShardingSphere transaction module.
+
diff --git
"a/docs/blog/content/material/2022_05_19_Apache_ShardingSphere_Enterprise_User_Case_Zhongshang_Huimin\342\200\231s_Transaction_Middle_Platform_Architecture.en.md"
"b/docs/blog/content/material/2022_05_19_Apache_ShardingSphere_Enterprise_User_Case_Zhongshang_Huimin\342\200\231s_Transaction_Middle_Platform_Architecture.en.md"
new file mode 100644
index 00000000000..0158e1d8528
--- /dev/null
+++
"b/docs/blog/content/material/2022_05_19_Apache_ShardingSphere_Enterprise_User_Case_Zhongshang_Huimin\342\200\231s_Transaction_Middle_Platform_Architecture.en.md"
@@ -0,0 +1,146 @@
++++
+title = "Apache ShardingSphere Enterprise User Case: Zhongshang Huimin’s
Transaction Middle Platform Architecture"
+weight = 56
+chapter = true
++++
+
+The FMCG (fast moving consumer-goods) industry can no longer meet current
development requirements. The traditional way of only upgrading the end of the
supply chain cannot achieve high-quality business development.
[Huimin](https://huimin.cn/) focuses on order fulfillment and delivery service
for over one million community supermarkets, transforming and upgrading from
serving retail terminal stores to promoting the digitization of the whole FMCG
industry chain.
+
+It is committed to building a B2B2C data closed-loop operating system,
providing brand owners, distributors, and community supermarkets with
transformed and upgraded solutions for the whole chain covering purchasing,
marketing, operation, and distribution. All these commitments cannot be
fulfilled without its powerful “middle platform” system.
+
+## Introducing the “middle platform”
+Huimin began to transferred [PHP](https://www.php.net/) technology stack to
the Java technology stack, and shifted to microservices from 2016 to 2017, and
started to build the “middle platform” in 2018.
+
+The phase-one project of its transaction middle platform went live in early
2021, and phase-two in March 2022.
+
+Owing to business growth and various changes, Huimin launched a strong “middle
platform” development strategy to improve efficiency and reduce costs. Measures
were taken to reduce the coupling degree between systems, increase scalability,
and ensure low latency while extracting business commonalities. At the
beginning of 2021, the company finihsed rebuilding the previous order
management system (OMS) and launched a packaged business capability project for
a transaction middle platform ce [...]
+
+To synergize technical and business requirements during the rebuilding
process, the go-live process was divided into two phases: application system
splitting and data splitting.
+
+## System splitting
+R&D teams having to frequently adjust order management system and adapt it to
multiple business lines may cause inefficiencies. In response to these
problems, the following principles were formulated to split and rebuild the
system:
+
+1. Avoid the logic coupling of different lines of business. Different business
lines should contain and minimize influence on each other to reduce logic
complexity.
+2. Responsibilities are divided according to the order lifecycle to ensure
that each system is independent with an exclusive responsibility.
+3. Read/write splitting. Ensure the stability of core functions and avoid the
impact of frequent iterations on core functions.
+4. [ElasticSearch](https://www.elastic.co/) was introduced to solve the
external index problem, and reduce database index pressure.
+
+
+
+## Data splitting
+The purpose of data splitting is to reduce the maintenance pressure of a
single table. When the amount of data reaches tens of millions, the index and
field maintenance of database tables will have a great impact on the online
environment. Before splitting a table, you have to consider the following
questions:
+
+1. Splitting rules: what tables are data-intensive? What about the number of
splits?
+2. Data read/write: how to solve the read/write problem after splitting tables?
+3. Go-live solution: how to go live smoothly?
+
+### Splitting rules
+
+During a 3 years iteration period, the number of splits = ((amount of data
added per month * 36) + Amount of historical data) / maximum amount of data in
a single table.
+
+When we use the [InnoDB](https://en.wikipedia.org/wiki/InnoDB) engine for DDL
operation to maintain [Alibaba
Cloud](https://www.alibabacloud.com/?spm=a2796.143805.6791778070.2.b8fa46e3JLecKh)
RDS MySQL, we come up with the following results:
+
+When the amount of data is less than 5 million, the execution time is about
tens of seconds. Between 5 million and less than 10 million, the execution time
is about 500 seconds; between 10 million and less than 50 million, the
execution time is about 1000 seconds; and when more than 50 million, the
execution time is more than 2000 seconds.
+
+The upper limit for splitting a single table depends on the impact of a single
table operation on business. Of course, some solutions can tackle the problem
of table lock resulting from DDL operation. For example, dual-table
synchronization and changes in table names can reduce the impact to within
seconds.
+
+The split number of the library table is preferably 2 to the power of N, which
is conducive to later horizontal scaling.
+
+### Technology selection
+
+After the data table is split, data hashing and query issues need to be
resolved. As a SME (small & medium-sized enterprise), the cost of developing a
set of sharding middleware is too high, and it will cause various risks in the
early stage. A reasonable solution is to adopt a set of open source database
sharding middleware.
+
+**[Apache ShardingSphere](https://shardingsphere.apache.org/)**
+
+Apache ShardingSphere is an open source ecosystem that allows you to transform
any database into a distributed database system. The project includes a JDBC, a
Proxy and Sidecar (Planning), which can be deployed independently and support
mixed deployment. They all provide functions of data scale-out, distributed
transactions and distributed governance.
+
+Apache ShardingSphere 5.x introduces the concept of [Database
Plus](https://faun.pub/whats-the-database-plus-concepand-what-challenges-can-it-solve-715920ba65aa),
and the new version focuses on a plugin oriented architecture. Currently,
functions including data sharding, read/write splitting, data encryption,
shadow library pressure testing, as well as SQL and protocol support such as
[MySQL](https://www.mysql.com/), [PostgreSQL](https://www.postgresql.org/),
[SQL Server](https://www.mic [...]
+
+Why Huimin chose Apache ShardingSphere:
+
+1. Apache ShardingSphere has a variety of functions and can solve current
challenges with strong scalability.
+
+2. The Apache ShardingSphere community is very active, which means the
possibility to find support quickly.
+
+3. The company adopts the SpringCloud technology stack which is convenient for
integration and can lower costs.
+
+4. Its performance can fully support Huimin’s existing business.
+
+ShardingSphere supports the following 3 modes:
+
+
+
+Currently, Huimin’s server-side technology stack only involves Java language,
so there is no need to consider heterogeneous scenarios. Taking flexibility,
code intrusion and deployment cost into consideration, the implementation of
[ShardingSphere-JDBC](https://shardingsphere.apache.org/document/current/en/overview/#shardingsphere-jdbc)
wasfinally selected.
+
+### Technology implementation
+
+The most complicated part of the process is actually the go-live part, not the
plugin integration part as would someone expect.
+
+To achieve non-perception and rollback, we divided the go-live process into
the following steps, as shown in the figure:
+
+
+
+**Step 1:** Processing all the data needs to ensure the data consistency
between the old and new libraries. Since there currently is no synchronization
tool supporting data sharding policy, we developed a data synchronization tool
to support the configuration of the sharding policy.
+
+**Step 2:** Process incremental data to keep data consistency between the old
and new libraries. Our implementation scheme here was to use the open source
component, to listen to the binlog of the database and synchronize the database
changes to the message queue, and then the data synchronization tool listens to
the messages and writes them into the new library.
+
+The architecture scheme is not complicated, but great importance was attached
to the data consistency in this process. Incremental data cannot be lost, and
single-line data should be written in sequential order to prevent ABA problems.
+
+**Step 3:** Process the gray-release of read-traffic. At this point, we were
writing an old library and reading a new library in the database. In this
process, we should paid attention to the sensitivity of business to data
consistency, because the delay from an old library to a new library is within
seconds. Reading an old library is needed when we come across some sensitive
scenarios requiring high consistency.
+
+**Step 4:** Switch all read-traffic of the application to the new library,
maintaining the status of writing the old library and reading the new library.
+
+**Step 5:** Processing write-traffic didn’t take gray-release scenarios into
consideration in order to reduce the complexity of the program. Of course, the
grayscale scheme can also achieve the same effect. We supported the rollback
strategy by writing data from the new library back to the old library, and then
uniformly transferring all traffic to the new library within one release.
+
+So far, the whole process of release and going live has been completed. Due to
the low cost of completing the transformation with the help of
ShardingSphere-JDBC middleware to rewrite SQL and merge results, there was
almost no code intrusion and going live went smoothly.
+
+There are also some issues that you may need to be aware of when accessing the
ShardingSphere-JDBC scheme:
+
+1. ShardingSphere-JDBC supports a default processing for data insertion logic.
If there is no shard column in SQL, the same data will be inserted into each
shard table.
+
+2. ShardingSphere-JDBC parses only the logil table of the first SQL for
batches of SQL semantic analysis, which results in an error. This problem has
been reported and should be fixed in the near future. Additionally, a detailed
SQL sample is provided, which lists in detail the scope of support.
+
+3. ShardingSphere connection mode selection. The number of database
connections visited by businesses should be limited for the sake of resource
control. It can effectively prevent a service operation from occupying too many
resources, which depletes the database connection resources and affects the
normal access of other services. Especially in the case of many sub-tables in a
database instance, a logical SQL without shard keys will produce a large number
of actual SQL that falls on dif [...]
+
+From the perspective of execution efficiency, maintaining a separate database
connection for each shard query can make more effective use of multi-threading
to improve execution efficiency. Building a separate thread for each database
connection allows I/O consumption to be processed concurrently, maintains a
separate database connection for each shard, and avoids premature loading of
query result data into memory. A separate database connection can hold a
reference to the cursor locatio [...]
+
+The result merging method by moving the result set cursor down is called
streaming merge. It does not have to load all the result data into memory,
which can effectively save memory resources and reduce the frequency of garbage
collection. If each shard query cannot be guaranteed to have a separate
database connection, the current query result set needs to be loaded into
memory before reusing the database connection to obtain the query result set of
the next shard table. Therefore, even [...]
+
+It is a problem for the ShardingSphere execution engine to balance the
relationship between the control and protection of database connection
resources and saving middleware memory resources by adopting a better merging
mode. Specifically, if a SQL needs to operate on 200 tables under a database
instance after its sharding in ShardingSphere, whether to create 200
connections and execute them concurrently or create one connection and execute
it in sequence? How to choose between efficienc [...]
+
+In response to the above scenario, ShardingSphere provides a solution. It
introduces the concept of Connection Mode and divides it into `MEMORY_STRICTLY`
mode and `CONNECTION_STRICTLY` mode.
+
+`MEMORY_STRICTLY`
+
+The premise of using this pattern is that ShardingSphere does not limit the
number of database connections required by an operation. If the actual SQL
executed needs to operate on 200 tables in a database instance, a new database
connection is created for each table and processed concurrently through
multi-threading to maximize the execution efficiency. When SQL meets the
conditions, streaming merge is preferred to prevent memory overflow or frequent
garbage collection.
+
+`CONNECTION_STRICTLY`
+
+The premise for using this pattern is that ShardingSphere strictly limits the
number of database connections required for an operation. If the actual SQL
executed needs to operate on 200 tables in a database instance, only one single
database connection is created and its 200 tables are processed sequentially.
If shards in an operation are scattered across different databases,
multi-threading is still used to handle operations on different libraries, but
only one database connection is c [...]
+
+The `MEMORY_STRICTLY` mode is applicable for OLAP operations and can improve
system throughput by relaxing limits on database connections. The
`CONNECTION_STRICTLY` mode applies to OLTP operations, which usually have shard
keys and are routed to a single shard. Therefore, it is a wise choice to
strictly control database connections to ensure that database resources in an
online system can be used by more applications.
+
+We found that in the `MEMORY_STRICTLY` mode, the operation would become
I/O-intensive due to the cache buffer loading strategy of MySQL InnoDB engine,
resulting in SQL timeouts. Its solution is to add another layer of processing
without changing database resources. If there is no shard key, verify the shard
key in the external index, and then use the shard key to perform database
retrieval.
+
+## ShardingSphere Benefits
+**1. Performance improvement**
+Through architecture rebuilding, it can effectively control the amount of
single table data, and greatly reduce the slow SQL, down nearly 50%.
+
+**2. Save R&D resources and lower cost**
+
+The introduction of Apache ShardingSphere does not require the re-development
of sharding components, which reduces the R&D cost and lowers the risks.
+
+**3. Strong scalability**
+
+Apache ShardingSphere has good scalability in terms of data encryption,
distributed transactions, shadow library and other aspects.
+
+## Conclusion
+
+In his book [Building Microservices, Sam
Newman](https://samnewman.io/books/building_microservices/) writes, “ Our
requirements shift more rapidly than they do for people who design and build
buildings — as do the tools and techniques at our disposal. The things we
create are not fixed points in time. Once launched into production, our
software will continue to evolve as the way it is used changes. For most things
we create, we have to accept that once the software gets into the hands of [...]
+
+## Author
+**Zhai Yang**
+
+Software architect at Zhongshang Huimin E-Commerce platform team.
+
+Participated in the 0–1 process of middle platform construction, mainly
responsible for the R&D and building the transaction and commodity middle
platform and the search platform.
\ No newline at end of file
diff --git
a/docs/blog/content/material/2022_05_24_Your_Guide_to_DistSQL_Cluster_Governance_Capability_Apache_ShardingSphere_Feature_Update.en.md
b/docs/blog/content/material/2022_05_24_Your_Guide_to_DistSQL_Cluster_Governance_Capability_Apache_ShardingSphere_Feature_Update.en.md
new file mode 100644
index 00000000000..b2eac41cbb3
--- /dev/null
+++
b/docs/blog/content/material/2022_05_24_Your_Guide_to_DistSQL_Cluster_Governance_Capability_Apache_ShardingSphere_Feature_Update.en.md
@@ -0,0 +1,449 @@
++++
+title = "Your Guide to DistSQL Cluster Governance Capability——Apache
ShardingSphere Feature Update"
+weight = 57
+chapter = true
++++
+
+Since Apache ShardingSphere 5.0.0-Beta version included DistSQL, it made the
project increasingly loved by developers and Ops teams for its advantages such
as dynamic effects, no restart, and elegant syntax close to standard SQL.
+
+With upgrades to 5.0.0 and 5.1.0, the ShardingSphere community has once again
added abundant syntax to DistSQL, bringing more practical features.
+
+In this post, the community co-authors will share the latest functions of
DistSQL from the perspective of “cluster governance”.
+
+## ShardingSphere Cluster
+In a typical cluster composed of ShardingSphere-Proxy, there are multiple
`compute nodes` and storage nodes, as shown in the figure below:
+
+To make it easier to understand, in ShardingSphere, we refer to Proxy as a
compute node and Proxy-managed distributed database resources (such as `ds_0`,
`ds_1`) as `resources` or `storage nodes`.
+
+
+
+Multiple Proxy or compute nodes are connected to the same register center,
sharing configuration, and rules, and can sense each other’s online status.
+
+These compute nodes also share the underlying storage nodes, so they can
perform read and write operations to the storage nodes at the same time. The
user application is connected to any compute node and can perform equivalent
operations.
+
+Through this cluster architecture, you can quickly scale Proxy horizontally
when compute resources are insufficient, reducing the risk of a single point of
failure and improving system availability.
+
+The load balancing mechanism can also be added between application and compute
node.
+
+**Compute Node Governance**
+Compute node governance is suitable for Cluster mode. For more information
about the ShardingSphere modes, please see [Your Detailed Guide to Apache
ShardingSphere’s Operating
Modes](https://medium.com/codex/your-detailed-guide-to-apache-shardingspheres-operating-modes-e50df1ee56e4).
+
+**Cluster Preparation**
+Take a standalone simulation of three Proxy compute nodes as an example. To
use the mode, follow the configuration below:
+
+```yaml
+mode:
+ type: Cluster
+ repository:
+ type: ZooKeeper
+ props:
+ namespace: governance_ds
+ server-lists: localhost:2181
+ retryIntervalMilliseconds: 500
+ timeToLiveSeconds: 60
+ maxRetries: 3
+ operationTimeoutMilliseconds: 500
+ overwrite: false
+```
+Execute the bootup command separately:
+
+```bash
+sh %SHARDINGSPHERE_PROXY_HOME%/bin/start.sh 3307
+sh %SHARDINGSPHERE_PROXY_HOME%/bin/start.sh 3308
+sh %SHARDINGSPHERE_PROXY_HOME%/bin/start.sh 3309
+```
+After the three Proxy instances are successfully started, the compute node
cluster is ready.
+
+`SHOW INSTANCE LIST`
+
+Use the client to connect to any compute node, such as 3307:
+
+```bash
+mysql -h 127.0.0.1 -P 3307 -u root -p
+```
+
+View the list of instances:
+
+```
+mysql> SHOW INSTANCE LIST;
++----------------+-----------+------+---------+
+| instance_id | host | port | status |
++----------------+-----------+------+---------+
+| 10.7.5.35@3309 | 10.7.5.35 | 3309 | enabled |
+| 10.7.5.35@3308 | 10.7.5.35 | 3308 | enabled |
+| 10.7.5.35@3307 | 10.7.5.35 | 3307 | enabled |
++----------------+-----------+------+---------+
+```
+The above fields mean:
+
+- `instance_id `: The id of the instance, which is currently composed of host
and port.
+- `Host` : host address.
+- `Port` : port number.
+- `Status` : the status of the instance enabled or disabled
+
+`DISABLE INSTANCE`
+
+`DISABLE INSTANCE` statement is used to set the specified compute node to a
disabled state.
+
+💡Note:
+the statement does not terminate the process of the target instance, but only
virtually deactivates it.
+
+`DISABLE INSTANCE` supports the following syntax forms:
+
+```
+DISABLE INSTANCE 10.7.5.35@3308;
+#or
+DISABLE INSTANCE IP=10.7.5.35, PORT=3308;
+```
+Example:
+
+```
+mysql> DISABLE INSTANCE 10.7.5.35@3308;
+Query OK, 0 rows affected (0.02 sec)
+
+mysql> SHOW INSTANCE LIST;
++----------------+-----------+------+----------+
+| instance_id | host | port | status |
++----------------+-----------+------+----------+
+| 10.7.5.35@3309 | 10.7.5.35 | 3309 | enabled |
+| 10.7.5.35@3308 | 10.7.5.35 | 3308 | disabled |
+| 10.7.5.35@3307 | 10.7.5.35 | 3307 | enabled |
++----------------+-----------+------+----------+
+```
+After executing the `DISABLE INSTANCE `statement, by querying again, you can
see that the instance status of Port 3308 has been updated to `disabled` ,
indicating that the compute node has been disabled.
+
+If there is a client connected to the `10.7.5.35@3308` , executing any SQL
statement will prompt an exception:
+
+`1000 - Circuit break mode is ON.`
+💡Note:
+It is not allowed to disable the current compute node. If you send
`10.7.5.35@3309` to `DISABLE INSTANCE 10.7.5.35@3309` , you will receive an
exception prompt.
+
+`ENABLE INSTANCE`
+
+`ENABLE INSTANCE` statement is used to set the specified compute node to an
enabled state. `ENABLE INSTANCE` supports the following syntax forms:
+
+```
+ENABLE INSTANCE 10.7.5.35@3308;
+#or
+ENABLE INSTANCE IP=10.7.5.35, PORT=3308;
+```
+Example:
+
+```
+mysql> SHOW INSTANCE LIST;
++----------------+-----------+------+----------+
+| instance_id | host | port | status |
++----------------+-----------+------+----------+
+| 10.7.5.35@3309 | 10.7.5.35 | 3309 | enabled |
+| 10.7.5.35@3308 | 10.7.5.35 | 3308 | disabled |
+| 10.7.5.35@3307 | 10.7.5.35 | 3307 | enabled |
++----------------+-----------+------+----------+
+
+mysql> ENABLE INSTANCE 10.7.5.35@3308;
+Query OK, 0 rows affected (0.01 sec)
+
+mysql> SHOW INSTANCE LIST;
++----------------+-----------+------+----------+
+| instance_id | host | port | status |
++----------------+-----------+------+----------+
+| 10.7.5.35@3309 | 10.7.5.35 | 3309 | enabled |
+| 10.7.5.35@3308 | 10.7.5.35 | 3308 | enabled |
+| 10.7.5.35@3307 | 10.7.5.35 | 3307 | enabled |
++----------------+-----------+------+----------+
+```
+
+After executing the `ENABLE INSTANCE` statement, you can query again and view
that the instance state of Port 3308 has been restored to `enabled`.
+
+## How to Manage Compute Node Parameters
+In the previous article [Integrating SCTL into RAL — Making Apache
ShardingSphere Perfect for Database
Management](https://dzone.com/articles/integrating-sctl-into-distsqls-ral-making-apache-s),
we explained the evolution of SCTL (ShardingSphere Control Language) to RAL
(Resource & Rule Administration Language) and the new `SHOW VARIABLE` and `SET
VARIABLE` syntax.
+
+However, in 5.0.0-Beta, the `VARIABLE` category of DistSQL RAL only contains
only the following three statements:
+
+```
+SET VARIABLE TRANSACTION_TYPE = xx; (LOCAL, XA, BASE)
+SHOW VARIABLE TRANSACTION_TYPE;
+SHOW VARIABLE CACHED_CONNECTIONS;
+```
+By listening to the community’s feedback, we noticed that querying and
modifying the props configuration of Proxy (located in `server.yaml`) is also a
frequent operation. Therefore, we have added support for props configuration in
DistSQL RAL since the 5.0.0 GA version.
+
+`SHOW VARIABLE`
+
+First, let’s review how to configure props:
+
+```yaml
+props:
+ max-connections-size-per-query: 1
+ kernel-executor-size: 16 # Infinite by default.
+ proxy-frontend-flush-threshold: 128 # The default value is 128.
+ proxy-opentracing-enabled: false
+ proxy-hint-enabled: false
+ sql-show: false
+ check-table-metadata-enabled: false
+ show-process-list-enabled: false
+ # Proxy backend query fetch size. A larger value may increase the memory
usage of ShardingSphere Proxy.
+ # The default value is -1, which means set the minimum value for different
JDBC drivers.
+ proxy-backend-query-fetch-size: -1
+ check-duplicate-table-enabled: false
+ proxy-frontend-executor-size: 0 # Proxy frontend executor size. The default
value is 0, which means let Netty decide.
+ # Available options of proxy backend executor suitable: OLAP(default),
OLTP. The OLTP option may reduce time cost of writing packets to client, but it
may increase the latency of SQL execution
+ # and block other clients if client connections are more than
`proxy-frontend-executor-size`, especially executing slow SQL.
+ proxy-backend-executor-suitable: OLAP
+ proxy-frontend-max-connections: 0 # Less than or equal to 0 means no
limitation.
+ sql-federation-enabled: false
+ # Available proxy backend driver type: JDBC (default), ExperimentalVertx
+ proxy-backend-driver-type: JDBC
+```
+Now, you can perform interactive queries by using the following syntax:
+
+`SHOW VARIABLE PROXY_PROPERTY_NAME;`
+
+Example:
+
+```
+mysql> SHOW VARIABLE MAX_CONNECTIONS_SIZE_PER_QUERY;
++--------------------------------+
+| max_connections_size_per_query |
++--------------------------------+
+| 1 |
++--------------------------------+
+1 row in set (0.00 sec)
+
+mysql> SHOW VARIABLE SQL_SHOW;
++----------+
+| sql_show |
++----------+
+| false |
++----------+
+1 row in set (0.00 sec)
+……
+```
+……
+💡Note:
+For DistSQL syntax, parameter keys are separated by underscores.
+
+`SHOW ALL VARIABLES`
+
+Since there are plenty of parameters in Proxy, you can also query all
parameter values through `SHOW ALL VARIABLES` :
+
+```
+mysql> SHOW ALL VARIABLES;
++---------------------------------------+----------------+
+| variable_name | variable_value |
++---------------------------------------+----------------+
+| sql_show | false |
+| sql_simple | false |
+| kernel_executor_size | 0 |
+| max_connections_size_per_query | 1 |
+| check_table_metadata_enabled | false |
+| proxy_frontend_database_protocol_type | |
+| proxy_frontend_flush_threshold | 128 |
+| proxy_opentracing_enabled | false |
+| proxy_hint_enabled | false |
+| show_process_list_enabled | false |
+| lock_wait_timeout_milliseconds | 50000 |
+| proxy_backend_query_fetch_size | -1 |
+| check_duplicate_table_enabled | false |
+| proxy_frontend_executor_size | 0 |
+| proxy_backend_executor_suitable | OLAP |
+| proxy_frontend_max_connections | 0 |
+| sql_federation_enabled | false |
+| proxy_backend_driver_type | JDBC |
+| agent_plugins_enabled | false |
+| cached_connections | 0 |
+| transaction_type | LOCAL |
++---------------------------------------+----------------+
+21 rows in set (0.01 sec)
+```
+
+`SET VARIABLE`
+
+Dynamic management of resources and rules is a special advantage of DistSQL.
Now you can also dynamically update props parameters by using the `SET
VARIABLE` statement. For example:
+
+```
+#Enable SQL log output
+SET VARIABLE SQL_SHOW = true;
+#Turn on hint function
+SET VARIABLE PROXY_HINT_ENABLED = true;
+#Open federal query
+SET VARIABLE SQL_FEDERATION_ENABLED = true;
+……
+```
+💡Note:
+
+The following parameters can be modified by the SET VARIABLE statement, but
the new value takes effect only after the Proxy restart:
+
+- `kernel_executor_size`
+- `proxy_frontend_executor_size`
+- `proxy_backend_driver_type`
+
+The following parameters are read-only and cannot be modified:
+
+- `cached_connections`
+
+Other parameters will take effect immediately after modification.
+
+## How to Manage Storage nodes
+In ShardingSphere, storage nodes are not directly bound to compute nodes.
Because one storage node may play different roles in different schemas at the
same time, in order to implement different business logic. Storage nodes are
always associated with a schema.
+
+For DistSQL, storage nodes are managed through `RESOURCE` related statements,
including:
+
+- `ADD RESOURCE`
+- `ALTER RESOURCE`
+- `DROP RESOURCE`
+- `SHOW SCHEMA RESOURCES`
+
+**Schema Preparation**
+`RESOURCE` related statements only work on schemas, so before operating, you
need to create and use `USE` command to successfully select a schema:
+
+```
+DROP DATABASE IF EXISTS sharding_db;
+CREATE DATABASE sharding_db;
+USE sharding_db;
+```
+
+`ADD RESOURCE`
+
+`ADD RESOURCE` supports the following syntax forms:
+
+Specify `HOST`, `PORT`, `DB`
+
+```
+ADD RESOURCE resource_0 (
+ HOST=127.0.0.1,
+ PORT=3306,
+ DB=db0,
+ USER=root,
+ PASSWORD=root
+);
+```
+Specify `URL`
+
+```
+ADD RESOURCE resource_1 (
+ URL="jdbc:mysql://127.0.0.1:3306/db1?serverTimezone=UTC&useSSL=false",
+ USER=root,
+ PASSWORD=root
+);
+```
+The above two syntax forms support the extension parameter PROPERTIES that is
used to specify the attribute configuration of the connection pool between the
Proxy and the storage node, such as:
+
+```
+ADD RESOURCE resource_2 (
+ HOST=127.0.0.1,
+ PORT=3306,
+ DB=db2,
+ USER=root,
+ PASSWORD=root,
+ PROPERTIES("maximumPoolSize"=10)
+),resource_3 (
+ URL="jdbc:mysql://127.0.0.1:3306/db3?serverTimezone=UTC&useSSL=false",
+ USER=root,
+ PASSWORD=root,
+ PROPERTIES("maximumPoolSize"=10,"idleTimeout"="30000")
+);
+```
+💡 Note: Specifying JDBC connection parameters, such as `useSSL`, is supported
only with URL form.
+
+`ALTER RESOURCE`
+
+`ALTER RESOURCE` is used to modify the connection information of storage
nodes, such as changing the size of a connection pool, modifying JDBC
connection parameters, etc.
+
+Syntactically, `ALTER RESOURCE` is identical to `ADD RESOURCE`.
+
+```
+ALTER RESOURCE resource_2 (
+ HOST=127.0.0.1,
+ PORT=3306,
+ DB=db2,
+ USER=root,
+ PROPERTIES("maximumPoolSize"=50)
+),resource_3 (
+ URL="jdbc:mysql://127.0.0.1:3306/db3?serverTimezone=GMT&useSSL=false",
+ USER=root,
+ PASSWORD=root,
+ PROPERTIES("maximumPoolSize"=50,"idleTimeout"="30000")
+);
+```
+💡 Note: Since modifying the storage node may cause metadata changes or
application data exceptions, `ALTER RESOURCE` cannot used to modify the target
database of the connection. Only the following values can be modified:
+
+- User name
+- User password
+- `PROPERTIES` connection pool parameters
+- JDBC parameters
+
+`DROP RESOURCE`
+
+`DROP RESOURCE` is used to delete storage nodes from a schema without deleting
any data in the storage node. The statement example is as follows:
+
+`DROP RESOURCE resource_0, resource_1;`
+
+💡 Note: In order to ensure data correctness, the storage node referenced by
the rule cannot be deleted.
+
+`t_order` is a sharding table, and its actual tables are distributed in
`resource_0` and `resource_1`. When `resource_0` and `resource_1` are
referenced by `t_order` sharding rules, they cannot be deleted.
+
+`SHOW SCHEMA RESOURCES`
+
+`SHOW SCHEMA RESOURCES` is used to query storage nodes in schemas and supports
the following syntax forms:
+
+```
+#Query the storage node in the current schema
+SHOW SCHEMA RESOURCES;
+#Query the storage node in the specified schema
+SHOW SCHEMA RESOURCES FROM sharding_db;
+```
+
+Example:
+
+Add 4 storage nodes through the above-mentioned `ADD RESOURCE` command, and
then execute a query:
+
+
+
+> There are actually a large number of columns in the query result, but here
we only show part of it.
+
+Above we have introduced you to the ways to dynamically manage storage nodes
through DistSQL.
+
+Compared with modifying YAML files, exectuting DistSQL statements is
real-time, and there is no need to restart the Proxy or compute node, making
online operations safer.
+
+Changes executed through DistSQL can be synchronized to other compute nodes in
the cluster in real time through the register center, while the client
connected to any compute node can also query changes of storage nodes in real
time.
+
+Apache ShardingSphere’s cluster governance is very powerful.
+
+## Conclusion
+If you have any questions or suggestions about Apache ShardingSphere, please
open an issue on the GitHub issue list. If you are interested in contributing
to the project, you’re very welcome to join the Apache ShardingSphere community.
+
+GitHub issue:https://github.com/apache/shardingsphere/issues
+
+Issues · apache/shardingsphere
+New issue Have a question about this project? Sign up for a free GitHub
account to open an issue and contact its…
+github.com
+
+## Reference
+**1. ShardingSphere-Proxy Quickstart:
**[https://shardingsphere.apache.org/document/5.1.0/cn/quick-start/shardingsphere-proxy-quick-start/](https://shardingsphere.apache.org/document/5.1.0/en/quick-start/shardingsphere-proxy-quick-start/)
+
+**2.DistSQL
RDL:**https://shardingsphere.apache.org/document/current/en/user-manual/shardingsphere-proxy/distsql/syntax/rdl/resource-definition/
+
+**3.DistSQL
RQL:**https://shardingsphere.apache.org/document/current/en/user-manual/shardingsphere-proxy/distsql/syntax/rql/resource-query/
+
+**4.DistSQL
RAL:**https://shardingsphere.apache.org/document/current/en/user-manual/shardingsphere-proxy/distsql/syntax/ral/
+
+**Apache ShardingSphere Project Links:**
+[ShardingSphere
Github](https://github.com/apache/shardingsphere/issues?page=1&q=is%3Aopen+is%3Aissue+label%3A%22project%3A+OpenForce+2022%22)
+
+[ShardingSphere Twitter](https://twitter.com/ShardingSphere)
+
+[ShardingSphere
Slack](https://join.slack.com/t/apacheshardingsphere/shared_invite/zt-sbdde7ie-SjDqo9~I4rYcR18bq0SYTg)
+
+[Contributor Guide](https://shardingsphere.apache.org/community/cn/contribute/)
+
+**Authors**
+**Longtao JIANG**
+
+SphereEx Middleware Development Engineer & Apache ShardingSphere Committer
+
+Jiang works on DistSQL and security features R&D.
+
+**Chengxiang Lan**
+
+SphereEx Middleware Development Engineer & Apache ShardingSphere Committer
+
+Lan contributes to DistSQL’s R&D.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}