This is an automated email from the ASF dual-hosted git repository. hanahmily pushed a commit to branch storage-ttl in repository https://gitbox.apache.org/repos/asf/skywalking-banyandb.git
commit 481a205ee6f6ad7364e09d8bca739f7d11bb68da Author: Gao Hongtao <[email protected]> AuthorDate: Tue Jul 23 08:43:22 2024 +0800 Update the tsdb.md to represent the latest structure Signed-off-by: Gao Hongtao <[email protected]> --- docs/concept/tsdb.md | 24 +++++++++++++++--------- 1 file changed, 15 insertions(+), 9 deletions(-) diff --git a/docs/concept/tsdb.md b/docs/concept/tsdb.md index e6505a43..59e9dd11 100644 --- a/docs/concept/tsdb.md +++ b/docs/concept/tsdb.md @@ -2,19 +2,21 @@ TSDB is a time-series storage engine designed to store and query large volumes of time-series data. One of the key features of TSDB is its ability to automatically manage data storage over time, optimize performance and ensure that the system can scale to handle large workloads. TSDB empowers `Measure` and `Stream` relevant data. -## Shard + -In TSDB, the data in a group is partitioned into shards based on a configurable sharding scheme. Each shard is assigned to a specific set of storage nodes, and those nodes store and process the data within that shard. This allows BanyanDB to scale horizontally by adding more storage nodes to the cluster as needed. +## Segment -Within each shard, data is stored in different [segments](#Segment) based on time ranges. The series indexes are generated based on entities, and the indexes generated based on indexing rules of the `Measure` types are also stored under the shard. +In TSDB, the data in a group is partitioned base on the time range of the data. The segment size is determined by the `segment_interval` of a group. The number of segments in a group is determined by the `ttl` of a group. A new segment is created when the written data exceeds the time range of the current segment. The expired segment will be deleted after the `ttl` of the group. -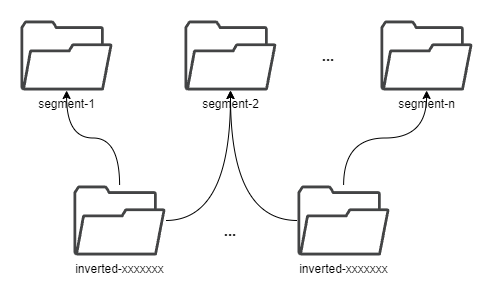 +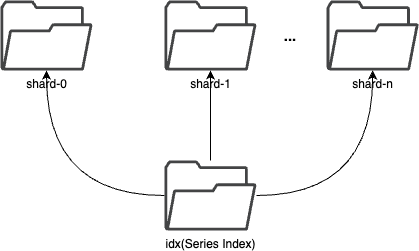 -## Segment +## Shard -Each segment is composed of multiple [parts](#Part). Whenever SkyWalking sends a batch of data, BanyanDB writes this batch of data into a new part. For data of the `Stream` type, the inverted indexes generated based on the indexing rules are also stored in the segment. Since BanyanDB adopts a snapshot approach for data read and write operations, the segment also needs to maintain additional snapshot information to record the validity of the parts. +In each segment, the data is spread into shards based on `entity`. Each shard is assigned to a specific set of storage nodes, and those nodes store and process the data within that shard. This allows BanyanDB to scale horizontally by adding more storage nodes to the cluster as needed. -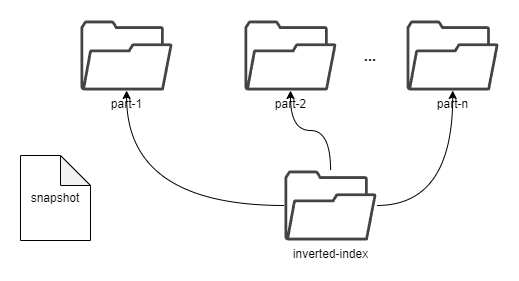 +Each shard is composed of multiple [parts](#Part). Whenever SkyWalking sends a batch of data, BanyanDB writes this batch of data into a new part. For data of the `Stream` type, the inverted indexes generated based on the indexing rules are also stored in the segment. Since BanyanDB adopts a snapshot approach for data read and write operations, the segment also needs to maintain additional snapshot information to record the validity of the parts. + +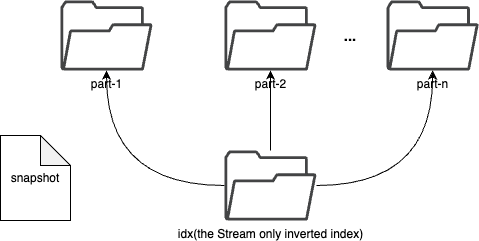 ## Part @@ -37,8 +39,12 @@ Each block holds data with the same series ID. The max size of the measure block is controlled by data volume and the number of rows. Meanwhile, the max size of the stream block is controlled by data volume. The diagram below shows the detailed fields within each block. The block is the minimal unit of TSDB, which contains several rows of data. Due to the column-based design, each block is spread over several files. -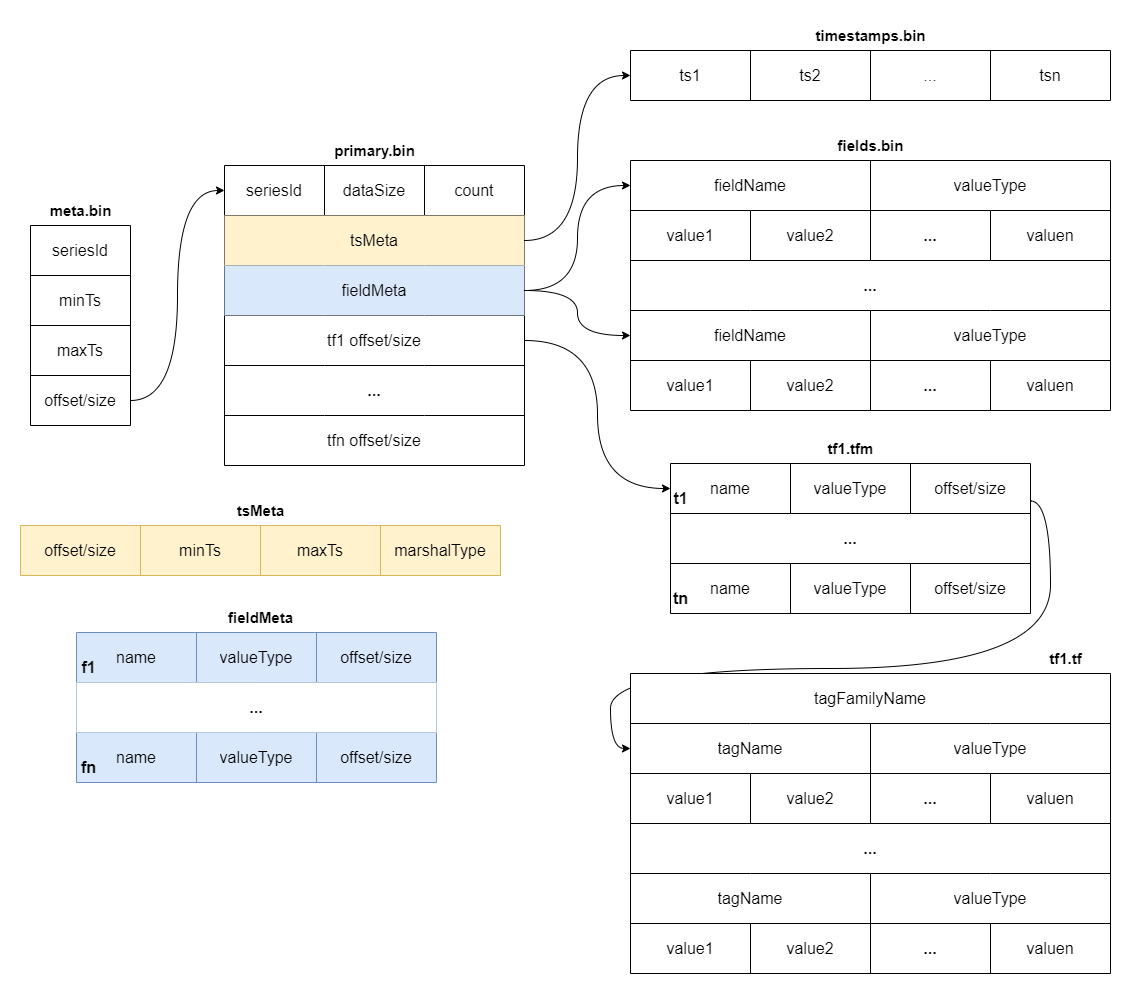 -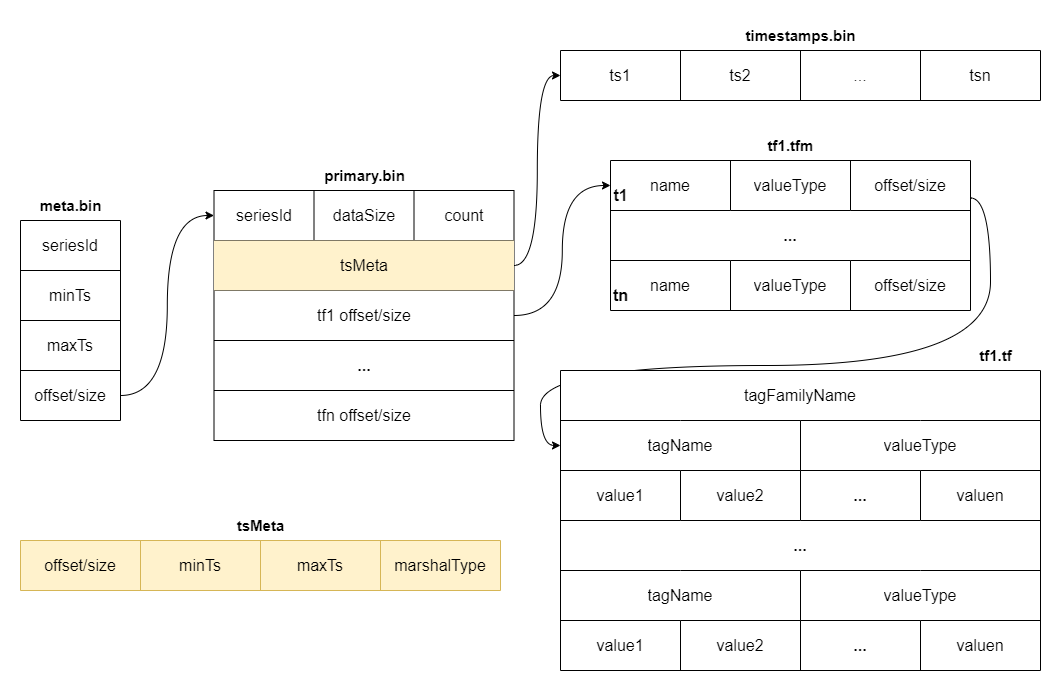 +In measure's timestamp file, there are version fields to record the version of the data. The version field is used to deduplicate. It determine the latest data when the data's timestamp are identical. Only the latest data will be returned to the user. + +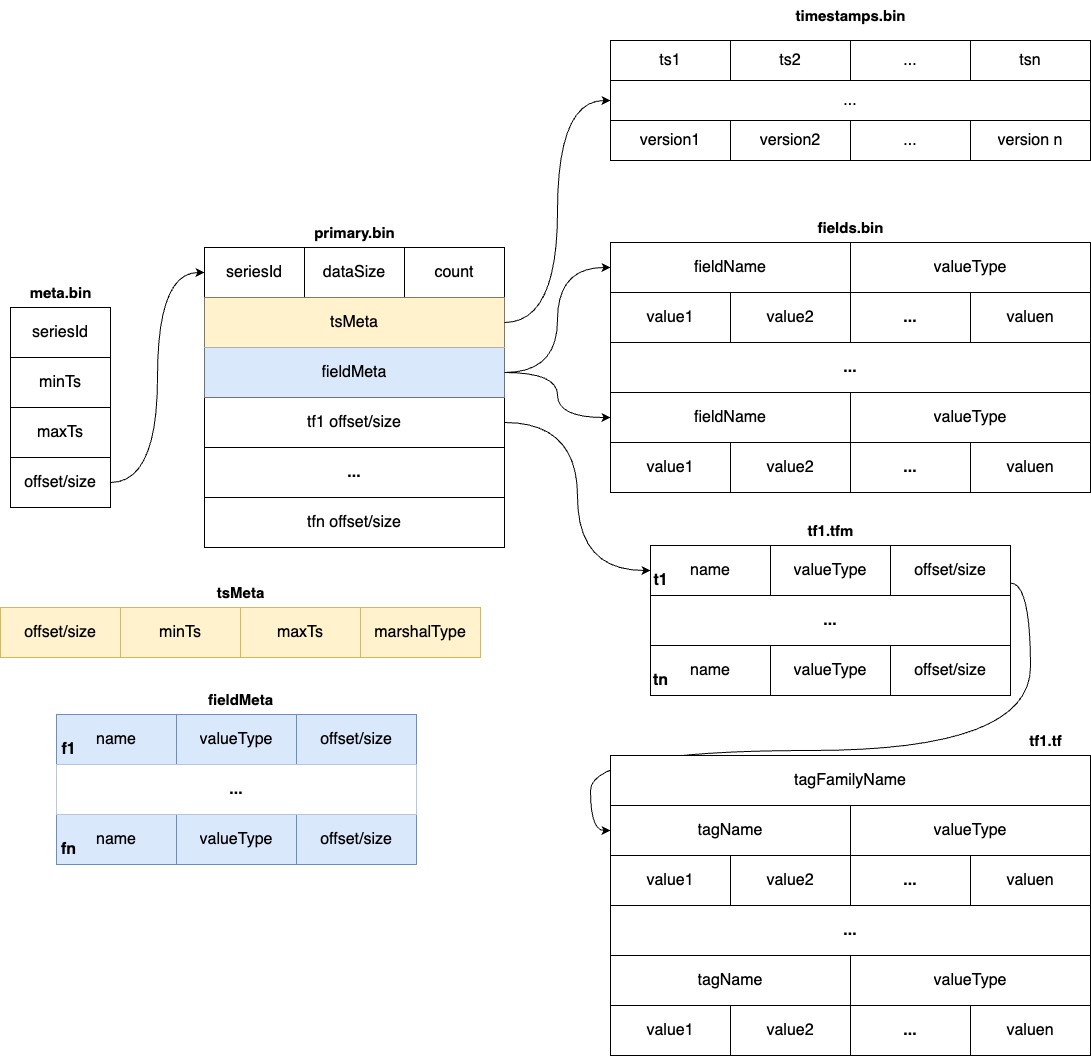 + +Unlike the measure, there are element ids in the stream's timestamp file. The element id is used to identify the data of the same series. The data with the same timestamp but different element id will both be stored in the TSDB. +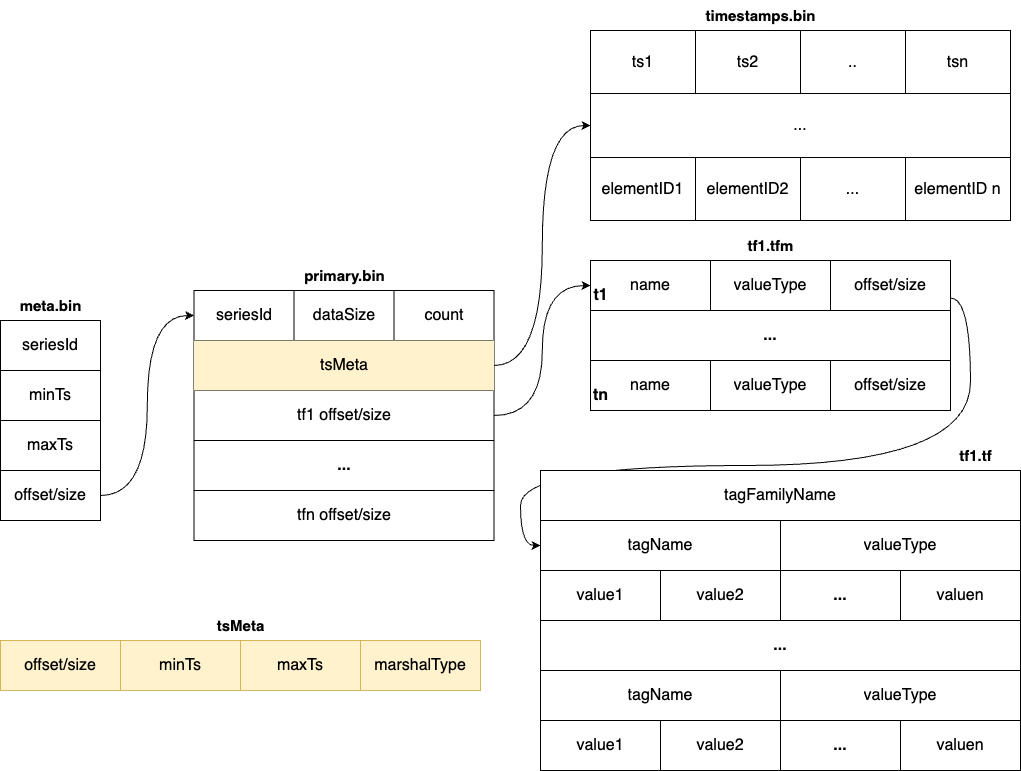 ## Write Path
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}