This is an automated email from the ASF dual-hosted git repository.
hanahmily pushed a commit to branch main
in repository https://gitbox.apache.org/repos/asf/skywalking-banyandb.git
The following commit(s) were added to refs/heads/main by this push:
new 3aec74264 docs: make storage/file-format docs code-accurate and add
API-first reference (#1158)
3aec74264 is described below
commit 3aec74264689b17d1bc46a00c6ae3f88a6c7744f
Author: 吴晟 Wu Sheng <[email protected]>
AuthorDate: Fri Jun 5 19:04:53 2026 +0800
docs: make storage/file-format docs code-accurate and add API-first
reference (#1158)
Cross-checked every storage/file-format claim in the docs against the
code (code is the source of truth) and fixed the discrepancies, then
added a new code-accurate, API-first reference.
Corrections (code-verified):
- On-disk hierarchy is group -> segment -> shard -> part. Fixed the
inverted order in tsdb.md, data-model.md, clustering.md and
disk-management.md (including the `dump` CLI path examples).
- Measure field-values file is `fv.bin`, not `fields.bin`.
- `GORILLA`/`ZSTD` are schema-level enums; the columnar engine encodes
with delta/delta-of-delta/dictionary and applies zstd by size
threshold. The Gorilla XOR encoder is unused. Clarified in
data-model.md and the new doc.
- Stream tag columns are encoded (delta/dictionary); "no encoding" was
misleading.
- Stream inverted index maps terms to element IDs (not timestamps).
- Documented the measure `index_mode` two-engine split (columnar parts
vs inverted-index-only) behind one identical API.
- Documented the trace span store (`spans.bin`, `<tag>.t`/`.tm`,
`tag.type`, `traceID.filter`) and the embedded sidx ordered index;
trace has no per-tag block-skip filter.
- Property is a Bluge document store (no segment/time dimension),
mutable via append + tombstone with a per-segment deleted drop-set;
fixed the repair Merkle-tree SHA input (delete timestamp, not a
boolean) and the snapshot-id change-detection state (state.json).
New doc:
- docs/concept/storage-and-format.md: an API-first storage & file-format
reference (two storage families; hierarchy and part lifecycle; measure
[two modes] + TopN; stream; trace + sidx; property; shared encoding
primitives; distributed chunked-sync wire format; failed-parts).
Diagrams:
- Replaced the file-structure PNGs with inline mermaid (and refreshed
the data-model structure diagram to include Trace).
Docs-only change; no source or generated files affected.
Co-authored-by: Claude Opus 4.8 (1M context) <[email protected]>
Co-authored-by: Gao Hongtao <[email protected]>
---
CHANGES.md | 4 +
docs/concept/clustering.md | 2 +-
docs/concept/data-model.md | 28 ++-
docs/concept/property-repair.md | 19 +-
docs/concept/storage-and-format.md | 489 +++++++++++++++++++++++++++++++++++++
docs/concept/tsdb.md | 181 ++++++++++----
docs/menu.yml | 2 +
docs/operation/disk-management.md | 10 +-
8 files changed, 661 insertions(+), 74 deletions(-)
diff --git a/CHANGES.md b/CHANGES.md
index d2c866352..5f9f312f5 100644
--- a/CHANGES.md
+++ b/CHANGES.md
@@ -108,6 +108,10 @@ Release Notes.
- Fix FODC proxy corrupting Prometheus metric types. The agent dropped the `#
TYPE` line while parsing banyandb `/metrics`, the `StreamMetrics` proto carried
no type field, and the proxy guessed the type from a name-suffix heuristic —
downgrading counters to gauge, mislabeling `_count`-suffixed counters as
histograms, and splitting summaries into two conflicting `# TYPE` lines.
Capture the type with the Prometheus `expfmt` parser, store it in the flight
recorder, thread it through a new [...]
- Fix FODC agent labeling metrics with `node_role="ROLE_UNSPECIFIED"`. The
agent resolved the node role exactly once at startup via a single
`GetCurrentNode` poll whose endpoint retries spanned only ~1s; when the sibling
lifecycle/banyandb gRPC server was not yet listening (`connect: cannot assign
requested address`) the role fell back to `ROLE_UNSPECIFIED` permanently, so
most nodes never reported their real `ROLE_DATA`/`ROLE_LIAISON`. Retry the
initial node-role resolution with exponen [...]
+### Document
+
+- Add a code-accurate, API-first "Storage & File Format" doc and correct stale
storage/format descriptions: fix the on-disk hierarchy to `group → segment →
shard → part` (in `tsdb.md`, `data-model.md`, `clustering.md`,
`disk-management.md`, including the `dump` CLI path examples), correct the
measure field-values file name (`fv.bin`, not `fields.bin`), clarify that the
`GORILLA`/`ZSTD` enums are schema hints (the engine uses delta/dictionary +
size-thresholded zstd), document the measure [...]
+
### Chores
- Upgrade Go and npm dependencies including etcd to v3.6.10, OpenTelemetry to
v1.43.0, AWS SDK, and Google Cloud libraries.
diff --git a/docs/concept/clustering.md b/docs/concept/clustering.md
index 8bfce2cac..0cb095e55 100644
--- a/docs/concept/clustering.md
+++ b/docs/concept/clustering.md
@@ -63,7 +63,7 @@ Liaison Nodes use this metadata to dynamically determine
shard-to-node assignmen
### 3.2 Data Nodes
-Data Nodes store all raw time series data, metadata, and indexed data. On
disk, the data is organized by `<group>/shard-<shard_id>/<segment_id>/`. The
segment is designed to support retention policy.
+Data Nodes store all raw time series data, metadata, and indexed data. For
time-series resources (`Measure`, `Stream`, `Trace`), the data is organized on
disk by `<group>/<segment>/shard-<shard_id>/<part>/`, where the segment is a
time bucket that supports the retention policy. `Property` data has no time
segment — it is organized by `<group>/shard-<shard_id>/` directly. See [Storage
& File Format](storage-and-format.md) for details.
### 3.3 Liaison Nodes
diff --git a/docs/concept/data-model.md b/docs/concept/data-model.md
index a379f79c9..a0ea30c85 100644
--- a/docs/concept/data-model.md
+++ b/docs/concept/data-model.md
@@ -12,7 +12,16 @@ You can also find [examples](../interacting/bydbctl/schema)
of how to interact w
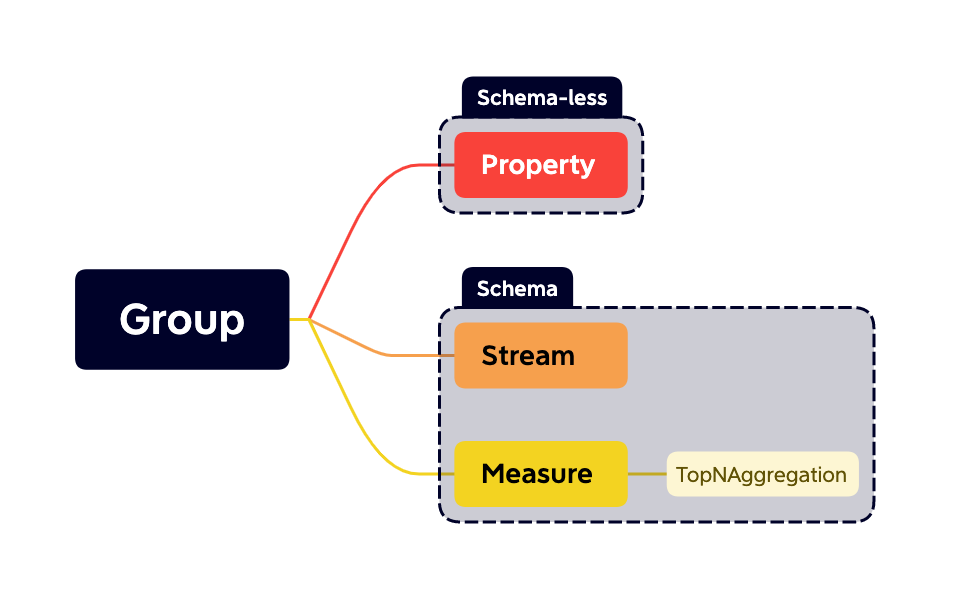
The hierarchy that data is organized into **streams**, **measures**,
**traces** and **properties** in groups.
-
+```mermaid
+flowchart LR
+ G["Group"] --> P["Property (schema-less)"]
+ G --> S["Stream"]
+ G --> M["Measure"]
+ G --> T["Trace"]
+ M --> TN["TopNAggregation"]
+```
+
+A group's `catalog` fixes which one kind of resource it holds (`MEASURE`,
`STREAM`, `TRACE`, or `PROPERTY`). For how each resource is physically stored
on disk, see [Storage & File Format](storage-and-format.md).
### Groups
@@ -114,18 +123,19 @@ functions to them.
- **DATA_BINARY** : Raw binary
- **FLOAT** : 64 bits double-precision floating-point number
-`Measure` supports the following encoding methods:
+`Measure` declares the following encoding/compression options on each field:
-- **GORILLA** : GORILLA encoding is lossless. It is more suitable for a
numerical sequence with similar values and is not recommended for sequence data
with large fluctuations.
+- **GORILLA** (`encoding_method`) : a lossless encoding hint for numerical
sequences with similar values.
+- **ZSTD** (`compression_method`) : Zstandard, a real-time compression
algorithm with high compression ratios.
-`Measure` supports the types of the following fields:
+> **How values are actually encoded on disk.** These two enums are
schema-level *hints*; the columnar storage engine selects the concrete encoding
from the value type and data shape, not from the enum. Numeric (`INT`/`FLOAT`)
field columns are delta / delta-of-delta / const encoded with zigzag-varint
(floats are first converted to a decimal-int mantissa + exponent); non-numeric
columns use dictionary or plain encoding. ZSTD is applied generically by a size
threshold (whole index blocks a [...]
-- **ZSTD** : Zstandard is a real-time compression algorithm, that provides
high compression ratios. It offers a very wide range of compression/speed
trade-offs, while being backed by a very fast decoder. For BanyanDB focus on
speed.
-
-Another option named `interval` plays a critical role in encoding. It
indicates the time range between two adjacent data points in a time series and
implies that all data points belonging to the same time series are distributed
based on a fixed interval. A better practice for the naming measure is to
append the interval literal to the tail, for example, `service_cpm_minute`.
It's a parameter of `GORILLA` encoding method.
+Another option named `interval` indicates the time range between two adjacent
data points in a time series and implies that all data points belonging to the
same time series are distributed based on a fixed interval. A better practice
for naming a measure is to append the interval literal to the tail, for
example, `service_cpm_minute`.
`index_mode` is a flag to enable the series index as the storage engine. All
the tags will be stored in the inverted index and no field is allowed in the
measure. This mode is suitable for the non-time series data model but needs TTL
to be set. In this mode, the tags defined in the `entity` is the unique key of
the data point. `timestamp` and `version` are the common tags in the inverted
index.
+> **Same API, two storage engines.** `index_mode` is the single switch that
swaps the entire storage engine behind the *same* `Measure` schema and the
*same* `Write`/`Query` RPCs. With `index_mode: false`, values are stored as
columnar parts (the TSDB engine); with `index_mode: true`, no columnar part is
written at all — the whole data point is stored as a document in the inverted
index. The flag is effectively immutable once data exists (flipping it would
orphan previously-written data) [...]
+
There is an example of a measure with the index mode enabled:
```yaml
@@ -184,7 +194,7 @@ Tags in `group_by_tag_names` are used as dimensions. These
tags can be searched
### Streams
-`Stream` shares many details with `Measure` except for abandoning `field`.
Stream focuses on high throughput data collection, for example, logging. The
database engine also supports compressing stream entries based on `entity`, but
no encoding process is involved.
+`Stream` shares many details with `Measure` except for abandoning `field`.
Stream focuses on high throughput data collection, for example, logging. Like
Measure, the engine encodes and compresses a stream's tag columns
(delta/dictionary encoding plus zstd for large byte payloads); what Stream
lacks is *fields* (and therefore Measure's field-level encoding), not encoding
altogether. See [Storage & File Format →
Stream](storage-and-format.md#4-stream).
[Stream Registration Operations](../api-reference.md#streamregistryservice)
@@ -245,7 +255,7 @@ Each span also carries a raw `span` field (binary), which
stores the original sp
### Properties
-A `Property` is a schema-less (or schema-free) document, stored using a
distributed inverted index for efficient tag-based queries. Unlike Measures,
Streams and Traces, Properties support a more flexible key structure:
`group`/`name`/`id`.
+A `Property` is a mutable document keyed by `group`/`name`/`id`, stored using
a distributed inverted index for efficient tag-based queries. A tag-type
contract is registered once via the Property registry, but values are flexible.
Unlike Measures, Streams and Traces, a Property is **not** a time series: it
has no timestamp/segment dimension and `segment_interval`/`ttl` do not apply;
updates overwrite by `ModRevision` (last-writer-wins) and deletes are soft
(tombstoned, reclaimed lazily a [...]
We should create a group before creating a property.
diff --git a/docs/concept/property-repair.md b/docs/concept/property-repair.md
index 1c9c20500..fb8242ee6 100644
--- a/docs/concept/property-repair.md
+++ b/docs/concept/property-repair.md
@@ -20,10 +20,10 @@ In the context of property data, each shard within a group
builds its own Merkle
The tree consists of the following three types of nodes:
1. **Leaf Node**: Store the summary information of each Property data:
1. **Entity**: The identifier of the Property data, composed of
`group_name` + `property_name` + `id`.
- 2. **SHA Value**: The SHA512 hash value of the Property source
data(`sha512(source_json_bytes+property_is_deleted)`), used for fast equality
comparison to check the consistency of the same entity data
+ 2. **SHA Value**: The SHA512 hash value of the Property source
data(`sha512(source_json_bytes + delete_time)`, where `delete_time` is the
int64 nanosecond delete timestamp, or `0` when the property is not deleted),
used for fast equality comparison to check the consistency of the same entity
data. Encoding the actual delete time (rather than a boolean flag) means two
records deleted at different times produce different SHAs.
2. **Slot Node**: Each tree contains a fixed number(such as `32`) of slot
nodes. When the Property data is added into the tree, it is placed in a slot
node based on its hash value of Entity(`hash(entity) % slot_count`).
- The slot node contains the SHA value of the Property data and the number of
Property data in that slot.
-3. **Root Node**: The root node of the Merkle Tree, which contains the SHA
value of the entire tree and the number of slot nodes.
+ The slot node's SHA is computed over the (hex-encoded) SHA values of its
leaf nodes, and it records the number of Property data in that slot.
+3. **Root Node**: The root node of the Merkle Tree, whose SHA is computed over
the (hex-encoded) SHA values of all slot nodes; it also records the number of
slot nodes.
Therefore, the Merkle Tree has above three structure levels:
* The top level is a single root node.
@@ -37,11 +37,20 @@ There are two types of triggers for Merkle Tree
construction:
2. **On Update**: When an update in the shard is detected, the system
schedules a delayed build after a short wait period (default 10 minutes).
The construction process follows these steps:
-1. **Check for Updates**: The system compares the snapshot ID(`XXXXX.snp`) of
the previously built tree with the current snapshot ID of the shard.
+1. **Check for Updates**: The system compares the snapshot ID recorded from
the previous build (persisted in `state.json` as `last_snp_id`) with the
shard's current latest snapshot ID (the newest `.snp` file in the shard's Bluge
index directory).
If they differ, it indicates that data has changed, and the process
continues. If they match, the tree construction is skipped.
2. **Snapshot the Shard**: A snapshot of the shard data is taken to avoid
blocking ongoing business operations during data traversal.
3. **Build the Tree**: Using the streaming method, the system scans all data
in the snapshot and builds a Merkle Tree for each group individually.
-4. **Save the Snapshot ID**: The snapshot ID used in this build is saved, so
it can be used for efficient change detection during the next scheduled run.
+4. **Save the Snapshot ID**: The snapshot ID used in this build is saved (to
`state.json`), so it can be used for efficient change detection during the next
scheduled run.
+
+### On-disk State
+
+Repair state is persisted under a dedicated repair base directory (separate
from the Bluge data files), laid out per group/shard:
+
+- `state.json` — `{last_sync_time, last_snp_id}`, the change-detection marker
described above.
+- `state-tree.data` — the persisted Merkle Tree (a custom self-describing
format: a section of leaf nodes, then slot nodes, then the root node, followed
by a trailing footer with section offsets).
+- `state-append-<slot>.tmp` — transient per-slot spill files used while
composing the tree; concatenated into `state-tree.data` and then removed.
+- `scheduled.json` — a marker recording that a build-tree run has occurred
(used to disambiguate gossip emptiness).
## Gossip Protocol
diff --git a/docs/concept/storage-and-format.md
b/docs/concept/storage-and-format.md
new file mode 100644
index 000000000..288f507c1
--- /dev/null
+++ b/docs/concept/storage-and-format.md
@@ -0,0 +1,489 @@
+# Storage & File Format
+
+This document describes how BanyanDB physically stores data on disk, organized
**from the API perspective**: for each resource a user creates (`Measure`,
`Stream`, `Trace`, `Property`, `TopNAggregation`), it explains the API surface
first, then the storage engine(s) that actually back it.
+
+The central idea to keep in mind:
+
+> **The API unifies what the storage separates.** A single API resource can be
backed by completely different storage engines. The clearest example is
`Measure`: one schema, one write RPC, one query RPC — but a single boolean flag
(`index_mode`) silently swaps the entire on-disk engine. This document makes
those hidden forks explicit.
+
+Everything here is derived from the source code. Where a diagram or older
document disagrees with the code, the code wins.
+
+> **Convention used below:** `<016x>` means a 16-digit zero-padded lowercase
hex string (e.g. `000000000000001f`); `<012x>` means 12-digit. These are how
part/segment epoch IDs appear as directory and file names.
+
+---
+
+## 1. Two storage families
+
+Despite five API resources, there are only **two** physical storage engines
underneath.
+
+| Family | Backs | On disk | Mutability |
+| --- | --- | --- | --- |
+| **Columnar TSDB** (BanyanDB-native) | `Measure` (normal mode), `Stream`,
`Trace` (span store) | per-part column files (`*.bin`, `*.tf`, `*.t`, …) inside
epoch-named part directories | append-only — immutable parts, mem → flush →
merge |
+| **Inverted index** (third-party [Bluge](https://github.com/blugelabs/bluge)
+ ICE segments) | `Property`, `Measure` (index-mode), and the **series index**
used by every TSDB engine | Lucene-style `*.seg` / `*.snp` segment files |
mutable — new document + tombstone bitmap, GC at merge |
+
+So the five resources really decompose into **3 columnar + 2 inverted-index**
uses, plus the **sidx** ordered secondary-index store that `Trace` embeds.
+
+The columnar engines store values **by column** for compression and projection
efficiency. The inverted-index engines store whole **documents** and are
searched by term — they are used either as a pure index (series resolution,
stream indexed tags) or, surprisingly, as a primary store (`Property`,
index-mode `Measure`).
+
+---
+
+## 2. The shared directory skeleton (TSDB)
+
+`Measure`, `Stream`, and `Trace` all share the same directory skeleton,
managed by `banyand/internal/storage`. The substrate owns the directory tree
and lifecycle; each engine injects its own per-part column format.
+
+```
+<data-path>/<group>/
+├── lock # advisory flock for the whole group's
TSDB
+└── seg-<YYYYMMDD|YYYYMMDDHH>/ # SEGMENT = a time bucket (the
rotation/retention unit)
+ ├── metadata #
{"version":"1.5.0","endTime":"<RFC3339Nano>"} (JSON)
+ ├── sidx/ # per-SEGMENT series inverted index
(Bluge) — shared by all shards
+ └── shard-<N>/ # SHARD lives *inside* the segment
+ ├── <016x>/ # PART (one immutable flush/merge
output)
+ │ └── … columnar files …
+ ├── <016x>.snp # snapshot manifest = JSON array of
live part dir names
+ ├── idx/ # STREAM only: per-shard element
inverted index (Bluge)
+ └── sidx/<ruleName>/<016x>/ # TRACE only: ordered
secondary-index parts (one tree per index rule)
+```
+
+```mermaid
+flowchart TD
+ G["group/ (lock)"] --> S1["seg-20240901/"]
+ G --> S2["seg-20240902/"]
+ S1 --> M["metadata (JSON: version, endTime)"]
+ S1 --> SIDX["sidx/ — segment series index (Bluge)"]
+ S1 --> SH0["shard-0/"]
+ S1 --> SH1["shard-1/"]
+ SH0 --> P1["000…001/ (part)"]
+ SH0 --> P2["000…002/ (part)"]
+ SH0 --> SNP["000…002.snp (snapshot manifest)"]
+ SH0 --> IDX["idx/ — stream element index (stream only)"]
+ SH0 --> TSX["sidx/<rule>/ — ordered index (trace only)"]
+```
+
+Key facts (verified against `banyand/internal/storage/segment.go`, `shard.go`,
`storage.go`):
+
+- **Hierarchy order is `group → segment → shard → part`.** A `shard-<N>`
directory is created **inside** a `seg-<…>` directory (`segment.openShard`
joins `segment.location` with `shard-<N>`). Older diagrams/prose that draw
`group → shard → segment` are **wrong**.
+- **Segment** directories are named `seg-` + the segment-start time formatted
as `2006010215` (hour granularity) or `20060102` (day granularity), chosen by
the group's `segment_interval` unit.
+- **Part** directories are named `<016x>` of a monotonically increasing epoch.
A part is immutable once written.
+- **Snapshot (MVCC):** `<016x>.snp` is a JSON array listing which part
directories are *live* at that epoch. Readers only see parts in the current
snapshot; a part dropped from the snapshot is GC'd at the next flush/merge. The
newest `.snp` (highest epoch) is the current one.
+- The **segment-level `sidx/`** is the *series index* (a Bluge inverted
index). Note the **name collision**: `Trace` also has a `sidx/` directory, but
at the **shard** level and with a completely different meaning (ordered
secondary index, see §6). Same name, different depth, different engine.
+
+`Property` does **not** use this skeleton — see §7.
+
+### 2.1 Part lifecycle
+
+```mermaid
+flowchart LR
+ W["write batch"] --> MP["memory part (in RAM)"]
+ MP -->|flush| DP["disk part <016x>/"]
+ DP -->|merge| MG["merged part (drops invalid rows)"]
+ MP -.->|snapshot update| SNP[".snp manifest"]
+ DP -.-> SNP
+ MG -.-> SNP
+```
+
+Every batch write becomes a memory part. A background worker flushes it to a
disk part; flushing triggers a merge that combines parts and removes data no
longer referenced by the snapshot. Each of these events writes a new `.snp` and
deletes stale ones.
+
+---
+
+## 3. Measure
+
+`Measure` is the headline example of "one API, two engines."
+
+### 3.1 The Measure resource (API)
+
+A user registers a `Measure` schema
(`api/proto/banyandb/database/v1/schema.proto`, message `Measure`):
+
+| Field | Meaning |
+| --- | --- |
+| `tag_families` | named groups of tags (the dimensions); each tag has a type
(STRING/INT/STRING_ARRAY/INT_ARRAY/DATA_BINARY) |
+| `fields` | the numeric measure values; each has `field_type`,
`encoding_method`, `compression_method` |
+| `entity` | the subset of tags forming the **series key** (and default shard
key) |
+| `sharding_key` | optional explicit shard key (defaults to `entity`) |
+| `interval` | nominal data-point cadence (e.g. `1m`) |
+| **`index_mode`** | **the boolean that selects the storage engine** (field 7)
|
+
+Data is written and read with the same two RPCs regardless of mode:
+
+- **Write** — `MeasureService.Write` (bidi stream of
`DataPointValue{timestamp, tag_families, fields, version}`).
+- **Query** — `MeasureService.Query` (`time_range`, `criteria`,
`tag_projection`, `field_projection`, `group_by`, `agg`, `top`, `order_by`, …).
+
+Crucially, **the liaison (coordinator) write path never inspects
`index_mode`** — it just hashes the entity to a shard and forwards. The engine
fork happens only on the data node.
+
+### 3.2 One API, two storage engines
+
+```mermaid
+flowchart TD
+ API["Measure schema + Write/Query RPC (identical)"] --> FLAG{"index_mode?"}
+ FLAG -->|false| COL["Mode A: columnar tsTable parts<br/>(+ metadata docs
in series index)"]
+ FLAG -->|true| INV["Mode B: inverted index only<br/>(whole data point as a
document)"]
+```
+
+`index_mode` is set once at schema creation and is effectively **immutable for
the data's lifetime**: flipping it would orphan everything previously written
in the other engine (this is an operational caveat, not a code-enforced check).
Field-encoding options, part compaction, and TopN derivation apply only to
**Mode A**.
+
+### 3.3 Mode A — normal columnar (`index_mode = false`)
+
+Field/tag values are stored **by column** in immutable parts. The series index
holds only a lightweight metadata document per series (for series-ID
resolution); the *values* live in the part.
+
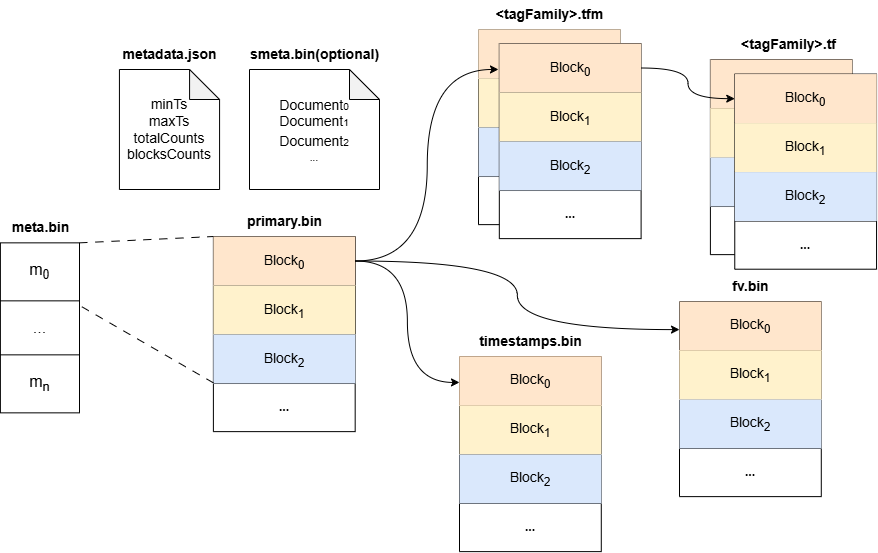
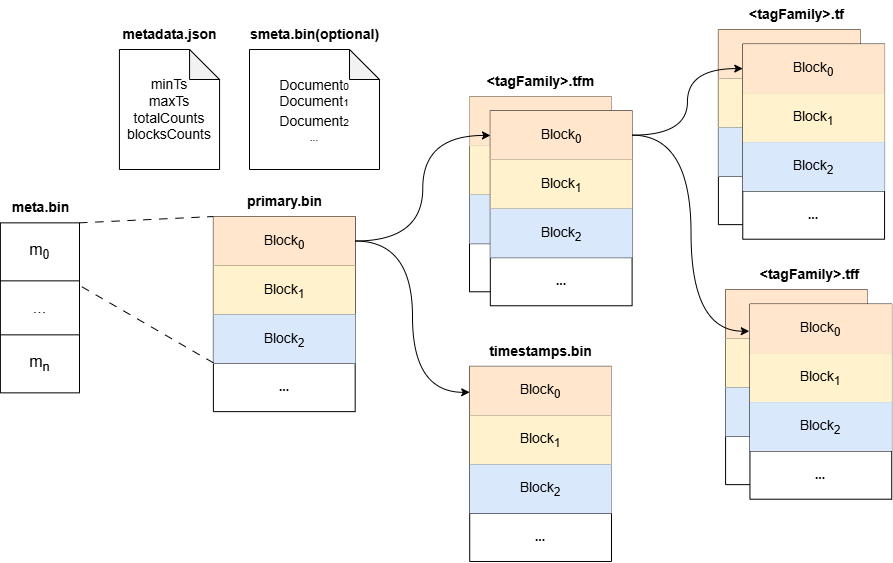
+**Part files** (`banyand/measure/part.go`):
+
+| File | Holds | Format |
+| --- | --- | --- |
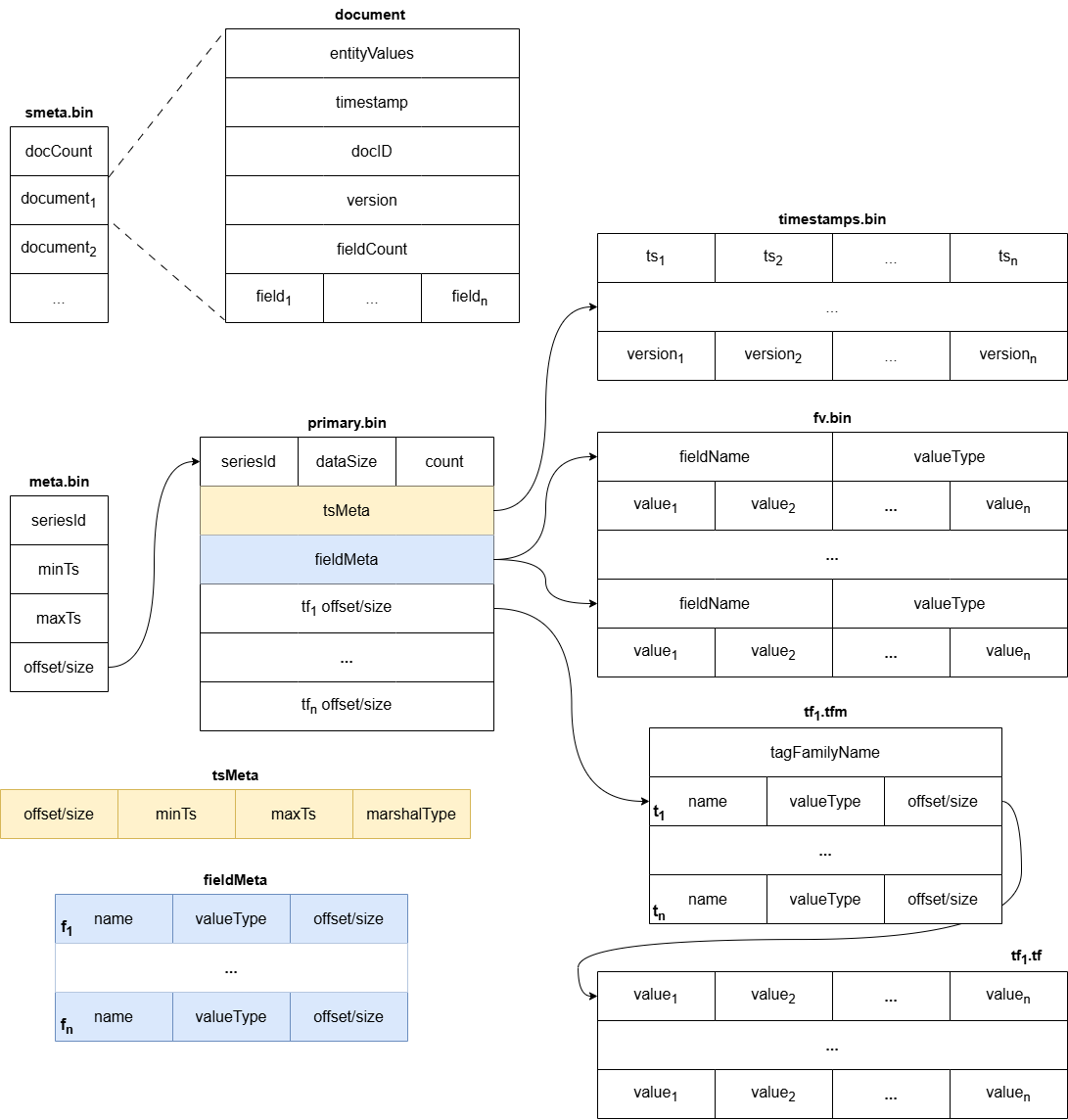
+| `metadata.json` | per-part stats | JSON: `{compressedSizeBytes,
uncompressedSizeBytes, totalCount, blocksCount, minTimestamp, maxTimestamp}`.
The part ID is the directory name, not stored in the JSON. |
+| `meta.bin` | index of primary blocks | zstd stream of fixed **40-byte**
`primaryBlockMetadata` records: `seriesID(8 BE) + minTimestamp(8) +
maxTimestamp(8) + offset(8) + size(8)`, sorted ascending by seriesID |
+| `primary.bin` | per-block index (`blockMetadata`) | sequence of
independently zstd-compressed "primary blocks" (~128 KiB uncompressed each),
each a run of `blockMetadata` records pointing into the data files |
+| `timestamps.bin` | timestamps **+ versions** | per block: `[encoded
timestamps][encoded versions]`; delta/zigzag, no zstd at this layer |
+| `fv.bin` | **all field-value columns** | per (block, field) a
self-describing encoded run (see §8). *Note: the file is `fv.bin`, not
`fields.bin`.* |
+| `<tagFamily>.tf` | tag value columns for one family | one file per tag
family; per (block, tag) encoded run |
+| `<tagFamily>.tfm` | tag column directory for one family | per block: names,
value types, offsets/sizes into the `.tf` |
+| `smeta.bin` | optional series metadata | opaque blob (series docs) for
sync/recovery; absent on older parts |
+
+```mermaid
+flowchart LR
+ META["meta.bin<br/>(40-byte
records:<br/>seriesID,minTs,maxTs,offset,size)"] -->
PRIM["primary.bin<br/>(zstd primary blocks of<br/>blockMetadata)"]
+ PRIM --> TS["timestamps.bin<br/>(ts + version per block)"]
+ PRIM --> FV["fv.bin<br/>(field columns)"]
+ PRIM --> TFM["<family>.tfm<br/>(tag column directory)"]
+ TFM --> TF["<family>.tf<br/>(tag value columns)"]
+```
+
+**Block structure.** A block holds the rows (data points) of **one series
ID**, sorted by timestamp. Within a block, every column is stored contiguously
and addressed by one `blockMetadata` record. Blocks are globally ordered by
`(seriesID asc, minTimestamp asc)`. A `version` is stored alongside each
timestamp; when two rows share a timestamp, only the highest version is
returned (dedup).
+
+**Size caps** (`banyand/measure/measure.go`) — note two distinct enforcement
strategies:
+
+| Cap | Value | Enforced by |
+| --- | --- | --- |
+| `maxUncompressedBlockSize` | 2 MiB | **split** — start a new block |
+| `maxBlockLength` | 8192 rows | **split** |
+| `maxUncompressedPrimaryBlockSize` | 128 KiB | **split** — flush the primary
block |
+| `maxValuesBlockSize` | 8 MiB | **panic** — hard invariant |
+| `maxTagFamiliesMetadataSize` | 8 MiB | **panic** — hard invariant |
+
+A block boundary is also forced whenever the series ID changes.
+
+**Encoding/compression** is shared with the other columnar engines — see §8.
Numeric field/tag columns use delta / delta-of-delta / const + zigzag varint;
non-numeric columns use dictionary encoding (≤256 distinct values) or a plain
bytes block; long byte payloads and the primary/meta indexes are zstd level-1.
+
+**Series index.** On write, a *metadata* document (`seriesID ↔ entity values`)
is inserted into the segment series index (`segment.IndexDB().Insert`). This is
only for series resolution — it does **not** hold field values.
+
+**Write path:** `processDataPoint` → buffer as memory part → on flush,
`tsTable.mustAddDataPoints` (columns) **and** `IndexDB().Insert` (metadata
docs).
+**Query path:** resolve candidate series from the series index → load matching
parts from snapshots → scan blocks for the requested columns/time range →
order/aggregate/top-N.
+
+### 3.4 Mode B — index-mode (`index_mode = true`)
+
+No part is ever written. The **entire** data point — entity tags, tags, and
field values, all as *stored* fields — becomes one document in the segment
series index (Bluge), keyed by series ID with **upsert** (Update) semantics.
+
+```mermaid
+flowchart LR
+ DP["data point"] --> DOC["index.Document (DocID = seriesID)"]
+ DOC --> IDB["segment series index 'sidx/' (Bluge ICE segments)"]
+ NOPART["tsTable parts"]:::x
+ classDef x fill:#fdd,stroke:#900,stroke-dasharray:4
+```
+
+- **Storage:** Bluge `*.seg` / `*.snp` ICE segments under the segment-level
`sidx/`. No columnar part files.
+- **Synthetic fields** added only in this mode: `_im_name` (the measure
subject) and `_im_entity_tag_<tag>` (so entity components are independently
queryable), plus internal `_series_id`, `_timestamp`, `_version`, `_id`.
+- **Write path:** `handleIndexMode` builds the document →
`segment.IndexDB().Update(docs)`. `mustAddDataPoints` is never called.
+- **Query path:** short-circuits to `buildIndexQueryResult` →
`IndexDB().SearchWithoutSeries` — it reads projected stored fields straight out
of the index over a time range and de-dupes by series ID with a roaring bitmap.
There is no series-list pre-resolution and no block scan.
+- **What does NOT apply:** field `encoding_method`/`compression_method`,
columnar block layout, part compaction, and TopN — all of those are Mode-A
concepts. Index-mode segments use Bluge's own S2 compression for stored fields.
+
+Index-mode is intended for low-cardinality, non-time-series-shaped data (e.g.
service traffic / metadata) where every tag should be searchable.
+
+### 3.5 TopNAggregation (derived from a normal-mode measure)
+
+`TopNAggregation` has **no write RPC**. It is materialized from the source
measure's writes:
+
+```mermaid
+flowchart LR
+ SRC["source measure writes"] --> PROC["streaming TopN
processor<br/>(tumbling window + TopN)"]
+ PROC -->|on window flush| RES["_top_n_result measure<br/>(one shared
measure per group)"]
+ RES -->|query| PP["TopN post-processor (re-rank)"]
+ RES -->|merge| PP2["TopN post-processor (bound storage)"]
+```
+
+- Pre-aggregated **at ingest**: each source write is fed through a streaming
flow (tumbling time window + TopN operator). On window flush, the rankings are
published as a normal data point into a single shared result measure named
**`_top_n_result`** (auto-created once per group). Multiple `TopNAggregation`
definitions in a group share this measure, distinguished by a `name` entity tag.
+- Re-ranked **at query** (TopN post-processor merges per-timestamp heaps
across blocks/segments) **and at merge** (to keep stored top-N blocks bounded).
So the stored data is a *candidate set*; the final top-N is computed at read
time.
+- If `field_value_sort` is unspecified, two processors run (ASC and DESC),
distinguished by a `direction` entity tag.
+- The persisted value is a single opaque binary blob (`TopNValue`) holding the
top entities and their int64 values — one blob per (group, window), not one row
per ranked entity.
+
+---
+
+## 4. Stream
+
+### 4.1 The Stream resource (API)
+
+A `Stream` schema (`schema.proto` message `Stream`) has `tag_families` +
`entity` only — **no fields, no interval, no index_mode, no sharding_key**. A
stream stores immutable **elements** (e.g. log entries). Indexing is declared
**out of band** via `IndexRule` + `IndexRuleBinding`, not in the Stream message.
+
+- **Write** — `StreamService.Write` (stream of `ElementValue{element_id,
timestamp, tag_families}`). If `element_id` is set, the storage DocID is
`HashStr("group|name|element_id")`; elements are immutable (never updated).
+- **Query** — `StreamService.Query` (`time_range`, `criteria`, `projection`
(required), `order_by`).
+
+### 4.2 Three physical stores under one resource
+
+A single `Stream` is backed by **three** separate structures, selected
implicitly:
+
+```mermaid
+flowchart TD
+ STR["Stream"] --> COL["columnar parts (element values, by tag family)"]
+ STR --> EIDX["shard-level idx/ — element inverted index (Bluge)"]
+ STR --> SER["segment-level series index (entity → seriesID)"]
+ R["IndexRule type"] -->|INVERTED| EIDX
+ R -->|SKIPPING| BLOOM["in-column bloom filter (.tff)"]
+ R -->|none| COL
+```
+
+1. **Columnar parts** — the element data, structured like Measure's but with
no `fv.bin`:
+
+| File | Difference vs Measure |
+| --- | --- |
+| `metadata.json`, `meta.bin`, `primary.bin` | same roles |
+| `timestamps.bin` | holds timestamps **+ elementIDs** (not versions);
elementIDs are a plain varuint list |
+| `<tagFamily>.tf` / `.tfm` | same roles |
+| `<tagFamily>.tff` | **tag filter file** — per-tag bloom filters for
SKIPPING-indexed tags (new vs Measure) |
+| `smeta.bin` | optional series metadata |
+
+(No `fv.bin` — streams have no fields.) Unlike Measure, rows with the same
timestamp but different `element_id` are **both** stored (no dedup). Stream
defines
`maxUncompressedBlockSize`/`maxValuesBlockSize`/`maxTagFamiliesMetadataSize`/`maxUncompressedPrimaryBlockSize`
but **no `maxBlockLength`** — blocks are cut by size or series change only.
+
+2. **Shard-level element index `idx/`** — a Bluge inverted index mapping
indexed-tag terms → element IDs (with a parallel timestamp posting list). This
resolves `TYPE_INVERTED` predicates and sort-by-tag. (This is the element-level
analogue of the series index, and is **undocumented** in the older `tsdb.md`.)
+
+3. **Segment-level series index** — holds the entity (`seriesID ↔ entity
values`), shared with the other engines.
+
+### 4.3 Index rules map to two different mechanisms
+
+This is the key thing a reader must understand: an `IndexRule`'s `type`
decides *which physical mechanism* a tag gets, and the Stream schema never
mentions it:
+
+- **`TYPE_INVERTED`** → postings in the shard-level `idx/` inverted index
(full inverted index).
+- **`TYPE_SKIPPING`** → **no** inverted index; instead an in-column **bloom
filter** written to `<tagFamily>.tff` (block-level skip).
+- unindexed → plain columnar values only.
+
+### 4.4 Query fork
+
+The same Query RPC dispatches to two executors based on whether
`order_by.index` is set:
+
+- **no `order_by.index`** → time-series scan: read columnar parts filtered by
series ID + time range, using in-column bloom filters for SKIPPING tags.
+- **`order_by.index` set** → indexed query: drive the `idx/` inverted index to
seek/sort element IDs, then fetch projected tag columns from the parts.
+
+---
+
+## 5. Trace
+
+### 5.1 The Trace resource (API)
+
+A `Trace` schema (`schema.proto` message `Trace`) is a **flat list of tags**
(no tag families) plus three special tag-name pointers:
+
+| Field | Role |
+| --- | --- |
+| `trace_id_tag_name` | the tag holding the trace ID — **both the shard key**
(`Hash(traceID) % shards`) **and the span store's primary key** |
+| `timestamp_tag_name` | the tag holding span start time — drives segment/time
selection |
+| `span_id_tag_name` | the tag holding the span ID |
+
+- **Write** — `TraceService.Write` (stream of `{tags[], span (raw bytes),
version}`). Every span always goes to the span store; bound index rules
additionally feed the sidx.
+- **Query** — `TraceService.Query` (`time_range`, `criteria`, `order_by`,
`tag_projection`). Responses are always grouped **by trace ID**.
+
+Unlike Measure, **Trace has no mode flag**. The storage fork is driven
entirely by index rules and the query's `order_by`.
+
+### 5.2 Two engines side by side
+
+```mermaid
+flowchart TD
+ TR["Trace write (span)"] --> SPAN["span store (trace-ID-keyed columnar
part)"]
+ TR -->|per bound IndexRule| SIDX["sidx/<ruleName>/ — ordered
secondary index"]
+ Q{"query order_by?"} -->|absent / explicit IDs| SPAN
+ Q -->|set| SIDX
+ SIDX -->|ordered trace IDs| SPAN
+```
+
+**Span store part files** (`banyand/trace/part.go`) — notably different from
Measure/Stream:
+
+| File | Holds | Notes |
+| --- | --- | --- |
+| `metadata.json` | part stats **including** `minTimestamp`/`maxTimestamp` |
timestamps live **only** here (there is **no `timestamps.bin`**) |
+| `meta.bin` | index of primary blocks, keyed by **traceID** | record =
`EncodeBytes(traceID) + offset(8 BE) + size(8 BE)` |
+| `primary.bin` | `blockMetadata` per block | keyed by traceID; points at the
span chunk + per-tag columns |
+| `spans.bin` | the raw span payloads + span IDs | **opaque** application
bytes (one `[][]byte` block per traceID range), compressed via the shared
bytes-block (zstd) |
+| `<tag>.t` / `<tag>.tm` | per-tag value column + metadata | **flat** per-tag
files (not tag families); extensions `.t`/`.tm`, **not** `.tf`/`.tfm` |
+| `tag.type` | tag name → value type | one map per part (because
`blockMetadata` omits the value type, it is merged back at read time) |
+| `traceID.filter` | part-level **bloom filter over all traceIDs** | used to
prune parts on traceID lookup |
+| `smeta.bin` | optional series metadata | |
+
+```mermaid
+flowchart LR
+ META["meta.bin (keyed by traceID)"] --> PRIM["primary.bin (blockMetadata)"]
+ PRIM --> SPANS["spans.bin (opaque span blobs + span IDs)"]
+ PRIM --> T["<tag>.t (tag value column)"]
+ PRIM --> TM["<tag>.tm (tag metadata)"]
+ PART["part"] --> TT["tag.type (name → value type)"]
+ PART --> TF["traceID.filter (bloom over traceIDs)"]
+```
+
+**Block structure.** A block holds all spans of **one trace ID** (bounded by
`maxUncompressedSpanSize` = 2 MiB of opaque span bytes). All three index levels
(`meta.bin` → `primary.bin` → in-block) are sorted by traceID for binary search.
+
+**Block pruning is limited.** Trace's only block/part-pruning structures are
the part-level `traceID.filter` bloom and the embedded sidx. The per-tag `.tm`
records *do* have `min`/`max`/`filterBlock` fields, but the trace engine writes
them **empty** — there is **no tag-level block-skip filter** (unlike Stream's
`.tff` and sidx's `.tf`).
+
+**Conflict-tag rename on merge.** If the same tag name appears with different
value types across merged parts, the columns are kept separate by suffixing the
name with its type (`name#int`, `name#str`, …); read-time projection resolves
the suffixed columns.
+
+### 5.3 sidx — the ordered secondary index
+
+The "TREE" index rule (proto enum `TYPE_TREE`) is implemented by the **sidx**
store (`banyand/internal/sidx`), one instance per index rule, materialized
lazily under `shard-<N>/sidx/<ruleName>/`. sidx stores `(seriesID, int64
ordering-key, tags, data)` records ordered by the key — it holds the int64 sort
key (e.g. `duration`, start time) and the trace ID, but **not** the spans.
+
+**sidx part files:**
+
+| File | Holds |
+| --- | --- |
+| `manifest.json` | part metadata (authoritative): ID, key range, counts,
sizes |
+| `meta.bin` | index of primary blocks (40-byte records, zstd) |
+| `primary.bin` | `blockMetadata` per block (zstd primary blocks, capped at
**64 KiB** uncompressed — vs 128 KiB elsewhere) |
+| `keys.bin` | the int64 ordering keys, encoded but **not** block-compressed |
+| `data.bin` | user payload blobs (for trace: a control byte + trace ID), zstd
bytes-block |
+| `<tag>.td` / `.tm` / `.tf` | per-tag value column / metadata / **bloom
filter** (the `.tf` is written only for non-dictionary tags) |
+
+```mermaid
+flowchart LR
+ SM["meta.bin"] --> SP["primary.bin (blockMetadata)"]
+ SP --> SK["keys.bin (int64 ordering keys)"]
+ SP --> SD["data.bin (payload: control byte + traceID)"]
+ SP --> STM["<tag>.tm"]
+ STM --> STD["<tag>.td (values)"]
+ STM --> STF["<tag>.tf (bloom, if not dict-encoded)"]
+```
+
+A block holds one series ID's records over a contiguous key range, sorted by
key (caps: 8192 elements / 2 MiB).
+
+### 5.4 Query fork
+
+- **`order_by` absent (or explicit trace IDs given)** → hit the span store
directly (binary-search by traceID, gated by `traceID.filter`).
+- **`order_by` set** → stream **ordered** trace IDs from the named sidx, then
fetch the spans from the span store for those IDs.
+
+So an index rule on a `Trace` does not merely "add an index" — it instantiates
an entirely separate ordered storage engine, and `order_by` is the user-facing
switch between the two read paths.
+
+---
+
+## 6. Property
+
+### 6.1 The Property resource (API)
+
+`Property` presents a **mutable key/value** API, keyed by `group/name/id`,
with etcd-style `ModRevision`/`CreateRevision`. There are two proto messages
named `Property`: the **schema** (`database.v1.Property`, the tag-type contract
registered once) and the **data** (`property.v1.Property`, the actual values).
+
+- **Apply** (`PropertyService.Apply`) — upsert with `strategy` `MERGE`
(default, union of previous + current tags) or `REPLACE` (full overwrite).
+- **Delete** — soft delete (tombstone). `id` is optional (omit to delete all
ids under a name).
+- **Query** — `groups`, `name`, `ids`, `criteria`, `tag_projection`, `limit`,
`order_by`. **There is no time-range parameter** — Property is not a time
series.
+
+Storage options are on the **group**: only `shard_num` matters;
`segment_interval` and `ttl` on the group are **silently ignored** for
properties.
+
+### 6.2 Storage: a Bluge document store (not KV, not TSDB)
+
+Despite the KV-style API, there is no KV engine and no time-series engine.
Each `(group, shard)` is **one Bluge inverted index**; every property revision
is **one document**.
+
+```
+<property-root>/property/data/<group>/shard-<N>/
+├── <012x>.seg # ICE-v3 segment: documents (stored _source JSON + indexed
terms)
+├── <012x>.snp # snapshot manifest: live segments + per-segment DELETED
roaring drop-set
+└── bluge.pid # writer lock
+```
+
+There is **no segment (time) directory** — a single Bluge directory per shard
holds all revisions of all properties in that shard.
+
+**Document fields** (`banyand/property/db/shard.go`, the doc keyed by
`entity/ModRevision`):
+
+| Field | Stored? | Indexed? | Meaning |
+| --- | --- | --- | --- |
+| `_source` | ✅ | — | the whole property serialized as JSON (the value) |
+| `_sha_value` | ✅ | — | SHA-512 of source + delete-time (for repair) |
+| `_deleted` | ✅ (only when deleted) | — | delete-time nanos (tombstone) |
+| `_id` | ✅ | ✅ | the entity (`group/name/id`) |
+| `_timestamp` | ✅ | ✅ | = `ModRevision` |
+| `_entity_id`, `_group`, `_name` | — | ✅ | indexed identity terms |
+| per tag (`hash(tagKey)`) | — | ✅ | one indexed term per tag (all tags are
always indexed) |
+
+> The read-back projection is `{_id, _timestamp, _source, _deleted}`. Note
`_version` and `_series_id` are **not** written on the property path (unlike
the generic series-index path).
+
+```mermaid
+flowchart LR
+ A["Apply (id, tags)"] --> D["new Bluge doc keyed entity/ModRevision"]
+ D --> SEG["new .seg segment"]
+ A -.->|old revision| DROP["marked in .snp deleted bitmap"]
+ DEL["Delete"] --> TOMB["new doc with _deleted = now"]
+ MERGE["segment merge"] -->|after expire-delete-timeout| GC["physically
removes dropped docs"]
+```
+
+**Mutation = append + tombstone, not in-place edit:**
+
+- An update writes a brand-new document (new revision); the prior same-`_id`
document is added to a **per-segment DELETED roaring bitmap** recorded in
`.snp`. Reads `AndNot` the deleted set, so the old revision is masked, not
rewritten.
+- A delete writes a new document carrying `_deleted = deleteTime` (soft
delete).
+- **Physical removal happens only at Bluge segment merge**, and only
`property-expire-delete-timeout` (default 7 days) after the tombstone — so
"deleted" data lingers on disk until then. There is no per-property TTL.
+- Conflict resolution is last-writer-wins by `ModRevision` (the physical doc
ID is `entity/ModRevision`).
+
+**Compression:** stored fields (`_source`) are chunked (128 docs/chunk) and
compressed with **S2** by default (not zstd); postings are roaring bitmaps;
term dictionaries are FSTs.
+
+### 6.3 Anti-entropy repair
+
+Property has a gossip-based repair mechanism backed by a **custom Merkle
tree** (SHA-512; leaf per entity, xxhash slot buckets, root) persisted as
`state-tree.data` under a **separate** repair directory (`state.json`,
transient `state-append-<slot>.tmp`, `state-tree.data`). Peers reconcile root →
slot → leaf SHAs over a bidi gRPC stream and exchange full property protos for
mismatches. See [Property Background Repair](property-repair.md).
+
+---
+
+## 7. Encoding & compression primitives (shared)
+
+All columnar engines (Measure Mode A, Stream, Trace span store, sidx) share
the same low-level primitives in `pkg/encoding`. Understanding these once
explains every `*.bin`/`*.tf`/`*.t`/`*.td` column.
+
+### 7.1 The byte-block / length-list framing
+
+- **`compressBlock`** is the single compression chokepoint. A payload **< 128
bytes** is stored plain (`[type=0][1-byte len][raw]`); a payload **≥ 128
bytes** is zstd level-1 (`[type=1][varuint complen][zstd bytes]`).
+- **`EncodeUint64Block`** packs a uint64 list at an **adaptive bit width** —
it scans for the max and emits a 1-byte selector (8/16/32/64-bit) then
fixed-width **big-endian** values, then runs the result through `compressBlock`.
+- **`EncodeBytesBlock`** serializes a `[][]byte` as `[uint64-block of
lengths][compressBlock of concatenated bytes]`. Lengths use **nil-encoding
offset-by-one**: a `nil` entry encodes as `0`, a present entry as `len+1` (so
an empty-but-present `[]byte` encodes as `1`).
+
+### 7.2 Numeric column encoding
+
+- **int64 columns** (and timestamps, sidx keys): `Int64ListToBytes` chooses
per run from `Const` / `DeltaConst` / `Delta` / `DeltaOfDelta`, with deltas as
**zigzag varint**; a `firstValue` is stored alongside. There is **no zstd** at
this layer.
+- **float64 columns**: converted to an int64 mantissa + an int16 exponent
(`Float64ListToDecimalIntList`), then int64-delta encoded.
+- **versions** (Measure) use a parallel `WithVersion` encode-type variant.
+
+### 7.3 Non-numeric (string/binary/array) column encoding
+
+- **Dictionary** when ≤ 256 distinct values: values stored as a bytes-block,
indices RLE-then-bit-packed. The dictionary itself doubles as an exact
membership filter.
+- otherwise **plain** `EncodeBytesBlock`.
+- Array tags are `|`-delimited (with `\` escaping); int64 arrays are raw
8-byte concatenations.
+
+### 7.4 Where zstd is applied
+
+zstd level-1 is applied to: the whole `meta.bin`, each ~128 KiB primary block
in `primary.bin`, and any byte payload ≥ 128 bytes inside a column. Timestamps,
element IDs, and sidx keys are **not** zstd'd (delta/zigzag only).
+
+### 7.5 Two encoding footguns (do not be misled)
+
+- **`ENCODING_METHOD_GORILLA` is a schema hint, not Gorilla XOR.** The
`FieldSpec.encoding_method = GORILLA` enum is set in schemas, but the columnar
engine encodes fields with the delta/dictionary scheme above. The actual
Gorilla XOR encoder (`pkg/encoding/xor.go`) and the
`SeriesEncoder`/`SeriesDecoder` interfaces are **dead code** — no engine wires
them in. Do not document them as live primitives.
+- **Per-field `compression_method = ZSTD` is not a per-field setting.** zstd
is applied generically (§7.4), driven by size thresholds, not by the schema
enum.
+
+---
+
+## 8. Distributed: how parts move between nodes
+
+In cluster mode, parts are shipped to replica/data nodes by a **chunked-sync**
protocol (`banyand/queue/pub|sub/chunked_sync.go`). The on-the-wire form is
**not** a byte-for-byte copy of the directory:
+
+- **Logical file model.** Each part is sent as a list of `FileInfo{name,
offset, size}` where `name` is a *logical* identifier decoupled from the
on-disk filename: `meta`, `primary`, `timestamps`, `fv`, `t:<tag>`, `tm:<tag>`,
`tf:<tag>`, `tff:<tag>`. The receiver maps each logical name back to the
concrete file (`meta` → `meta.bin`, `t:foo` → `foo.t`, …). So the streamed file
list differs from the literal directory listing.
+- **Chunk framing.** Data is split into ~1 MiB chunks with a monotonic
`chunk_index`, a per-chunk **CRC32 (IEEE)** checksum, and a `VersionInfo` (API
+ file-format version) validated on every chunk. A single logical file can span
multiple chunks; the receiver appends per-chunk slices in order. (Note:
`FileInfo.offset` is **chunk-relative** in practice; the proto comment saying
"within the part" is stale.)
+- **`meta` is regenerated, not copied.** The live syncer rebuilds the `meta`
bytes from the in-memory `primaryBlockMetadata` (marshal + zstd), producing
bytes equivalent to `meta.bin` rather than reading the file. (A separate
verbatim path, `CreatePartFileReaderFromPath`, exists for migration/copy flows.)
+- **`metadata.json` is not shipped.** It is reconstructed on the receiver from
the per-part `PartInfo` numeric fields. By contrast `traceID.filter` and
`tag.type` *are* streamed (as logical files) but flushed at `FinishSync`.
+
+### 8.1 Failed-parts handling
+
+If a part still fails to sync after retries (3 attempts, exponential backoff),
it is preserved under `failed-parts/` as **hard links** (no byte copy) at
`<root>/failed-parts/<016x>_<partType>/` (partType `core` or a sidx name). The
directory is size-capped (`--failed-parts-max-size-percent`, default 10%) with
oldest-first eviction, and is explicitly **skipped** when loading parts (so it
is never mistaken for a live part or deleted as an unparseable epoch).
+
+---
+
+## 9. Quick reference — files by engine
+
+| Engine | Per-unit directory | Key files |
+| --- | --- | --- |
+| Measure (columnar) | `seg-…/shard-N/<016x>/` | `metadata.json` · `meta.bin`
· `primary.bin` · `timestamps.bin` (ts+version) · `fv.bin` · `<fam>.tf` ·
`<fam>.tfm` · `smeta.bin?` |
+| Stream | `seg-…/shard-N/<016x>/` + `shard-N/idx/` | `metadata.json` ·
`meta.bin` · `primary.bin` · `timestamps.bin` (ts+elementID) · `<fam>.tf` ·
`<fam>.tfm` · `<fam>.tff` · `smeta.bin?` |
+| Trace (span store) | `seg-…/shard-N/<016x>/` | `metadata.json` · `meta.bin`
· `primary.bin` · `spans.bin` · `<tag>.t` · `<tag>.tm` · `tag.type` ·
`traceID.filter` · `smeta.bin?` |
+| sidx (trace 2°) | `seg-…/shard-N/sidx/<rule>/<016x>/` | `manifest.json` ·
`meta.bin` · `primary.bin` · `keys.bin` · `data.bin` · `<tag>.td` · `<tag>.tm`
· `<tag>.tf` |
+| Measure (index-mode) | `seg-…/sidx/` (segment series index) | Bluge
`<012x>.seg` · `<012x>.snp` |
+| Series index (all TSDB) | `seg-…/sidx/` | Bluge `<012x>.seg` · `<012x>.snp` |
+| Property | `…/property/data/<group>/shard-N/` | Bluge `<012x>.seg` ·
`<012x>.snp` · `bluge.pid` |
+
+---
+
+## See also
+
+- [TSDB](tsdb.md) — the columnar TSDB engine concepts
(segment/shard/part/block, snapshot MVCC, write/read paths).
+- [Data Model](data-model.md) — the logical/API model (groups, resources,
index rules).
+- [Data Rotation](rotation.md) — segment rotation and retention.
+- [Property Background Repair](property-repair.md) — the gossip + Merkle
anti-entropy detail.
diff --git a/docs/concept/tsdb.md b/docs/concept/tsdb.md
index 8d2b87b8e..e75fee8af 100644
--- a/docs/concept/tsdb.md
+++ b/docs/concept/tsdb.md
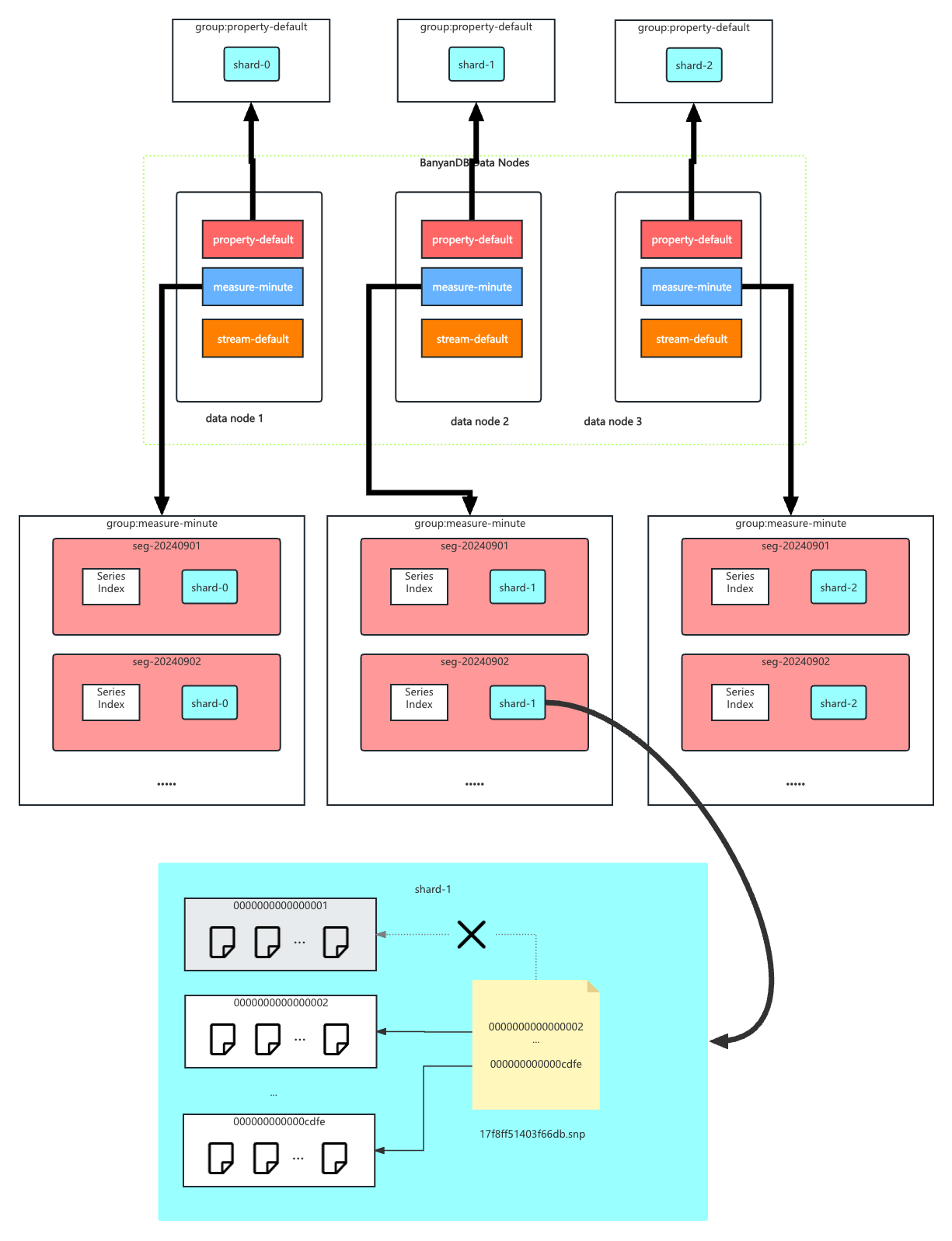
@@ -6,112 +6,185 @@ In TSDB, the data in a group is partitioned based on the
time range of the data.
More than the time series data model, TSDB also provides a schema-less and
non-time-series data type, `Property`. The `Property` data type is used to
store the document which contains several tags. The `Property` data is an
independent group that contains only `shard`s, without `segment_interval`,
`ttl`, or other time-series-related features.
-
+> This page describes the TSDB engine concepts. For the on-disk file format of
every resource organized **from the API perspective** (including `Property`,
measure index-mode, the shared encoding primitives, and the distributed sync
wire format), see [Storage & File Format](storage-and-format.md).
+
+The on-disk hierarchy is `group → segment → shard → part`:
+
+```mermaid
+flowchart TD
+ G["group/"] --> SEG["seg-<date>/ (time segment)"]
+ SEG --> SI["sidx/ — series index (Bluge)"]
+ SEG --> SH["shard-<N>/"]
+ SH --> P["<016x>/ — part (immutable)"]
+ SH --> SNP["<016x>.snp — snapshot manifest"]
+ P --> COL["columnar files (meta.bin, primary.bin, …)"]
+```
+
+For `Property`, there is no time segment: a group contains shards directly,
each shard being a single inverted index (see [Storage & File
Format](storage-and-format.md#6-property)).
## Segment
-In each segment, the data is spread into shards based on `entity`. The series
index is stored in the segment, which is used to locate the data in the shard.
+In each segment, the data is spread into shards based on `entity`. The series
index (the per-segment `sidx/` directory, a Bluge inverted index) is stored in
the segment and is used to locate the data in the shard.
+
+A segment directory is named `seg-<suffix>`, where the suffix is the
segment-start time formatted as `YYYYMMDDHH` (hour granularity) or `YYYYMMDD`
(day granularity), selected by the group's `segment_interval` unit.
-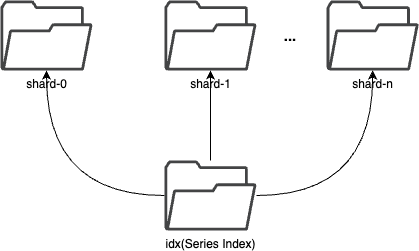
+```mermaid
+flowchart TD
+ SEG["seg-20240901/"] --> SI["sidx/ — series index"]
+ SEG --> S0["shard-0/"]
+ SEG --> S1["shard-1/"]
+ SEG --> SN["shard-n/"]
+```
## Shard
Each shard is assigned to a specific set of storage nodes, and those nodes
store and process the data within that shard. This allows BanyanDB to scale
horizontally by adding more storage nodes to the cluster as needed.
-In `Stream`, `Measure` or `Trace`, Each shard is composed of multiple
[parts](#Part). Whenever SkyWalking sends a batch of data, BanyanDB writes this
batch of data into a new part. For data of the `Stream` type, the inverted
indexes generated based on the indexing rules are also stored in the segment.
For data of the `Trace` type, BanyanDB maintains a tree index for `TREE` type
index rules. The tree index stores data with user-controlled int64 ordering
keys, enabling efficient sorted res [...]
+In `Stream`, `Measure` or `Trace`, each shard is composed of multiple
[parts](#Part). Whenever SkyWalking sends a batch of data, BanyanDB writes this
batch of data into a new part.
-Since BanyanDB adopts a snapshot approach for data read and write operations,
the segment also needs to maintain additional snapshot information to record
the validity of the parts. The shard contains `xxxxxxx.snp` to record the
validity of parts. In the chart, `0000000000000001` is removed from the
snapshot file, which means the part is invalid. It will be cleaned up in the
next flush or merge operation.
+- For data of the `Stream` type, an element-level inverted index built from
`TYPE_INVERTED` index rules is stored in the shard's `idx/` directory.
+- For data of the `Trace` type, BanyanDB maintains an ordered secondary index
(`sidx`) for `TREE` type index rules under the shard's `sidx/` directory. The
secondary index stores data with user-controlled int64 ordering keys, enabling
efficient sorted result retrieval. (Note: this shard-level `sidx/` is distinct
from the segment-level `sidx/` series index above — same name, different depth
and purpose.)
-
+Since BanyanDB adopts a snapshot approach for data read and write operations,
the shard maintains snapshot information to record the validity of the parts.
The shard contains `<016x>.snp` (JSON array of live part directory names) to
record which parts are valid. In the chart, `000…001` is absent from the
snapshot file, which means the part is invalid; it will be cleaned up in the
next flush or merge operation.
-In `Property`, the shard is implemented by the [inverted
index](#Inverted-Index). Users could filter data by the tag.
+```mermaid
+flowchart TD
+ SH["shard-0/"] --> P1["000…001/ (part — dropped)"]:::dead
+ SH --> P2["000…002/ (part)"]
+ SH --> PN["000…0cdfe/ (part)"]
+ SH --> SNP["000…0cdfe.snp (lists 002 … 0cdfe)"]
+ SH --> IDX["idx/ — stream element index (stream only)"]
+ classDef dead fill:#fdd,stroke:#900,stroke-dasharray:4
+```
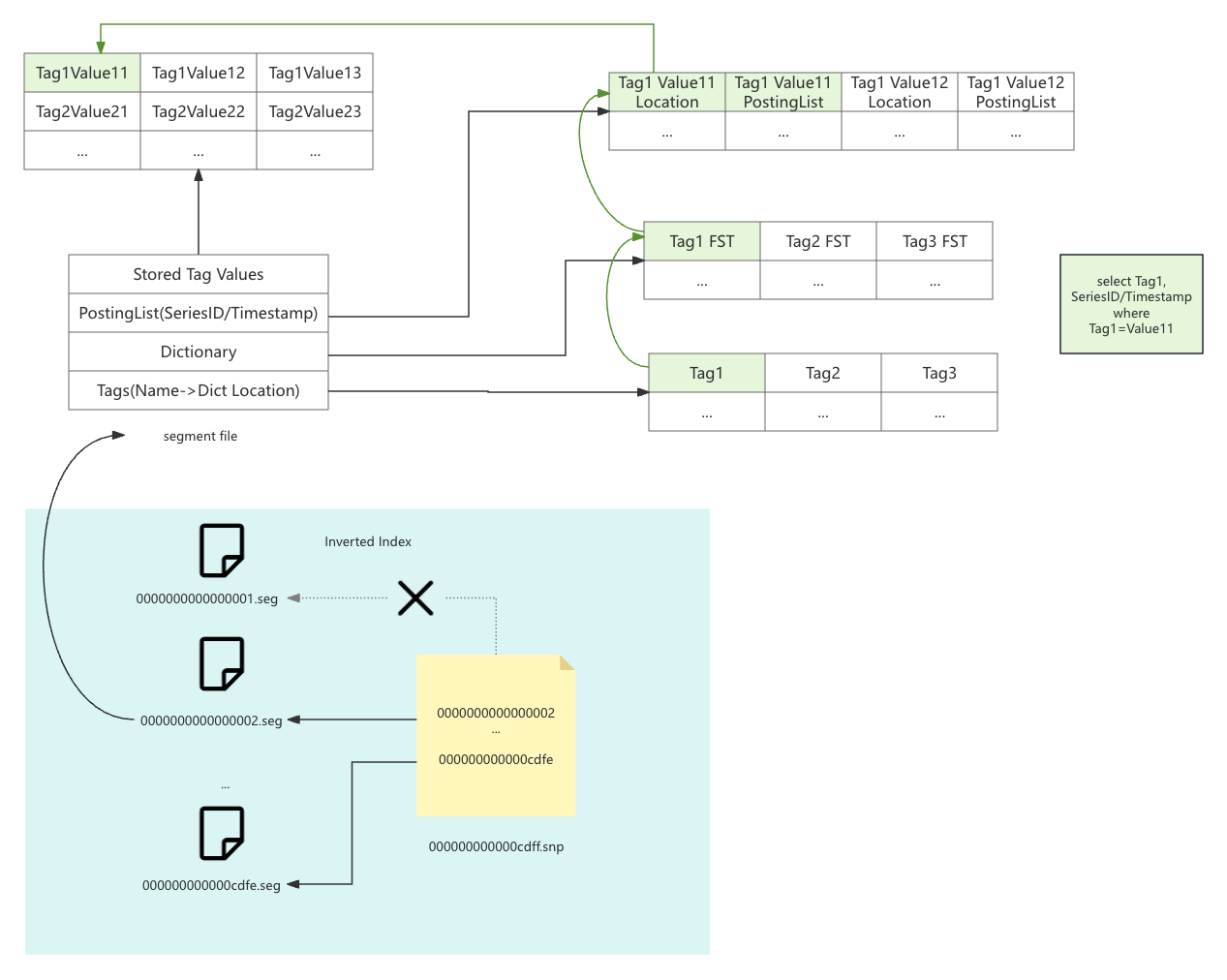
-## Inverted Index
+In `Property`, the shard is implemented directly by an [inverted
index](#Inverted-Index). Users can filter data by tag.
-The inverted index is used to locate the data in the shard. For `measure`, it
is a mapping from the term to the series id. For `stream`, it is a mapping from
the term to the timestamp.
+## Inverted Index
-## Tree Index
+The inverted index locates data within a segment/shard. It is used in several
places:
-The tree index is a high-performance indexing system used by `Trace` for
`TREE` type index rules. The tree index stores data with user-controlled int64
ordering keys, enabling efficient sorted result retrieval.
+- the per-segment **series index** (`seg-…/sidx/`) — for `Measure`, `Stream`,
and `Trace`, it maps entity/tag terms to the **series id**;
+- the per-shard **element index** (`Stream`'s `idx/`) — it maps indexed-tag
terms to **element ids** (with a parallel timestamp posting list);
+- the **index-mode `Measure`** store and the entire **`Property`** store (see
[Storage & File Format](storage-and-format.md)).
-Each `TREE` type index rule bound to a trace creates a separate tree index
instance identified by the index rule name. During writes, the database engine
extracts the int64 value from the indexed tag and stores it as the ordering key
along with the trace data. During queries, the tree index supports streaming
result retrieval sorted by the ordering key, cross-shard ordered merging, and
key range filtering.
+The inverted index uses the Bluge/ICE segment format. It stores a `snapshot`
file `<012x>.snp` to record the validity of segments; a segment id absent from
the snapshot is invalid and will be cleaned up at the next flush or merge.
-The tree index follows the same part-based storage model as the main data
store, with memory parts flushed to disk parts and periodic merge operations to
maintain performance.
+A segment file `<012x>.seg` contains the inverted index data, with these
logical parts:
-For `property`, all the content of a property is stored as a `_source` field
in the inverted index. `group`, `name`, `id` and `tags` are only indexed in the
inverted index.
+- **Tags**: the mapping from a tag name to its dictionary location.
+- **Dictionary**: an FST (Finite State Transducer) dictionary mapping a tag
value to its posting list.
+- **Posting List**: the mapping from a tag value to the series id / element id
(and, when stored, a location for the stored value). Posting lists are roaring
bitmaps.
+- **Stored Value**: optionally stored field values. (For `Property`,
individual tags are *not* stored here — only the whole-document `_source` JSON
is stored; tags are indexed-only.)
-The inverted index stores `snapshot` file `xxxxxxx.snp` to record the validity
of segments. In the chart, `0000000000000001.seg` is removed from the snapshot
file, which means the segment is invalid. It will be cleaned up in the next
flush or merge operation.
+```mermaid
+flowchart LR
+ Q["query Tag1 = Value1"] --> TAGS["Tags (name → dict location)"]
+ TAGS --> DICT["Dictionary (FST: value → postings)"]
+ DICT --> POST["Posting List (roaring bitmap of doc ids)"]
+ POST --> STORE["Stored Value (optional)"]
+ SEG[".seg segments + .snp snapshot"]
+```
-The segment file `xxxxxxxx.seg` contains the inverted index data. It includes
four parts:
+## Tree Index
-- **Tags**: The mapping from the tag name to the dictionary location.
-- **Dictionary**: It's a FST(Finite State Transducer) dictionary to map tag
value to the posting list.
-- **Posting List**: The mapping from the tag value to the series id or
timestamp. It also contains a location info to the stored tag value.
-- **Stored Tag Value**: The stored tag value.
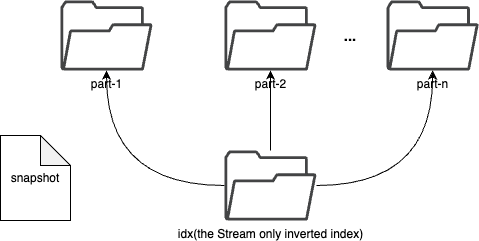
+The "tree index" (proto enum `TYPE_TREE`) is the high-performance ordered
index used by `Trace`. It is implemented by the **sidx** (secondary index)
store, not a literal tree structure; it stores records ordered by a
user-controlled int64 key, enabling efficient sorted retrieval.
-
+Each `TREE` index rule bound to a trace creates a separate sidx instance,
identified by the index rule name, under `shard-<N>/sidx/<ruleName>/`. During
writes, the engine extracts the int64 value from the indexed tag (e.g.
`duration`, start time) and stores it as the ordering key alongside the trace
id. During queries, sidx supports streaming retrieval sorted by the key,
cross-shard ordered merging, and key-range filtering.
-If you want to search `Tag1=Value1`, the index will first search the `Tags`
part to find the dictionary location of `Tag1`. Then, it will search the
`Dictionary` part to find the posting list location of `Value1`. Finally, it
will search the `Posting List` part to find the series id or timestamp. If you
want to fetch the tag value, it will search the `Stored Tag Value` part to find
the tag value.
+sidx follows the same part-based storage model as the main data store (memory
parts flushed to disk parts, with periodic merges). Its on-disk files
(`keys.bin`, `data.bin`, per-tag `.td`/`.tm`/`.tf`, etc.) are detailed in
[Storage & File
Format](storage-and-format.md#53-sidx--the-ordered-secondary-index).
## Part
-Within a part, data is split into multiple files in a columnar manner. The
timestamps are stored in the `timestamps.bin` file, tags are organized in
persistent tag families as various files with the `.tf` suffix, and fields are
stored separately in the `fields.bin` file.
+Within a part, data is split into multiple files in a **columnar** manner. The
exact set of files depends on the engine:
+
+- **Measure**: timestamps (with versions) in `timestamps.bin`; field-value
columns in `fv.bin`; tags grouped into tag families, with values in
`<tagFamily>.tf` and the column directory in `<tagFamily>.tfm`.
+- **Stream**: same as Measure but with **no `fv.bin`** (streams have no
fields); `timestamps.bin` holds timestamps **+ element ids**; each tag family
adds a `<tagFamily>.tff` filter file (bloom filters for `SKIPPING`-indexed
tags).
+- **Trace**: a different layout — opaque span payloads in `spans.bin`, **no
`timestamps.bin`** (timestamps live in `metadata.json`), flat per-tag files
`<tag>.t` / `<tag>.tm` (not tag families), plus `tag.type` and a part-level
`traceID.filter` bloom. See [Storage & File
Format](storage-and-format.md#5-trace).
+
+Each part also maintains metadata files:
+
+- `metadata.json` — descriptive information for the part
(compressed/uncompressed sizes, total count, block count, min/max timestamp).
The part id is the directory name, not stored inside the JSON.
+- `meta.bin` — a skipping index file that is the entry point for the part; it
indexes the `primary.bin` file. It is a zstd-compressed stream of fixed-size
`primaryBlockMetadata` records.
+- `primary.bin` — the index of each [block](#Block). Through it, the data
files (and the tag-family metadata files ending with `.tfm`) are located. It is
a sequence of independently zstd-compressed "primary blocks".
+- `smeta.bin` (optional) — compact series metadata (e.g. SeriesID →
EntityValues), used for sync/recovery and offline inspection tools. It may be
absent on older parts.
+
+The diagrams below show the Measure and Stream part fan-out (`meta.bin →
primary.bin → data columns`):
+
+```mermaid
+flowchart LR
+ subgraph Measure part
+ MM["meta.bin"] --> MP["primary.bin"]
+ MP --> MT["timestamps.bin (ts + version)"]
+ MP --> MF["fv.bin (field columns)"]
+ MP --> MTFM["<family>.tfm"]
+ MTFM --> MTF["<family>.tf"]
+ MJ["metadata.json"]
+ MS["smeta.bin (optional)"]
+ end
+```
+
+```mermaid
+flowchart LR
+ subgraph Stream part
+ SM["meta.bin"] --> SP["primary.bin"]
+ SP --> ST["timestamps.bin (ts + elementID)"]
+ SP --> STFM["<family>.tfm"]
+ STFM --> STF["<family>.tf"]
+ STFM --> STFF["<family>.tff (tag filters)"]
+ SJ["metadata.json"]
+ SS["smeta.bin (optional)"]
+ end
+```
-In addition, each part maintains several metadata files. Among them,
`metadata.json` is the metadata file for the part, storing descriptive
information, such as start and end times, part size, etc.
-
-The `meta.bin` is a skipping index file that serves as the entry file for the
entire part, helping to index the `primary.bin` file.
-
-The `primary.bin` file contains the index of each [block](#Block). Through it,
the actual data files or the tagFamily metadata files ending with `.tfm` can be
indexed, which in turn helps to locate the data in blocks.
-
-The optional `smeta.bin` file persists compact series metadata (e.g., SeriesID
to EntityValues mappings). It is primarily designed for operational debugging
and offline inspection tools.
+## Block
-Notably, for data of the `Stream` type, since there are no field columns, the
`fields.bin` file does not exist, while the rest of the structure is entirely
consistent with the `Measure` type.
+Each block holds data with the same series ID (for `Trace`, the grouping key
is the **trace id** instead). A block is the minimal unit of TSDB and contains
several rows of data; because of the column-based design, a single block is
spread across several files. Blocks are globally ordered by `(seriesID,
minTimestamp)`.
-
-
+Block size is bounded by configurable caps (enforced by splitting): for
Measure, by both data volume (2 MiB uncompressed) and row count (8192 rows);
for Stream, by data volume only; for Trace, by opaque span volume (2 MiB).
Separate 8 MiB caps on per-block value/metadata regions are hard invariants
(enforced by panic). See [Storage & File
Format](storage-and-format.md#33-mode-a--normal-columnar-index_mode--false) for
the full table.
-## Block
+In Measure's `timestamps.bin`, a `version` is stored next to each timestamp.
The version deduplicates rows that share an identical timestamp — only the
latest (highest-version) row is returned to the user.
-Each block holds data with the same series ID.
-The max size of the measure block is controlled by data volume and the number
of rows. Meanwhile, the max size of the stream block is controlled by data
volume.
-The diagram below shows the detailed fields within each block. The block is
the minimal unit of TSDB, which contains several rows of data. Due to the
column-based design, each block is spread over several files.
+The two-level index and per-block record layout:
-In measure's timestamp file, there are version fields to record the version of
the data. The version field is used to deduplicate. It determine the latest
data when the data's timestamp are identical. Only the latest data will be
returned to the user.
+| `meta.bin` record (`primaryBlockMetadata`, 40 bytes, zstd stream) | bytes |
+| --- | --- |
+| seriesID | 8 (big-endian) |
+| minTimestamp / maxTimestamp | 8 + 8 |
+| offset / size (into `primary.bin`) | 8 + 8 |
-
+A `primary.bin` "primary block" (zstd-compressed, ~128 KiB uncompressed) is a
run of `blockMetadata` records, each carrying the seriesID, row count, the
timestamps location, and per-column / per-tag-family `(offset, size)` pointers
into `timestamps.bin`, `fv.bin`, and the `.tfm`/`.tf` files.
-Unlike the measure, there are element ids in the stream's timestamp file. The
element id is used to identify the data of the same series. The data with the
same timestamp but different element id will both be stored in the TSDB. This
introduces a series of new files, named `*.tff`, which contain tag filter
information for each tag. As of 0.10.0, dictionary-encoded tags no longer use
Bloom filters, replacing them with a more efficient dictionary-based filter.
Additionally, min/max fields [...]
+```mermaid
+flowchart LR
+ META["meta.bin: [seriesID,minTs,maxTs,offset,size] …"] -->
PB["primary.bin: zstd primary block"]
+ PB --> BM["blockMetadata: seriesID, count, tsMeta, fieldMeta, tag
(offset,size) …"]
+ BM --> DATA["timestamps.bin / fv.bin / <family>.tf"]
+```
-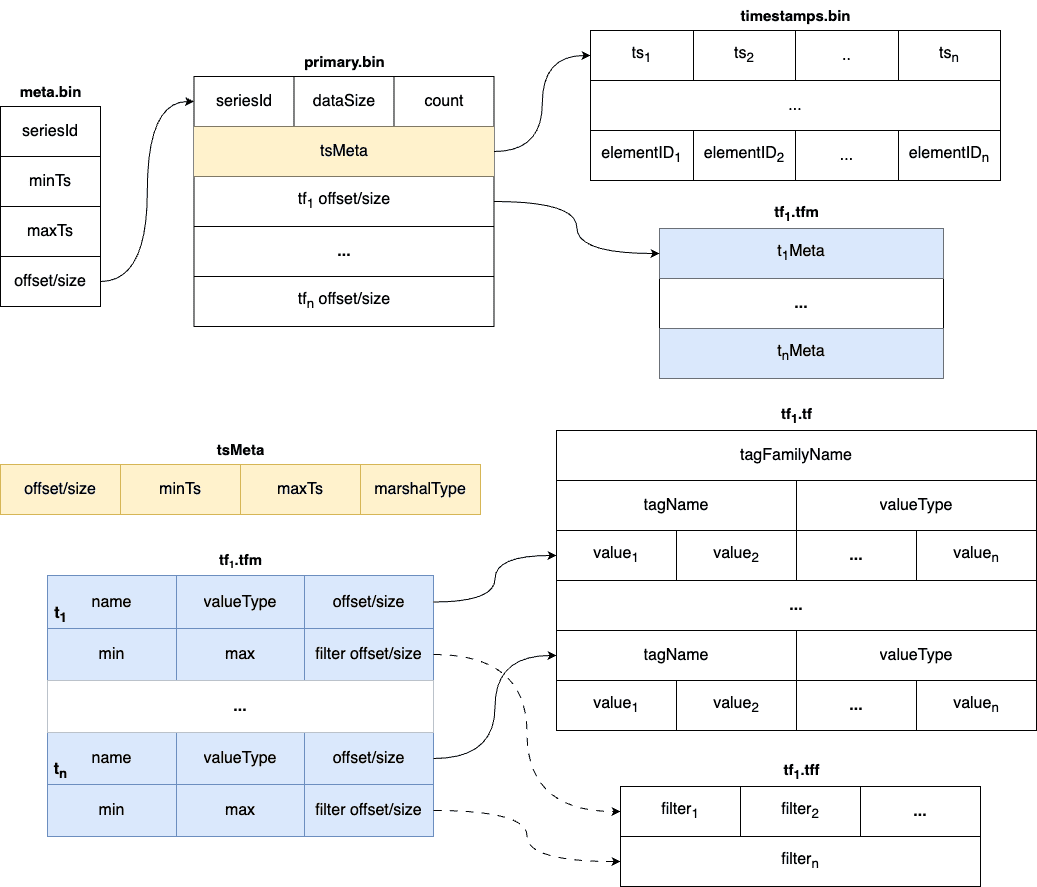
+Unlike Measure, Stream's `timestamps.bin` stores **element ids** (not
versions); rows with the same timestamp but different element id are both
stored (no dedup). Stream's `.tfm` records additionally carry per-tag
`min`/`max` (for Int64 tags) and a pointer to the `.tff` filter block; as of
0.10.0, dictionary-encoded tags use the dictionary itself as an exact filter
rather than a bloom filter.
## Write Path
-The write path of TSDB begins when time-series data is ingested into the
system. TSDB will consult the schema repository to check if the group exists,
and if it does, then it will hash the SeriesID to determine which shard it
belongs to.
+The write path of TSDB begins when time-series data is ingested into the
system. TSDB consults the schema repository to check that the group exists,
then hashes the SeriesID (or the configured sharding key) to determine which
shard the data belongs to.
-Each shard in TSDB is responsible for storing a subset of the time-series
data. The shard also holds an in-memory index allowing fast lookups of
time-series data.
+Each shard is responsible for storing a subset of the data and holds an
in-memory index for fast lookups.
-When a shard receives a write request, the data is written to the buffer as a
memory part. Meanwhile, the series index and inverted index will also be
updated. The worker in the background periodically flushes data, writing the
memory part to the disk. After the flush operation is completed, it triggers a
merge operation to combine the parts and remove invalid data.
+When a shard receives a write request, the data is written to a buffer as a
memory part; the series index (and, for indexed tags, the inverted index) is
updated as well. A background worker periodically flushes the memory part to
disk. After a flush completes, it triggers a merge operation to combine parts
and remove invalid data.
-Whenever a new memory part is generated, or when a flush or merge operation is
triggered, they initiate an update of the snapshot and delete outdated
snapshots. The parts in a persistent snapshot could be accessible to the reader.
+Whenever a new memory part is generated, or a flush or merge completes, the
snapshot is updated and outdated snapshots are deleted. Only the parts
referenced by a persistent snapshot are visible to readers.
## Read Path
-The read path in TSDB retrieves time-series data from disk or memory, and
returns it to the query engine. The read path comprises several components: the
buffer and parts. The following is a high-level overview of how these
components work together to retrieve time-series data in TSDB.
+The read path retrieves data from disk or memory and returns it to the query
engine, working across the buffer (memory parts) and on-disk parts.
-The first step in the read path is to perform an index lookup to determine
which parts contain the desired time range. The index contains metadata about
each data part, including its start and end time.
+The first step is an index lookup to determine which parts cover the requested
time range; each part's `metadata.json` records its start and end time. The
buffer (memory parts) is checked first; if the data is not present there, the
read path proceeds to the on-disk parts. Because of the columnar layout,
satisfying a query may require reading several data files per part.
### Snapshot Coordination
-BanyanDB uses a shared snapshot coordination mechanism to ensure atomic
snapshot transitions across the trace and sidx (skipping index) engines. When a
snapshot transition occurs, both engines coordinate to produce a consistent
view of the data. This prevents situations where the trace engine and the sidx
engine have different views of the same data.
-
-This coordination is automatic and requires no operator configuration.
+BanyanDB uses a shared snapshot coordination mechanism to ensure atomic
snapshot transitions across the trace engine and the sidx (secondary index)
engine. When a snapshot transition occurs, both engines coordinate to produce a
consistent view of the data, preventing situations where the trace engine and
the sidx engine have different views of the same data. This coordination is
automatic and requires no operator configuration.
### Series Metadata Persistence
In cluster mode, liaison nodes persist series metadata to disk. This improves
recovery after restarts by allowing the liaison to rebuild its series mapping
without waiting for data from other nodes. The persisted metadata includes the
mapping between series IDs and entity values.
The dump tool can analyze series metadata files (`smeta.bin`) stored in each
part directory for debugging purposes. See [Disk
Management](../operation/disk-management.md#dump-tool-series-metadata) for
details.
-
-If the requested data is present in the buffer (i.e., it has been recently
written but not yet persisted to disk), the buffer is checked to see if the
data can be returned directly from memory. The read path determines which
memory part(s) contain the requested time range. If the data is not present in
the buffer, the read path proceeds to the next step.
-
-The next step in the read path is to look up the appropriate parts on disk.
Files are the on-disk representation of blocks and are organized by shard and
time range. The read path determines which parts contain the requested time
range and reads the appropriate blocks from the disk. Due to the column-based
storage design, it may be necessary to read multiple data files.
diff --git a/docs/menu.yml b/docs/menu.yml
index 837de71f7..ba39c7eac 100644
--- a/docs/menu.yml
+++ b/docs/menu.yml
@@ -183,6 +183,8 @@ catalog:
path: "/operation/benchmark/benchmark-hybrid"
- name: "File Format"
catalog:
+ - name: "Storage & File Format (by API resource)"
+ path: "/concept/storage-and-format"
- name: "v1.3.0"
path: "/concept/tsdb"
- name: "Concepts"
diff --git a/docs/operation/disk-management.md
b/docs/operation/disk-management.md
index 9d09ef455..86006b0ba 100644
--- a/docs/operation/disk-management.md
+++ b/docs/operation/disk-management.md
@@ -49,13 +49,13 @@ Liaison servers use the disk usage flags to manage their
write queue and prevent
#### Inspecting the Liaison write queue on disk
Liaison nodes persist the write queue to disk, so pending data survives
restarts and can be inspected during incident response.
-The on-disk layout under each `*-data-path` mirrors the TSDB structure (group
→ shard → segment → part). See [TSDB](../concept/tsdb.md) for the segment and
shard concepts.
+The on-disk layout under each `*-data-path` mirrors the TSDB structure (group
→ segment → shard → part). See [TSDB](../concept/tsdb.md) for the segment and
shard concepts.
**Where series metadata is stored (`smeta.bin`)**
Starting from 0.10, each persisted part for **measure**, **stream**, and
**trace** may include an optional `smeta.bin` file in the part directory:
-- **Location**: `.../<group>/shard-<id>/<segment>/.../<partID-hex>/smeta.bin`
+- **Location**: `.../<group>/<segment>/shard-<id>/<partID-hex>/smeta.bin`
- **Purpose**: `smeta.bin` stores a compact mapping from `SeriesID` to the
series `EntityValues` that appear in that part. This makes it possible to
identify which series a queued (or malformed) part belongs to even when
segment-level indexes are missing or hard to use during debugging.
- **Backward compatibility**: older parts may not contain `smeta.bin`, and
tools should handle its absence gracefully.
@@ -67,9 +67,9 @@ Examples:
```sh
# If you have the dump binary in PATH.
-dump measure --shard-path <measure-data-path>/<group>/shard-0 --segment-path
<measure-data-path>/<group>/shard-0/<segment>
-dump stream --shard-path <stream-data-path>/<group>/shard-0 --segment-path
<stream-data-path>/<group>/shard-0/<segment>
-dump trace --shard-path <trace-data-path>/<group>/shard-0 --segment-path
<trace-data-path>/<group>/shard-0/<segment>
+dump measure --shard-path <measure-data-path>/<group>/<segment>/shard-0
--segment-path <measure-data-path>/<group>/<segment>
+dump stream --shard-path <stream-data-path>/<group>/<segment>/shard-0
--segment-path <stream-data-path>/<group>/<segment>
+dump trace --shard-path <trace-data-path>/<group>/<segment>/shard-0
--segment-path <trace-data-path>/<group>/<segment>
# Or run it from source.
go run ./banyand/cmd/dump measure --shard-path <...> --segment-path <...>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}