hanahmily commented on code in PR #435: URL: https://github.com/apache/skywalking-banyandb/pull/435#discussion_r1573927014
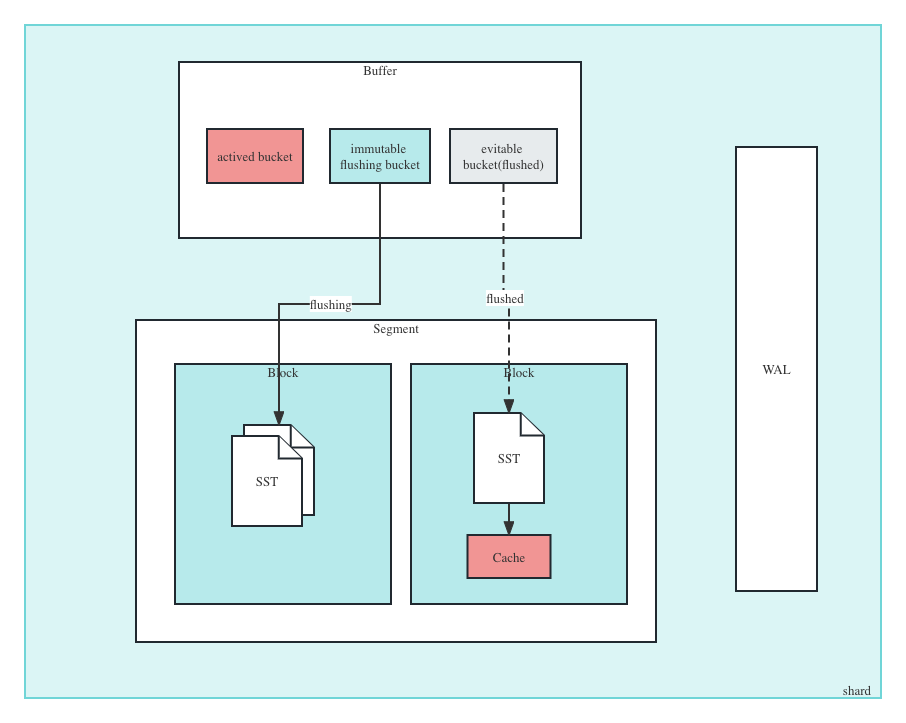
########## docs/concept/tsdb.md: ########## @@ -2,18 +2,37 @@ TSDB is a time-series storage engine designed to store and query large volumes of time-series data. One of the key features of TSDB is its ability to automatically manage data storage over time, optimize performance and ensure that the system can scale to handle large workloads. TSDB empowers `Measure` and `Stream` relevant data. - ## Shard In TSDB, the data in a group is partitioned into shards based on a configurable sharding scheme. Each shard is assigned to a specific set of storage nodes, and those nodes store and process the data within that shard. This allows BanyanDB to scale horizontally by adding more storage nodes to the cluster as needed. +Within each shard, data is stored in different segments based on time ranges. The primary index generated based on entities and the indexes generated based on indexing rules of the `Measure` types are also stored under the shard. Review Comment: ```suggestion Within each shard, data is stored in different segments based on time ranges. The series index generated based on entities, and the indexes generated based on indexing rules of the `Measure` types are also stored under the shard. ``` ########## docs/concept/tsdb.md: ########## @@ -2,18 +2,37 @@ TSDB is a time-series storage engine designed to store and query large volumes of time-series data. One of the key features of TSDB is its ability to automatically manage data storage over time, optimize performance and ensure that the system can scale to handle large workloads. TSDB empowers `Measure` and `Stream` relevant data. - ## Shard In TSDB, the data in a group is partitioned into shards based on a configurable sharding scheme. Each shard is assigned to a specific set of storage nodes, and those nodes store and process the data within that shard. This allows BanyanDB to scale horizontally by adding more storage nodes to the cluster as needed. +Within each shard, data is stored in different segments based on time ranges. The primary index generated based on entities and the indexes generated based on indexing rules of the `Measure` types are also stored under the shard. + +[shard](https://skywalking.apache.org/doc-graph/banyandb/v0.6.0/shard.png) + +## Segment + +Each segment is composed of multiple parts. Whenever SkyWalking sends a batch of data, BanyanDB writes this batch of data into a new Part. For data of the `Stream` type, the inverted indexes and LSM indexes generated based on the indexing rules are also stored in the segment. Since BanyanDB adopts a snapshot approach for data read and write operations, the segment also needs to maintain additional snapshot information to record the validity of the parts. + +[segment](https://skywalking.apache.org/doc-graph/banyandb/v0.6.0/segment.png) + +## Part + +Within a part, data is split into multiple files in a columnar manner. The timestamps are stored in the `timestamps.bin` file, tags are organized as multiple files with the `.tf` suffix using column families, and fields are stored separately in the `fields.bin` file. + +In addition, each part maintains several metadata files. Among them, `metadata.json` is the metadata file for the part, storing descriptive information about the part. The `meta.bin` file serves as the entry file for the entire part, helping to index the `primary.bin` file. Through the `primary.bin` file, the actual data files or the tagFamily metadata files ending with `.tfm` can be indexed, which in turn helps locate the tag data. Review Comment: ```suggestion In addition, each part maintains several metadata files. Among them, `metadata.json` is the metadata file for the part, storing descriptive information, such as start and end times, part size and etc. The `meta.bin` is a skipping index file serves as the entry file for the entire part, helping to index the `primary.bin` file. The `primary.bin` file contains the index of each block. Through it, the actual data files or the tagFamily metadata files ending with `.tfm` can be indexed, which in turn helps locate the data in blocks. ``` ########## docs/concept/tsdb.md: ########## @@ -2,18 +2,37 @@ TSDB is a time-series storage engine designed to store and query large volumes of time-series data. One of the key features of TSDB is its ability to automatically manage data storage over time, optimize performance and ensure that the system can scale to handle large workloads. TSDB empowers `Measure` and `Stream` relevant data. - ## Shard In TSDB, the data in a group is partitioned into shards based on a configurable sharding scheme. Each shard is assigned to a specific set of storage nodes, and those nodes store and process the data within that shard. This allows BanyanDB to scale horizontally by adding more storage nodes to the cluster as needed. +Within each shard, data is stored in different segments based on time ranges. The primary index generated based on entities and the indexes generated based on indexing rules of the `Measure` types are also stored under the shard. + +[shard](https://skywalking.apache.org/doc-graph/banyandb/v0.6.0/shard.png) + +## Segment + +Each segment is composed of multiple parts. Whenever SkyWalking sends a batch of data, BanyanDB writes this batch of data into a new Part. For data of the `Stream` type, the inverted indexes and LSM indexes generated based on the indexing rules are also stored in the segment. Since BanyanDB adopts a snapshot approach for data read and write operations, the segment also needs to maintain additional snapshot information to record the validity of the parts. + +[segment](https://skywalking.apache.org/doc-graph/banyandb/v0.6.0/segment.png) Review Comment: ```suggestion 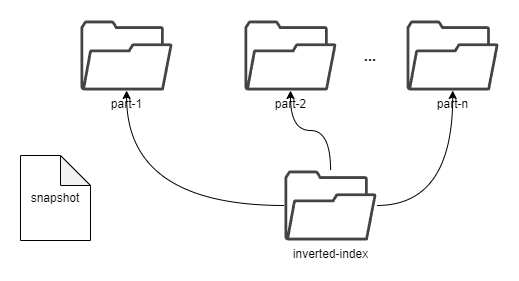 ``` Can you please remove the lsm index? This is because the stream no longer supports this type of index. ########## docs/concept/tsdb.md: ########## @@ -2,18 +2,37 @@ TSDB is a time-series storage engine designed to store and query large volumes of time-series data. One of the key features of TSDB is its ability to automatically manage data storage over time, optimize performance and ensure that the system can scale to handle large workloads. TSDB empowers `Measure` and `Stream` relevant data. - ## Shard In TSDB, the data in a group is partitioned into shards based on a configurable sharding scheme. Each shard is assigned to a specific set of storage nodes, and those nodes store and process the data within that shard. This allows BanyanDB to scale horizontally by adding more storage nodes to the cluster as needed. +Within each shard, data is stored in different segments based on time ranges. The primary index generated based on entities and the indexes generated based on indexing rules of the `Measure` types are also stored under the shard. + +[shard](https://skywalking.apache.org/doc-graph/banyandb/v0.6.0/shard.png) + +## Segment + +Each segment is composed of multiple parts. Whenever SkyWalking sends a batch of data, BanyanDB writes this batch of data into a new Part. For data of the `Stream` type, the inverted indexes and LSM indexes generated based on the indexing rules are also stored in the segment. Since BanyanDB adopts a snapshot approach for data read and write operations, the segment also needs to maintain additional snapshot information to record the validity of the parts. Review Comment: ```suggestion Each segment is composed of multiple parts. Whenever SkyWalking sends a batch of data, BanyanDB writes this batch of data into a new Part. For data of the `Stream` type, the inverted indexes generated based on the indexing rules are also stored in the segment. Since BanyanDB adopts a snapshot approach for data read and write operations, the segment also needs to maintain additional snapshot information to record the validity of the parts. ``` ########## docs/concept/tsdb.md: ########## @@ -2,18 +2,37 @@ TSDB is a time-series storage engine designed to store and query large volumes of time-series data. One of the key features of TSDB is its ability to automatically manage data storage over time, optimize performance and ensure that the system can scale to handle large workloads. TSDB empowers `Measure` and `Stream` relevant data. - ## Shard In TSDB, the data in a group is partitioned into shards based on a configurable sharding scheme. Each shard is assigned to a specific set of storage nodes, and those nodes store and process the data within that shard. This allows BanyanDB to scale horizontally by adding more storage nodes to the cluster as needed. +Within each shard, data is stored in different segments based on time ranges. The primary index generated based on entities and the indexes generated based on indexing rules of the `Measure` types are also stored under the shard. + +[shard](https://skywalking.apache.org/doc-graph/banyandb/v0.6.0/shard.png) + +## Segment + +Each segment is composed of multiple parts. Whenever SkyWalking sends a batch of data, BanyanDB writes this batch of data into a new Part. For data of the `Stream` type, the inverted indexes and LSM indexes generated based on the indexing rules are also stored in the segment. Since BanyanDB adopts a snapshot approach for data read and write operations, the segment also needs to maintain additional snapshot information to record the validity of the parts. + +[segment](https://skywalking.apache.org/doc-graph/banyandb/v0.6.0/segment.png) + +## Part + +Within a part, data is split into multiple files in a columnar manner. The timestamps are stored in the `timestamps.bin` file, tags are organized as multiple files with the `.tf` suffix using column families, and fields are stored separately in the `fields.bin` file. + +In addition, each part maintains several metadata files. Among them, `metadata.json` is the metadata file for the part, storing descriptive information about the part. The `meta.bin` file serves as the entry file for the entire part, helping to index the `primary.bin` file. Through the `primary.bin` file, the actual data files or the tagFamily metadata files ending with `.tfm` can be indexed, which in turn helps locate the tag data. + +Notably, for data of the `Stream` type, since there are no field columns, the `fields.bin` file does not exist, while the rest of the structure is entirely consistent with the `Measure` type. + +[measure-part](https://skywalking.apache.org/doc-graph/banyandb/v0.6.0/measure-part.png) +[stream-part](https://skywalking.apache.org/doc-graph/banyandb/v0.6.0/stream-part.png) + +## Block -[shard](https://skywalking.apache.org/doc-graph/banyandb/v0.4.0/tsdb-shard.png) +The figure below shows the detailed fields within each block. It is worth noting that when storing tag and field data, BanyanDB prioritizes storing data points or elements with the same tag consecutively. This helps improve the compression efficiency of the files. -* Buffer: It is typically implemented as an in-memory queue managed by a shard. When new time-series data is ingested into the system, it is added to the end of the queue, and when the buffer reaches a specific size, the data is flushed to disk in batches. -* SST: When a bucket of buffer becomes full or reaches a certain size threshold, it is flushed to disk as a new Sorted String Table (SST) file. This process is known as compaction. -* Segments and Blocks: Time-series data is stored in data segments/blocks within each shard. Blocks contain a fixed number of data points and are organized into time windows. Each data segment includes an index that efficiently retrieves data within the block. -* Block Cache: It manages the in-memory cache of data blocks, improving query performance by caching frequently accessed data blocks in memory. +[measure-block](https://skywalking.apache.org/doc-graph/banyandb/v0.6.0/measure-block.png) +[stream-block](https://skywalking.apache.org/doc-graph/banyandb/v0.6.0/stream-block.png) ## Write Path Review Comment: Write and read path should be updated accordingly. ########## docs/concept/tsdb.md: ########## @@ -2,18 +2,37 @@ TSDB is a time-series storage engine designed to store and query large volumes of time-series data. One of the key features of TSDB is its ability to automatically manage data storage over time, optimize performance and ensure that the system can scale to handle large workloads. TSDB empowers `Measure` and `Stream` relevant data. - ## Shard In TSDB, the data in a group is partitioned into shards based on a configurable sharding scheme. Each shard is assigned to a specific set of storage nodes, and those nodes store and process the data within that shard. This allows BanyanDB to scale horizontally by adding more storage nodes to the cluster as needed. +Within each shard, data is stored in different segments based on time ranges. The primary index generated based on entities and the indexes generated based on indexing rules of the `Measure` types are also stored under the shard. + +[shard](https://skywalking.apache.org/doc-graph/banyandb/v0.6.0/shard.png) Review Comment: ```suggestion 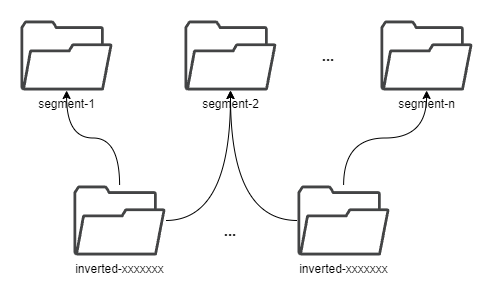 ``` ########## docs/concept/tsdb.md: ########## @@ -2,18 +2,37 @@ TSDB is a time-series storage engine designed to store and query large volumes of time-series data. One of the key features of TSDB is its ability to automatically manage data storage over time, optimize performance and ensure that the system can scale to handle large workloads. TSDB empowers `Measure` and `Stream` relevant data. - ## Shard In TSDB, the data in a group is partitioned into shards based on a configurable sharding scheme. Each shard is assigned to a specific set of storage nodes, and those nodes store and process the data within that shard. This allows BanyanDB to scale horizontally by adding more storage nodes to the cluster as needed. +Within each shard, data is stored in different segments based on time ranges. The primary index generated based on entities and the indexes generated based on indexing rules of the `Measure` types are also stored under the shard. + +[shard](https://skywalking.apache.org/doc-graph/banyandb/v0.6.0/shard.png) + +## Segment + +Each segment is composed of multiple parts. Whenever SkyWalking sends a batch of data, BanyanDB writes this batch of data into a new Part. For data of the `Stream` type, the inverted indexes and LSM indexes generated based on the indexing rules are also stored in the segment. Since BanyanDB adopts a snapshot approach for data read and write operations, the segment also needs to maintain additional snapshot information to record the validity of the parts. + +[segment](https://skywalking.apache.org/doc-graph/banyandb/v0.6.0/segment.png) + +## Part + +Within a part, data is split into multiple files in a columnar manner. The timestamps are stored in the `timestamps.bin` file, tags are organized as multiple files with the `.tf` suffix using column families, and fields are stored separately in the `fields.bin` file. + +In addition, each part maintains several metadata files. Among them, `metadata.json` is the metadata file for the part, storing descriptive information about the part. The `meta.bin` file serves as the entry file for the entire part, helping to index the `primary.bin` file. Through the `primary.bin` file, the actual data files or the tagFamily metadata files ending with `.tfm` can be indexed, which in turn helps locate the tag data. + +Notably, for data of the `Stream` type, since there are no field columns, the `fields.bin` file does not exist, while the rest of the structure is entirely consistent with the `Measure` type. + +[measure-part](https://skywalking.apache.org/doc-graph/banyandb/v0.6.0/measure-part.png) +[stream-part](https://skywalking.apache.org/doc-graph/banyandb/v0.6.0/stream-part.png) + +## Block -[shard](https://skywalking.apache.org/doc-graph/banyandb/v0.4.0/tsdb-shard.png) +The figure below shows the detailed fields within each block. It is worth noting that when storing tag and field data, BanyanDB prioritizes storing data points or elements with the same tag consecutively. This helps improve the compression efficiency of the files. -* Buffer: It is typically implemented as an in-memory queue managed by a shard. When new time-series data is ingested into the system, it is added to the end of the queue, and when the buffer reaches a specific size, the data is flushed to disk in batches. -* SST: When a bucket of buffer becomes full or reaches a certain size threshold, it is flushed to disk as a new Sorted String Table (SST) file. This process is known as compaction. -* Segments and Blocks: Time-series data is stored in data segments/blocks within each shard. Blocks contain a fixed number of data points and are organized into time windows. Each data segment includes an index that efficiently retrieves data within the block. -* Block Cache: It manages the in-memory cache of data blocks, improving query performance by caching frequently accessed data blocks in memory. +[measure-block](https://skywalking.apache.org/doc-graph/banyandb/v0.6.0/measure-block.png) +[stream-block](https://skywalking.apache.org/doc-graph/banyandb/v0.6.0/stream-block.png) Review Comment: ```suggestion 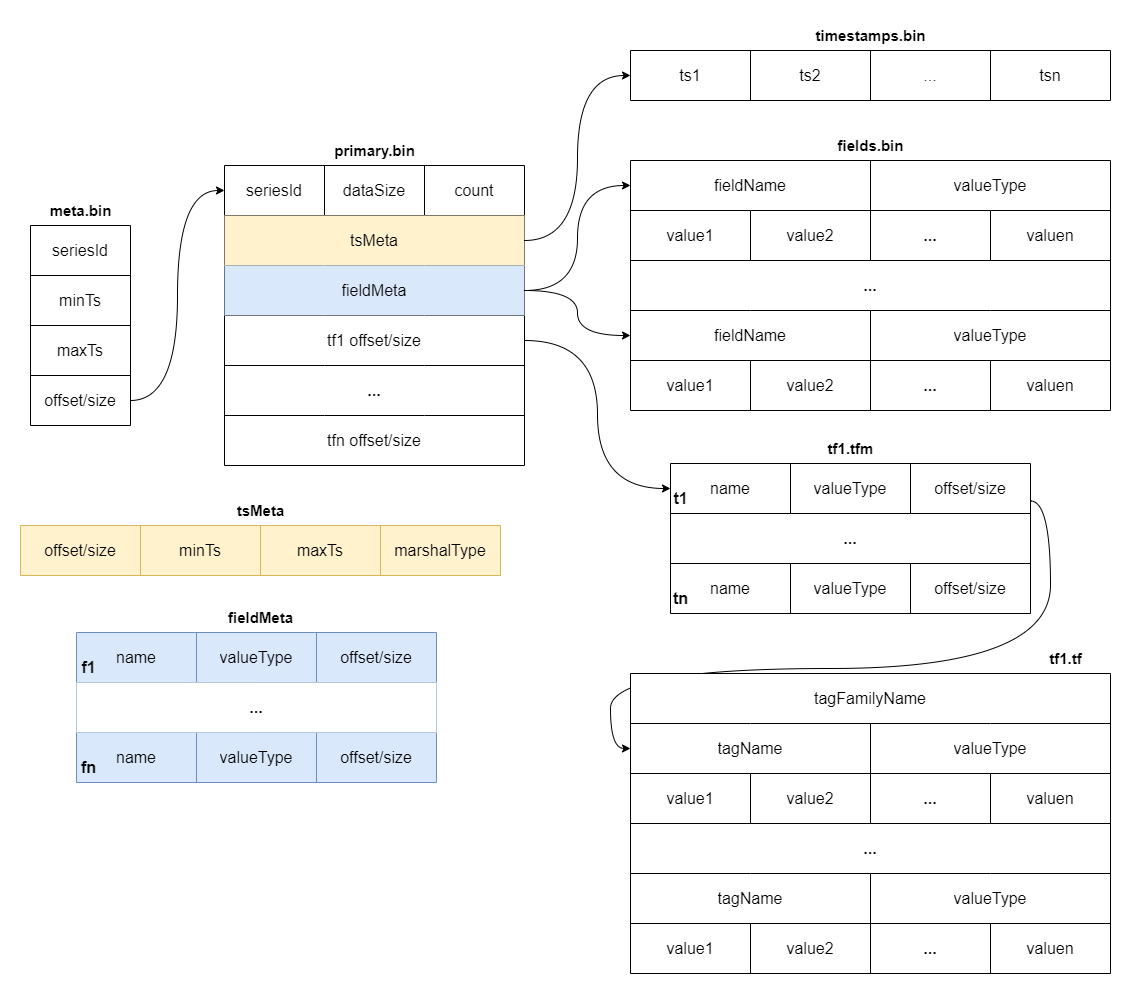 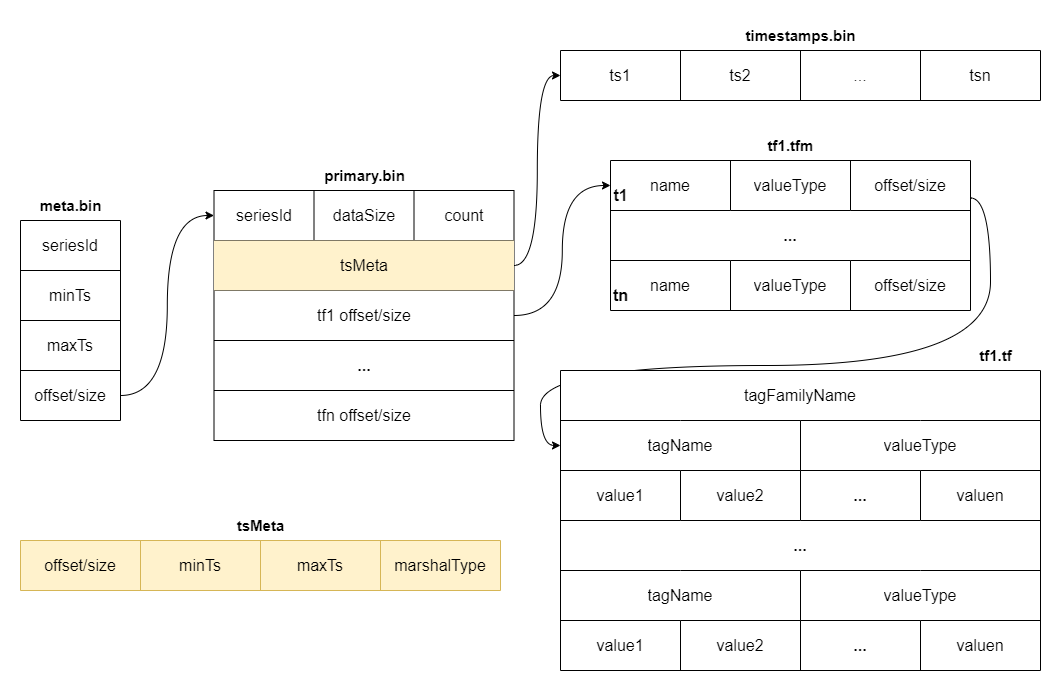 ``` ########## docs/concept/tsdb.md: ########## @@ -2,18 +2,37 @@ TSDB is a time-series storage engine designed to store and query large volumes of time-series data. One of the key features of TSDB is its ability to automatically manage data storage over time, optimize performance and ensure that the system can scale to handle large workloads. TSDB empowers `Measure` and `Stream` relevant data. - ## Shard In TSDB, the data in a group is partitioned into shards based on a configurable sharding scheme. Each shard is assigned to a specific set of storage nodes, and those nodes store and process the data within that shard. This allows BanyanDB to scale horizontally by adding more storage nodes to the cluster as needed. +Within each shard, data is stored in different segments based on time ranges. The primary index generated based on entities and the indexes generated based on indexing rules of the `Measure` types are also stored under the shard. + +[shard](https://skywalking.apache.org/doc-graph/banyandb/v0.6.0/shard.png) + +## Segment + +Each segment is composed of multiple parts. Whenever SkyWalking sends a batch of data, BanyanDB writes this batch of data into a new Part. For data of the `Stream` type, the inverted indexes and LSM indexes generated based on the indexing rules are also stored in the segment. Since BanyanDB adopts a snapshot approach for data read and write operations, the segment also needs to maintain additional snapshot information to record the validity of the parts. + +[segment](https://skywalking.apache.org/doc-graph/banyandb/v0.6.0/segment.png) + +## Part + +Within a part, data is split into multiple files in a columnar manner. The timestamps are stored in the `timestamps.bin` file, tags are organized as multiple files with the `.tf` suffix using column families, and fields are stored separately in the `fields.bin` file. Review Comment: ```suggestion Within a part, data is split into multiple files in a columnar manner. The timestamps are stored in the `timestamps.bin` file, tags are organized in persistent tag families as various files with the `.tf` suffix, and fields are stored separately in the `fields.bin` file. ``` ########## docs/concept/tsdb.md: ########## @@ -2,18 +2,37 @@ TSDB is a time-series storage engine designed to store and query large volumes of time-series data. One of the key features of TSDB is its ability to automatically manage data storage over time, optimize performance and ensure that the system can scale to handle large workloads. TSDB empowers `Measure` and `Stream` relevant data. - ## Shard In TSDB, the data in a group is partitioned into shards based on a configurable sharding scheme. Each shard is assigned to a specific set of storage nodes, and those nodes store and process the data within that shard. This allows BanyanDB to scale horizontally by adding more storage nodes to the cluster as needed. +Within each shard, data is stored in different segments based on time ranges. The primary index generated based on entities and the indexes generated based on indexing rules of the `Measure` types are also stored under the shard. + +[shard](https://skywalking.apache.org/doc-graph/banyandb/v0.6.0/shard.png) Review Comment: Please rename the "inverted-index" folder to "idx-xxxxxxx". The "xxxxxxx" represents the hexadecimal creation time of the index. There may be multiple idx folders during index rotation. You ought to show the multiple folders in the diagram. ########## docs/concept/tsdb.md: ########## @@ -2,18 +2,37 @@ TSDB is a time-series storage engine designed to store and query large volumes of time-series data. One of the key features of TSDB is its ability to automatically manage data storage over time, optimize performance and ensure that the system can scale to handle large workloads. TSDB empowers `Measure` and `Stream` relevant data. - ## Shard In TSDB, the data in a group is partitioned into shards based on a configurable sharding scheme. Each shard is assigned to a specific set of storage nodes, and those nodes store and process the data within that shard. This allows BanyanDB to scale horizontally by adding more storage nodes to the cluster as needed. +Within each shard, data is stored in different segments based on time ranges. The primary index generated based on entities and the indexes generated based on indexing rules of the `Measure` types are also stored under the shard. + +[shard](https://skywalking.apache.org/doc-graph/banyandb/v0.6.0/shard.png) + +## Segment + +Each segment is composed of multiple parts. Whenever SkyWalking sends a batch of data, BanyanDB writes this batch of data into a new Part. For data of the `Stream` type, the inverted indexes and LSM indexes generated based on the indexing rules are also stored in the segment. Since BanyanDB adopts a snapshot approach for data read and write operations, the segment also needs to maintain additional snapshot information to record the validity of the parts. + +[segment](https://skywalking.apache.org/doc-graph/banyandb/v0.6.0/segment.png) + +## Part + +Within a part, data is split into multiple files in a columnar manner. The timestamps are stored in the `timestamps.bin` file, tags are organized as multiple files with the `.tf` suffix using column families, and fields are stored separately in the `fields.bin` file. + +In addition, each part maintains several metadata files. Among them, `metadata.json` is the metadata file for the part, storing descriptive information about the part. The `meta.bin` file serves as the entry file for the entire part, helping to index the `primary.bin` file. Through the `primary.bin` file, the actual data files or the tagFamily metadata files ending with `.tfm` can be indexed, which in turn helps locate the tag data. + +Notably, for data of the `Stream` type, since there are no field columns, the `fields.bin` file does not exist, while the rest of the structure is entirely consistent with the `Measure` type. + +[measure-part](https://skywalking.apache.org/doc-graph/banyandb/v0.6.0/measure-part.png) +[stream-part](https://skywalking.apache.org/doc-graph/banyandb/v0.6.0/stream-part.png) + +## Block -[shard](https://skywalking.apache.org/doc-graph/banyandb/v0.4.0/tsdb-shard.png) +The figure below shows the detailed fields within each block. It is worth noting that when storing tag and field data, BanyanDB prioritizes storing data points or elements with the same tag consecutively. This helps improve the compression efficiency of the files. Review Comment: ```suggestion The diagram below shows the detailed fields within each block. The block is the minimal unit of tsdb, which contains several rows of data. Due to the column-base design, each block is spread over several files. ``` ########## docs/concept/tsdb.md: ########## @@ -2,18 +2,37 @@ TSDB is a time-series storage engine designed to store and query large volumes of time-series data. One of the key features of TSDB is its ability to automatically manage data storage over time, optimize performance and ensure that the system can scale to handle large workloads. TSDB empowers `Measure` and `Stream` relevant data. - ## Shard In TSDB, the data in a group is partitioned into shards based on a configurable sharding scheme. Each shard is assigned to a specific set of storage nodes, and those nodes store and process the data within that shard. This allows BanyanDB to scale horizontally by adding more storage nodes to the cluster as needed. +Within each shard, data is stored in different segments based on time ranges. The primary index generated based on entities and the indexes generated based on indexing rules of the `Measure` types are also stored under the shard. + +[shard](https://skywalking.apache.org/doc-graph/banyandb/v0.6.0/shard.png) + +## Segment + +Each segment is composed of multiple parts. Whenever SkyWalking sends a batch of data, BanyanDB writes this batch of data into a new Part. For data of the `Stream` type, the inverted indexes and LSM indexes generated based on the indexing rules are also stored in the segment. Since BanyanDB adopts a snapshot approach for data read and write operations, the segment also needs to maintain additional snapshot information to record the validity of the parts. + +[segment](https://skywalking.apache.org/doc-graph/banyandb/v0.6.0/segment.png) + +## Part + +Within a part, data is split into multiple files in a columnar manner. The timestamps are stored in the `timestamps.bin` file, tags are organized as multiple files with the `.tf` suffix using column families, and fields are stored separately in the `fields.bin` file. + +In addition, each part maintains several metadata files. Among them, `metadata.json` is the metadata file for the part, storing descriptive information about the part. The `meta.bin` file serves as the entry file for the entire part, helping to index the `primary.bin` file. Through the `primary.bin` file, the actual data files or the tagFamily metadata files ending with `.tfm` can be indexed, which in turn helps locate the tag data. + +Notably, for data of the `Stream` type, since there are no field columns, the `fields.bin` file does not exist, while the rest of the structure is entirely consistent with the `Measure` type. + +[measure-part](https://skywalking.apache.org/doc-graph/banyandb/v0.6.0/measure-part.png) +[stream-part](https://skywalking.apache.org/doc-graph/banyandb/v0.6.0/stream-part.png) Review Comment: ```suggestion 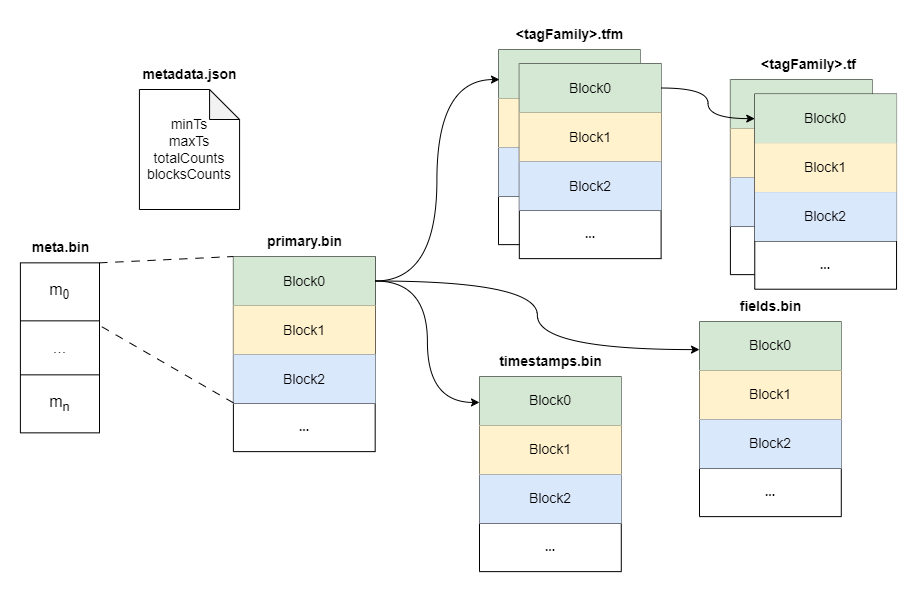 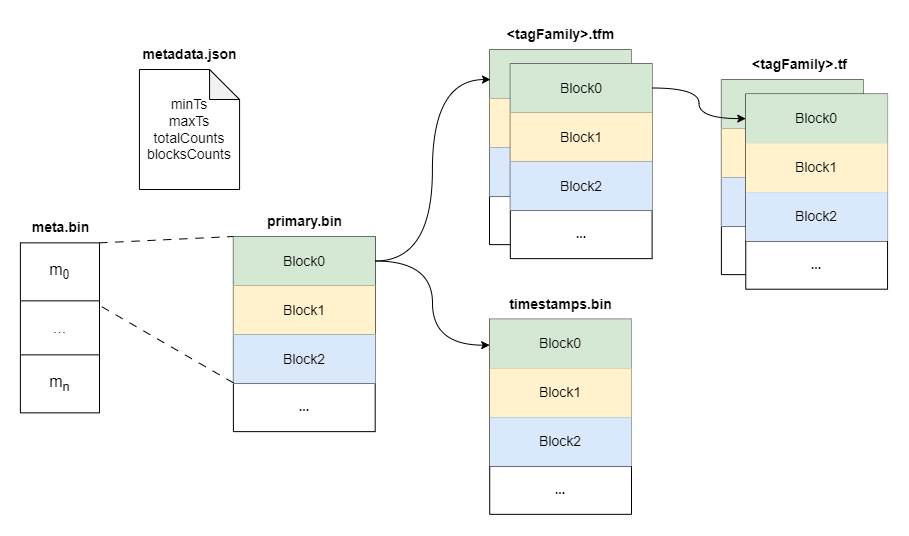 ``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}